
Guofei Gu1, Roberto Perdisci2, Junjie Zhang1, and Wenke
Lee1
1College of Computing, Georgia Institute of Technology
2Damballa, Inc. Atlanta, GA 30308, USA
{guofei,jjzhang,wenke}@cc.gatech.edu, perdisci@damballa.com
Botnets are becoming one of the most serious threats to Internet security. A botnet is a network of compromised machines under the influence of malware (bot) code. The botnet is commandeered by a ``botmaster'' and utilized as ``resource'' or ``platform'' for attacks such as distributed denial-of-service (DDoS) attacks, and fraudulent activities such as spam, phishing, identity theft, and information exfiltration.
In order for a botmaster to command a botnet, there needs to be a command and control (C&C) channel through which bots receive commands and coordinate attacks and fraudulent activities. The C&C channel is the means by which individual bots form a botnet. Centralized C&C structures using the Internet Relay Chat (IRC) protocol have been utilized by botmasters for a long time. In this architecture, each bot logs into an IRC channel, and seeks commands from the botmaster. Even today, many botnets are still designed this way. Quite a few botnets, though, have begun to use other protocols such as HTTP [24,8,14,39], probably because HTTP-based C&C communications are more stealthy given that Web traffic is generally allowed in most networks. Although centralized C&C structures are effective, they suffer from the single-point-of-failure problem. For example, if the IRC channel (or the Web server) is taken down due to detection and response efforts, the botnet loses its C&C structure and becomes a collection of isolated compromised machines. Recently, botmasters began using peer-to-peer (P2P) communication to avoid this weakness. For example, Nugache [28] and Storm worm [18,23] (a.k.a. Peacomm) are two representative P2P botnets. Storm, in particular, distinguishes itself as having infected a large number of computers on the Internet and effectively becoming one of the ``world's top super-computers'' [27] for the botmasters.
Researchers have proposed a few approaches [7,17,19,20,26,29,35,40] to detect the existence of botnets in monitored networks. Almost all of these approaches are designed for detecting botnets that use IRC or HTTP based C&C [7,17,26,29,40]. For example, Rishi [17] is designed to detect IRC botnets using known IRC bot nickname patterns as signatures. In [26,40], network flows are clustered and classified according to IRC-like traffic patterns. Another more recent system, BotSniffer, [20] is designed mainly for detecting C&C activities with centralized servers (with protocols such as IRC and HTTP1). One exception is perhaps BotHunter [19], which is capable of detecting bots regardless of the C&C structure and network protocol as long as the bot behavior follows a pre-defined infection life cycle dialog model.
However, botnets are evolving and can be quite flexible. We have witnessed that the protocols used for C&C evolved from IRC to others (e.g., HTTP [24,8,14,39]), and the structure moved from centralized to distributed (e.g., using P2P [28,18]). Furthermore, a botnet during its lifetime can also change its C&C server address frequently, e.g., using fast-flux service networks [22]. Thus, the aforementioned detection approaches designed for IRC or HTTP based botnets may become ineffective against the recent/new botnets. Even BotHunter may fail as soon as botnets change their infection model(s).
Therefore, we need to develop a next generation botnet detection system, which should be independent of the C&C protocol, structure, and infection model of botnets, and be resilient to the change of C&C server addresses. In addition, it should require no a priori knowledge of specific botnets (such as captured bot binaries and hence the botnet signatures, and C&C server names/addresses).
In order to design such a general detection system that can resist evolution and changes in botnet C&C techniques, we need to study the intrinsic botnet communication and activity characteristics that remain detectable with the proper detection features and algorithms. We thus start with the definition and essential properties of a botnet. We define a botnet as:
``A coordinated group of malware instances that are controlled via C&C channels''.
The term ``malware'' means these bots are used to perform malicious activities. According to [44], about 53% of botnet activity commands observed in thousands of real-world IRC-based botnets are related to scan (for the purpose of spreading or DDoS2), and about 14.4% are related to binary downloading (for the purpose of malware updating). In addition, most of HTTP-based and P2P-based botnets are used to send spam [18,39]. The term ``controlled'' means these bots have to contact their C&C servers to obtain commands to carry out activities, e.g., to scan. In other words, there should be communication between bots and C&C servers/peers (which can be centralized or distributed). Finally, the term ``coordinated group'' means that multiple (at least two) bots within the same botnet will perform similar or correlated C&C communications and malicious activities. If the botmaster commands each bot individually with a different command/channel, the bots are nothing but some isolated/unrelated infections. That is, they do not function as a botnet according to our definition and are out of the scope of this work3.
We propose a general detection framework that is based on these essential properties of botnets. This framework monitors both who is talking to whom that may suggest C&C communication activities and who is doing what that may suggest malicious activities, and finds a coordinated group pattern in both kinds of activities. More specifically, our detection framework clusters similar communication activities in the C-plane (C&C communication traffic), clusters similar malicious activities in the A-plane (activity traffic), and performs cross cluster correlation to identify the hosts that share both similar communication patterns and similar malicious activity patterns. These hosts, according to the botnet definition and properties discussed above, are bots in the monitored network.
This paper makes the following main contributions.
The rest of the paper is organized as follows. In Section 2, we describe the assumptions, objectives, architecture of our BotMiner detection framework, and its detection algorithms and implementation. In Section 3, we describe our evaluation on various real-world network traces. In Section 4, we discuss current limitations and possible solutions. We review the related work in Section 5 and conclude in Section 6.
According to the definition given above, a botnet is characterized by both a C&C communication channel (from which the botmaster's commands are received) and malicious activities (when commands are executed). Some other forms of malware (e.g., worms) may perform malicious activities, but they do not connect to a C&C channel. On the other hand, some normal applications (e.g., IRC clients and normal P2P file sharing software) may show communication patterns similar to a botnet's C&C channel, but they do not perform malicious activities.
Figure 1 illustrates two typical botnet structures, namely centralized and P2P. The bots receive commands from the botmaster using a push or pull mechanism [20] and execute the assigned tasks.
The operation of a centralized botnet is relatively easy and intuitive [20], whereas this is not necessarily true for P2P botnets. Therefore, here we briefly illustrate an example of a typical P2P-based botnet, namely Storm worm [18,23]. In order to issue commands to the bots, the botmaster publishes/shares command files over the P2P network, along with specific search keys that can be used by the bots to find the published command files. Storm bots utilize a pull mechanism to receive the commands. Specifically, each bot frequently contacts its neighbor peers searching for specific keys in order to locate the related command files. In addition to search operations, the bots also frequently communicate with their peers and send keep-alive messages.
In both centralized and P2P structures, bots within the same botnet are likely to behave similarly in terms of communication patterns. This is largely due to the fact that bots are non-human driven, pre-programmed to perform the same routine C&C logic/communication as coordinated by the same botmaster. In the centralized structure, even if the address of the C&C server may change frequently (e.g., by frequently changing the A record of a Dynamic DNS domain name), the C&C communication patterns remain unchanged. In the case of P2P-based botnets, the peer communications (e.g., to search for commands or to send keep-alive messages) follow a similar pattern for all the bots in the botnet, although each bot may have a different set of neighbor peers and may communicate on different ports.
Regardless of the specific structure of the botnet (centralized or P2P), members of the same botnet (i.e., the bots) are coordinated through the C&C channel. In general, a botnet is different from a set of isolated individual malware instances, in which each different instance is used for a totally different purpose. Although in an extreme case a botnet can be configured to degenerate into a group of isolated hosts, this is not the common case. In this paper, we focus on the most typical and useful situation in which bots in the same botnet perform similar/coordinated activities. To the best of our knowledge, this holds true for most of the existing botnets observed in the wild.
To summarize, we assume that bots within the same botnet will be characterized by similar malicious activities, as well as similar C&C communication patterns. Our assumption holds even in the case when the botmaster chooses to divide a botnet into sub-botnets, for example by assigning different tasks to different sets of bots. In this case, each sub-botnet will be characterized by similar malicious activities and C&C communications patterns, and our goal is to detect each sub-botnet. In Section 4 we provide a detailed discussion on possible evasive botnets that may violate our assumptions.
The objective of BotMiner is to detect groups of compromised machines within a monitored network that are part of a botnet. We do so by passively analyzing network traffic in the monitored network.
Note that we do not aim to detect botnets at the very moment when victim machines are compromised and infected with malware (bot) code. In many cases these events may not be observable by passively monitoring network traffic. For example, an already infected laptop may be carried in and connected to the monitored network, or a user may click on a malicious email attachment and get infected. In this paper we are not concerned with the way internal hosts become infected (e.g., by malicious email attachments, remote exploiting, and Web drive-by download). We focus on the detection of groups of already compromised machines inside the monitored network that are part of a botnet.
Our detection approach meets several goals:
Figure 2 shows the architecture of our BotMiner detection system, which consists of five main components: C-plane monitor, A-plane monitor, C-plane clustering module, A-plane clustering module, and cross-plane correlator.
The two traffic monitors in C-plane and A-plane can be deployed at the edge of the network examining traffic between internal and external networks, similar to BotHunter [19] and BotSniffer [20]4. They run in parallel and monitor the network traffic. The C-plane monitor is responsible for logging network flows in a format suitable for efficient storage and further analysis, and the A-plane monitor is responsible for detecting suspicious activities (e.g., scanning, spamming, and exploit attempts). The C-plane clustering and A-plane clustering components process the logs generated by the C-plane and A-plane monitors, respectively. Both modules extract a number of features from the raw logs and apply clustering algorithms in order to find groups of machines that show very similar communication (in the C-plane) and activity (in the A-plane) patterns. Finally, the cross-plane correlator combines the results of the C-plane and A-plane clustering and makes a final decision on which machines are possibly members of a botnet. In an ideal situation, the traffic monitors should be distributed on the Internet, and the monitor logs are reported to a central repository for clustering and cross-plane analysis.
In our current prototype system, traffic monitors are implemented in C for the purpose of efficiency (working on real-time network traffic). The clustering and correlation analysis components are implemented mainly in Java and R (https://www.r-project.org/), and they work offline on logs generated from the monitors.
The following sections present the details of the design and implementation of each component of the detection framework.
Our A-plane monitor is built based on Snort [36], an open-source intrusion detection tool, for the purpose of convenience. We adapted existing intrusion detection techniques and implemented them as Snort pre-processor plug-ins or signatures. For scan detection we adapted SCADE (Statistical sCan Anomaly Detection Engine), which is a part of BotHunter [19] and available at [11]. Specifically, we mainly use two anomaly detection modules: the abnormally-high scan rate and weighted failed connection rate. We use an OR combination rule, so that an event detected by either of the two modules will trigger an alert. In order to detect spam-related activities, we developed a new Snort plug-in. We focused on detecting anomalous amounts of DNS queries for MX records from the same source IP and the amount of SMTP connections initiated by the same source to mail servers outside the monitored network. Normal clients are unlikely to act as SMTP servers and therefore should rely on the internal SMTP server for sending emails. Use of many distinct external SMTP servers for many times by the same internal host is an indication of possible malicious activities. For the detection of PE (Portable Executable) binary downloading we used an approach similar to PEHunter [42] and BotHunter's egg download detection method [19]. One can also use specific exploit rules in BotHunter to detect internal hosts that attempt to exploit external machines. Other state-of-the-art detection techniques can be easily added to our A-plane monitoring to expand its ability to detect typical botnet-related malicious activities.
It is important to note that A-plane monitoring alone is not sufficient for botnet detection purpose. First of all, these A-plane activities are not exclusively used in botnets. Second, because of our relatively loose design of A-plane monitor (for example, we will generate a log whenever there is a PE binary downloading in the network regardless of whether the binary is malicious or not), relying on only the logs from these activities will generate a lot of false positives. This is why we need to further perform A-plane clustering analysis as discussed shortly in Section 2.6.
C-plane clustering is responsible for reading the logs generated by the C-plane monitor and finding clusters of machines that share similar communication patterns. Figure 3 shows the architecture of the C-plane clustering.
First of all, we filter out irrelevant (or uninteresting) traffic flows. This is done in two steps: basic-filtering and white-listing. It is worth noting that these two steps are not critical for the proper functioning of the C-plane clustering module. Nonetheless, they are useful for reducing the traffic workload and making the actual clustering process more efficient. In the basic-filtering step, we filter out all the flows that are not directed from internal hosts to external hosts. Therefore, we ignore the flows related to communications between internal hosts6 and flows initiated from external hosts towards internal hosts (filter rule 1, denoted as F1). We also filter out flows that are not completely established (filter rule 2, denoted as F2), i.e., those flows that only contain one-way traffic. These flows are mainly caused by scanning activity (e.g., when a host sends SYN packets without completing the TCP hand-shake). In white-list filtering, we filter out those flows whose destinations are well known as legitimate servers (e.g., Google, Yahoo!) that will unlikely host botnet C&C servers. This filter rule is denoted as F3. In our current evaluation, the white list is based on the US top 100 and global top 100 most popular websites from Alexa.com.
After basic-filtering and white-listing, we further reduce the traffic workload by aggregating related flows into communication flows (C-flows) as follows. Given an epoch ![]() (typically one day), all
(typically one day), all ![]() TCP/UDP flows that share the same protocol (TCP or UDP), source IP, destination IP and port, are aggregated into the same C-flow
TCP/UDP flows that share the same protocol (TCP or UDP), source IP, destination IP and port, are aggregated into the same C-flow
![]() , where each
, where each ![]() is a single TCP/UDP flow. Basically, the set
is a single TCP/UDP flow. Basically, the set
![]() of all the
of all the ![]() C-flows observed during
C-flows observed during ![]() tells us ``who was talking to whom'', during that epoch.
tells us ``who was talking to whom'', during that epoch.
Given the discrete sample distribution of each of these four random variables, we compute an approximate version of it by means of a binning technique. For example, in order to approximate the distribution of fph we divide the x-axis in 13 intervals as
![]() . The values
. The values
![]() are computed as follows. First, we compute the overall discrete sample distribution of
are computed as follows. First, we compute the overall discrete sample distribution of ![]() considering all the C-flows in the traffic for an epoch
considering all the C-flows in the traffic for an epoch ![]() . Then, we compute the quantiles7
. Then, we compute the quantiles7
![]() ,
,
![]() , of the obtained distribution, and we set
, of the obtained distribution, and we set
![]() ,
,
![]() ,
,
![]() , etc.
Now, for each C-flow we can describe its fph (approximate) distribution as a vector of 13 elements, where each element
, etc.
Now, for each C-flow we can describe its fph (approximate) distribution as a vector of 13 elements, where each element ![]() represents the number of times fph assumed a value within the corresponding interval
represents the number of times fph assumed a value within the corresponding interval
![]() .
We also apply the same algorithm for ppf, bpp, and bps, and therefore we map each C-flow
.
We also apply the same algorithm for ppf, bpp, and bps, and therefore we map each C-flow ![]() into a pattern vector
into a pattern vector ![]() of
of ![]() elements.
Figure 5 shows the scaled visiting pattern extracted form the same C-flow shown in Figure 4.
elements.
Figure 5 shows the scaled visiting pattern extracted form the same C-flow shown in Figure 4.
Clustering C-flows is a challenging task because
![]() , the cardinality of
, the cardinality of
![]() , is often large even for moderately large networks, and the dimensionality
, is often large even for moderately large networks, and the dimensionality ![]() of the feature space is also large. Furthermore, because the percentage of machines in a network that are infected by bots is generally small, we need to
separate the few botnet-related C-flows from a large number of benign C-flows. All these make clustering of C-flows very expensive.
of the feature space is also large. Furthermore, because the percentage of machines in a network that are infected by bots is generally small, we need to
separate the few botnet-related C-flows from a large number of benign C-flows. All these make clustering of C-flows very expensive.
In order to cope with the complexity of clustering of
![]() , we solve the problem in several steps (currently in two steps), as shown in a simple form in Figure 6.
, we solve the problem in several steps (currently in two steps), as shown in a simple form in Figure 6.
Afterwards, we refine this result by performing a second-step clustering on each different dataset
![]() using a simple clustering algorithm on the complete description of the C-flows in
using a simple clustering algorithm on the complete description of the C-flows in
![]() (i.e., we do not perform dimensionality reduction in the second-step clustering). This second step generates a set of
(i.e., we do not perform dimensionality reduction in the second-step clustering). This second step generates a set of ![]() smaller and more precise clusters
smaller and more precise clusters
![]() .
.
We implement the first- and second-step clustering using the ![]() -means clustering algorithm [31].
-means clustering algorithm [31]. ![]() -means is an efficient algorithm based on
-means is an efficient algorithm based on ![]() -means [25], a very popular clustering algorithm. Different from
-means [25], a very popular clustering algorithm. Different from ![]() -means, the
-means, the ![]() -means algorithm does not require the user to choose the number
-means algorithm does not require the user to choose the number ![]() of final clusters in advance.
of final clusters in advance. ![]() -means runs multiple rounds of
-means runs multiple rounds of ![]() -means internally and performs efficient clustering validation using the Bayesian Information Criterion [31] in order to compute the best value of
-means internally and performs efficient clustering validation using the Bayesian Information Criterion [31] in order to compute the best value of ![]() .
. ![]() -means is fast and scales well with respect to the size of the dataset [31].
-means is fast and scales well with respect to the size of the dataset [31].
For the first-step (coarse-grained) clustering, we first reduce the dimensionality of the feature space from ![]() features (see Section 2.5.1) into
features (see Section 2.5.1) into ![]() features by simply computing the mean and variance of the distribution of fph, ppf, bpp, and bps for each C-flow. Then we apply the
features by simply computing the mean and variance of the distribution of fph, ppf, bpp, and bps for each C-flow. Then we apply the ![]() -means clustering algorithm on the obtained representation of C-flows to find the coarse-grained clusters
-means clustering algorithm on the obtained representation of C-flows to find the coarse-grained clusters
![]() .
Since the size of the clusters
.
Since the size of the clusters
![]() generated by the first-step clustering is relatively small, we can now afford to perform a more expensive analysis on each
generated by the first-step clustering is relatively small, we can now afford to perform a more expensive analysis on each
![]() . Thus, for the second-step clustering, we use all the
. Thus, for the second-step clustering, we use all the ![]() available features to represent the C-flows, and we apply the
available features to represent the C-flows, and we apply the ![]() -means clustering algorithm to refine the results of the first-step clustering.
-means clustering algorithm to refine the results of the first-step clustering.
Of course, since unsupervised learning is a notoriously difficult task, the results of this two-step clustering algorithm may still be not perfect. As a consequence, the C-flows related to a botnet may be grouped into some distinct clusters, which basically represent sub-botnets. Furthermore, a cluster that contains mostly botnet or benign C-flows may also contain some ``noisy'' benign or botnet C-flows, respectively. However, we would like to stress the fact that these problems are not necessarily critical and can be alleviated by performing correlation with the results of the activity-plane (A-plane) clustering (see Section 2.7).
Finally, we need to note that it is possible to bootstrap the clustering from A-plane logs. For example, one may apply clustering to only those hosts that appear in the A-plane logs (i.e., the suspicious activity logs). This may greatly reduce the workload of the C-plane clustering module, if speed is the main concern. Similarly, one may bootstrap the A-plane correlation from C-plane logs, e.g., by monitoring only clients that previously formed communication clusters, or by giving monitoring preference to those clients that demonstrate some persistent C-flow communications (assuming botnets are used for long-term purpose).
In this stage, we perform two-layer clustering on activity logs. Figure 7 shows the clustering process in A-plane.
For the whole list of clients that perform at least one malicious activity during one day, we first cluster them according to the types of their activities (e.g., scan, spam, and binary downloading). This is the first layer clustering. Then, for each activity type, we further cluster clients according to specific activity features (the second layer clustering). For scan activity, features could include scanning ports, that is, two clients could be clustered together if they are scanning the same ports. Another candidate feature could be the target subnet/distribution, e.g., whether the clients are scanning the same subnet. For spam activity, two clients could be clustered together if their SMTP connection destinations are highly overlapped. This might not be robust when the bots are configured to use different SMTP servers in order to evade detection. One can further consider the spam content if the whole SMTP traffic is captured. To cluster spam content, one may consider the similarity of embedded URLs that are very likely to be similar with the same botnet [43], SMTP connection frequency, content entropy, and the normalized compression distance (NCD [5,41]) on the entire email bodies. For outbound exploit activity, one can cluster two clients if they send the same type of exploit, indicated by the Snort alert SID. For binary downloading activity, two clients could be clustered together if they download similar binaries (because they download from the same URL as indicated in the command from the botmaster). A distance function between two binaries can be any string distance such as DICE used in [20] 8.In our current implementation, we cluster scanning activities according to the destination scanning ports. For spam activity clustering, because there are very few hosts that show spamming activities in our monitored network, we simply cluster hosts together if they perform spamming (i.e., using only the first layer clustering here). For binary downloading, we configure our binary downloading monitor to capture only the first portion (packet) of the binary for efficiency reasons (if necessary, we can also capture the entire binary). We simply compare whether these early portions of the binaries are the same or not. In other words, currently, our A-plane clustering implementation utilizes relatively weak cluster features. In the future, we plan to implement clustering on more complex feature sets discussed above, which are more robust against evasion. However, even with the current weak cluster features, BotMiner already demonstrated high accuracy with a low false positive rate as shown in our later experiments.
Once we obtain the clustering results from A-plane (activities patterns) and C-plane (communication patterns), we perform cross-plane correlation. The idea is to cross-check clusters in the two planes to find out intersections that reinforce evidence of a host being part of a botnet. In order to do this, we first compute a botnet score ![]() for each host
for each host ![]() on which we have witnessed at least one kind of suspicious activity. We filter out the hosts that have a score below a certain detection threshold
on which we have witnessed at least one kind of suspicious activity. We filter out the hosts that have a score below a certain detection threshold ![]() , and then group the remaining most suspicious hosts according to a similarity metric that takes into account the A-plane and C-plane clusters these hosts have in common.
, and then group the remaining most suspicious hosts according to a similarity metric that takes into account the A-plane and C-plane clusters these hosts have in common.
We now explain how the botnet score is computed for each host.
Let ![]() be the set of hosts reported in the output of the A-plane clustering module, and
be the set of hosts reported in the output of the A-plane clustering module, and ![]() . Also, let
. Also, let
![]() be the set of
be the set of ![]() A-clusters that contain
A-clusters that contain ![]() , and
, and
![]() be the set of
be the set of ![]() C-clusters that contain
C-clusters that contain ![]() .
We compute the botnet score for
.
We compute the botnet score for ![]() as
as
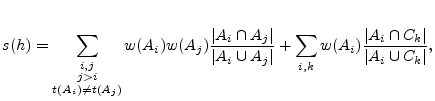 |
(1) |
![]() will receive a high score if it has performed multiple types of suspicious activities, and if other hosts that were clustered with
will receive a high score if it has performed multiple types of suspicious activities, and if other hosts that were clustered with ![]() also show the same multiple types of activities.
For example, assume that
also show the same multiple types of activities.
For example, assume that ![]() performed scanning and then attempted to exploit a machine outside the monitored network. Let
performed scanning and then attempted to exploit a machine outside the monitored network. Let ![]() be the cluster of hosts that were found to perform scanning and were grouped with
be the cluster of hosts that were found to perform scanning and were grouped with ![]() in the same cluster. Also, let
in the same cluster. Also, let ![]() be a cluster related to exploit activities that includes
be a cluster related to exploit activities that includes ![]() and other hosts that performed similar activities. A larger overlap between
and other hosts that performed similar activities. A larger overlap between ![]() and
and ![]() would result in a higher score being assigned to
would result in a higher score being assigned to ![]() . Similarly, if
. Similarly, if ![]() belongs to A-clusters that have a large overlap with C-clusters, then it means that the hosts clustered together with
belongs to A-clusters that have a large overlap with C-clusters, then it means that the hosts clustered together with ![]() share similar activities as well as similar communication patterns.
share similar activities as well as similar communication patterns.
Given a predefined detection threshold ![]() , we consider all the hosts
, we consider all the hosts ![]() with
with
![]() as (likely) bots, and filter out the hosts whose scores do not exceed
as (likely) bots, and filter out the hosts whose scores do not exceed ![]() . Now, let
. Now, let
![]() be the set of detected bots,
be the set of detected bots,
![]() be the set of A-clusters that each contains at least one bot
be the set of A-clusters that each contains at least one bot ![]() , and
, and
![]() be the set of C-clusters that each contains at least one bot
be the set of C-clusters that each contains at least one bot ![]() . Also, let
. Also, let
![]() be an ordered union/set of A- and C-clusters.
We then describe each bot
be an ordered union/set of A- and C-clusters.
We then describe each bot ![]() as a binary vector
as a binary vector
![]() , whereby the
, whereby the ![]() -th element
-th element ![]() if
if
![]() , and
, and ![]() otherwise.
Given this representation, we can define the following similarity between bots
otherwise.
Given this representation, we can define the following similarity between bots ![]() and
and ![]() as
as
 |
(2) |
This definition of similarity between hosts gives us the opportunity to apply hierarchical clustering. This allows us to build a dendrogram, i.e., a tree like graph (see Figure 8) that encodes the relationships among the bots. We use the Davies-Bouldin (DB) validation index [21] to find the best dendrogram cut, which produces the most compact and well separated clusters. The obtained clusters group bots in (sub-) botnets.
Figure 8 shows a (hypothetical) example. Assuming that the best cut suggested by the DB index is the one at height 90, we would obtain two botnets, namely
![]() , and
, and
![]() .
.
In our current implementation, we simply set weight ![]() for all
for all ![]() and
and ![]() , which essentially means that we will consider all hosts that appear in two different types of A-clusters and/or in both A- and C-clusters as suspicious candidates for further hierarchical clustering.
, which essentially means that we will consider all hosts that appear in two different types of A-clusters and/or in both A- and C-clusters as suspicious candidates for further hierarchical clustering.
To evaluate our BotMiner detection framework and prototype system, we have tested its performance on several real-world network traffic traces, including both (presumably) normal data from our campus network and collected botnet data.
We set up traffic monitors to work on a span port mirroring a backbone router at the campus network of the College of Computing at Georgia Tech. The traffic rate is typically 200Mbps-300Mbps at daytime. We ran the C-plane and A-plane monitors for a continuous 10-day period in late 2007. A random sampling of the network trace shows that the traffic is very diverse, containing many normal application protocols, such as HTTP, SMTP, POP, FTP, SSH, NetBios, DNS, SNMP, IM (e.g., ICQ, AIM), P2P (e.g., Gnutella, Edonkey, bittorrent), and IRC. This serves as a good background to test the false positives and detection performance on a normal network with rich application protocols.
We have collected a total of eight different botnets covering IRC, HTTP and P2P. Table 1 lists the basic information about these traces.
We re-used two IRC and two HTTP botnet traces introduced in [20], i.e., V-Spybot, V-Sdbot, B-HTTP-I, and B-HTTP-II. In short, V-Spybot and V-Sdbot are generated by executing modified bot code (Spybot and Sdbot [6]) in a fully controlled virtual network. They contain four Windows XP/2K IRC bot clients, and last several minutes. B-HTTP-I and B-HTTP-II are generated based on the description of Web-based C&C communications in [24,39]. Four bot clients communicate with a controlled server and execute the received command (e.g., spam). In B-HTTP-I, the bot contacts the server periodically (about every five minutes) and the whole trace lasts for about 3.6 hours. In B-HTTP-II, we have a more stealthy C&C communication where the bot waits a random time between zero to ten minutes each time before it visits the server, and the whole trace lasts for 19 hours. These four traces are renamed as Botnet-IRC-spybot, Botnet-IRC-sdbot, Botnet-HTTP-1, and Botnet-HTTP-2, respectively. In addition, we also generated a new IRC botnet trace that lasts for a longer time (a whole day) using modified Rbot [3] source code. Again this is generated in a controlled virtual network with four Windows clients and one IRC server. This trace is labeled as Botnet-IRC-rbot.
We also obtained a real-world IRC-based botnet C&C trace that was captured in the wild in 2004, labeled as Botnet-IRC-N. The trace contains about 7-minute IRC C&C communications, and has hundreds of bots connected to the IRC C&C server. The botmaster set the command ``.scan.startall'' in the TOPIC of the channel. Thus, every bot would begin to propagate through scanning once joining the channel. They report their successful transfer of binary to some machines, and also report the machines that have been exploited. We believe this could be a variant of Phatbot [6]. Although we obtained only the IRC C&C traffic, we hypothesize that the scanning activities are easy to detect given the fact that bots are performing scanning commands in order to propagate. Thus, we assume we have an A-plane cluster with the botnet members because we want to see if we can still capture C-plane clusters and obtain cross-plane correlation results.
Finally, we obtained a real-world trace containing two P2P botnets, Nugache [28] and Storm [18,23]. The trace lasts for a whole day, and there are 82 Nugache bots and 13 Storm bots in the trace. It was captured from a group of honeypots running in the wild in late 2007. Each instance is running in Wine (an open source implementation of the Windows API on top of Unix/Linux) instead of a virtual or physical machine. Such a set-up is known as winobot [12] and is used by researchers to track botnets. By using a lightweight emulation environment (Wine), winobots can run hundreds and thousands of black-box instances of a given malware. This allows one to participate in a P2P botnet en mass. Nugache is a TCP-based P2P bot that performs encrypted communications on port 8. Storm, originating in January of 2007, is one of the very few known UDP based P2P bots. It is based on the Kademlia [30] protocol and makes use of the Overnet network [2] to locate related data (e.g., commands). Storm is well-known as a spam botnet with a huge number of infected hosts [27]. In the implementation of winobot, several malicious capabilities such as sending spam are disabled for legality reason, thus we can not observe spam traffic from the trace. However, we ran a full version of Storm on a VM-based honeypot (instead of Wine environment) and easily observed that it kept sending a huge amount of spam traffic, which makes the A-plane monitoring quite easy. Similarly, when running Nugache on a VM-based honeypot, we observed scanning activity to port 8 because it attempted to connect to its seeding peers but failed a lot of times (because the peers may not be available). Thus, we can detect and cluster A-plane activities for these P2P botnets.
|
Table 2 lists the statistics for the 10 days of network data we used to validate our detection system. For each day there are around 5-10 billion packets (TCP and UDP) and 30-100 million flows. Table 2 shows the results of several steps of filtering. The first step of filtering (filter rule F1) seems to be the most effective filter in terms of data volume reduction. F1 filters out those flows that are not initiated from internal hosts to external hosts, and achieves about 90% data volume reduction. The is because most of the flows are within the campus network (i.e., they are initiated from internal hosts towards other internal hosts). F2 further filters out around 0.5-3 million of non-completely-established flows. F3 further reduces the data volume by filtering out another 30,000 flows. After applying all the three steps of filtering, there are around 1 to 3 million flows left per day. We converted these remaining flows into C-flows as described in Section 2.5, and obtained around 40,000 TCP C-flows and 130,000 UDP C-flows per day.
|
We then performed two-step clustering on C-flows as described in Section 2.5. Table 3 shows the clustering results and false positives (number of clusters that are not botnets). The results for the first 5 days are related to both TCP and UDP traffic, whereas in the last 5 days we focused on only TCP traffic.
It is easy to see from Table 3 that there are thousands of C-clusters generated each day. In addition, there are several thousand activity logs generated from A-plane monitors. Since we use relatively weak monitor modules, it is not surprising that we have this many activity logs. Many logs report binary downloading events or scanning activities. We cluster these activity logs according to their activity features. As explained early, we are interested in groups of machines that perform activities in a similar/coordinated way. Therefore, we filter out the A-clusters that contain only one host. This simple filtering rule allows us to obtain a small number of A-clusters and reduce the overall false positive rate of our botnet detection system.
|
Afterwards, we apply cross-plane correlation. We assume that the traffic we collected from our campus network is normal. In order to verify this assumption we used state-of-the-art botnet detection techniques like BotHunter [19] and BotSniffer [20]. Therefore, any cluster generated as a result of the cross-plane correlation is considered as a false positive cluster. It is easy to see from Table 3 that there are very few such false positive clusters every day (from zero to four). Most of these clusters contain only two clients (i.e., they induce two false positives). In three out of ten days no false positive was reported. In both Day-2 and Day-3, the cross-correlation produced one false positive cluster containing two hosts. Two false positive clusters were reported in each day from Day-5 to Day-8. In Day-4, the cross-plane correlation produced four false positive clusters.
For each day of traffic, the last column of Table 3 shows the false positive rate (FP rate), which is calculated as the fraction of IP addresses reported in the false positive clusters over the total number of distinct normal clients appearing in that day. After further analysis we found that many of these false positives are caused by clients performing binary downloading from websites not present in our whitelist. In practice, the number of false positives may be reduced by implementing a better binary downloading monitor and clustering module, e.g., by capturing the entire binary and performing content inspection (using either anomaly-based detection systems [38] or signature-based AV tools).
In order to validate the detection accuracy of BotMiner, we overlaid botnet traffic to normal traffic.
We consider one botnet trace at a time and overlay it to the entire normal traffic trace of Day-2.
We simulate a near-realistic scenario by constructing the test dataset as follows. Let ![]() be the number of distinct bots in the botnet trace we want to overlay to normal traffic. We randomly select
be the number of distinct bots in the botnet trace we want to overlay to normal traffic. We randomly select ![]() distinct IP addresses from the normal traffic trace and map them to the
distinct IP addresses from the normal traffic trace and map them to the ![]() IP addresses of the bots. That is, we replace an
IP addresses of the bots. That is, we replace an ![]() of a normal machine with the
of a normal machine with the ![]() of a bot. In this way, we obtain a dataset of mixed normal and botnet traffic where a set of
of a bot. In this way, we obtain a dataset of mixed normal and botnet traffic where a set of ![]() machines show both normal and botnet-related behavior.
Table 4 reports the detection results for each botnet.
machines show both normal and botnet-related behavior.
Table 4 reports the detection results for each botnet.
Table 4 shows that BotMiner is able to detect all eight botnets. We verified whether the members in the reported clusters are actually bots or not. For 6 out of 8 botnets, we obtained 100% detection rate, i.e., we successfully identified all the bots within the 6 botnets. For example, in the case of P2P botnets (Botnet-P2P-Nugache and Botnet-P2P-Storm), BotMiner correctly generated a cluster containing all the botnet members. In the case of Botnet-IRC-spybot, BotMiner correctly detected a cluster of bots. However, one of the bots belonging to the botnet was not reported in the cluster, which means that the detector generated a false negative. Botnet-IRC-N contains 259 bot clients. BotMiner was able to identify 258 of the bots in one cluster, whereas one of the bots was not detected. Therefore, in this case BotMiner had a detection rate of 99.6%.
There were some cases in which BotMiner also generated a false positive cluster containing two normal hosts. We verified that these two normal hosts in particular were also responsible for the false positives generated during the analysis of the Day-2 normal traffic (see Table 3).
As we can see, BotMiner performs quite well in our experiments, showing a very high detection rate with relatively few false positives in real-world network traces.
Like any intrusion/anomaly detection system, BotMiner is not perfect or complete. It is likely that once adversaries know our detection framework and implementation, they might find some ways to evade detection, e.g., by evading the C-plane and A-plane monitoring and clustering, or the cross-plane correlation analysis. We now address these limitations and discuss possible solutions.
Botnets may try to utilize a legitimate website (e.g., Google) for their C&C purpose in attempt to evade detection. Evasion would be successful in this case if we whitelisted such legitimate websites to reduce the volume of monitored traffic and improve the efficiency of our detection system. However, if a legitimate website, say Google, is used as a means to locate a secondary URL for actual command hosting or binary downloading, botnets may not be able to hide this secondary URL and the corresponding communications. Therefore, clustering of network traffic towards the server pointed by this secondary URL will likely allow us to detect the bots. Also, whitelisting is just an optional operation. One may easily choose not to use whitelisting to avoid such kind of evasion attempts (of course, in this case one may face the trade-off between accuracy and efficiency).
Botnet members may attempt to intentionally manipulate their communication patterns to evade our C-plane clustering. The easiest thing is to switch to multiple C&C servers. However, this does not help much to evade our detection because such peer communications could still be clustered together just like how we cluster P2P communications. A more advanced way is to randomize each individual communication pattern, for example by randomizing the number of packets per flow (e.g., by injecting random packets in a flow), and the number of bytes per packet (e.g., by padding random bytes in a packet). However, such randomization may introduce similarities among botnet members if we measure the distribution and entropy of communication features. Also, this randomization may raise suspicion because normal user communications may not have such randomized patterns. Advanced evasion may be attempted by bots that try to mimic the communication patterns of normal hosts, in a way similar to polymorphic blending attacks [15]. Furthermore, bots could use covert channes [1] to hide their actual C&C communications. We acknowledge that, generally speaking, communication randomization, mimicry attacks and covert channel represent limitations for all traffic-based detection approaches, including BotMiner's C-plane clustering technique. By incorporating more detection features such as content inspection and host level analysis, the detection system may make evasion more difficult.
Finally, we note that if botnets are used to perform multiple tasks (in A-plane), we may still detect them even when they can evade C-plane monitoring and analysis. By using the scoring algorithm described in Section 2.7, we can perform cross clustering analysis among multiple activity clusters (in A-plane) to accumulate the suspicious score needed to claim the existence of botnets. Thus, we may even not require C-plane analysis if there is already a strong cross-cluster correlation among different types of malicious activities in A-plane. For example, if the same set of hosts involve several types of A-plane clusters (e.g., they send spams, scan others, and/or download the same binaries), they can be reported as botnets because those behaviors, by themselves, are highly suspicious and most likely indicating botnets behaviors [19,20].
Malicious activities of botnets are unlikely or relatively hard to change as long as the botmaster wants the botnets to perform ``useful'' tasks. However, the botmaster can attempt to evade BotMiner's A-plane monitoring and clustering in several ways.
Botnets may perform very stealthy malicious activities in order to evade the detection of A-plane monitors. For example, they can scan very slowly (e.g., send one scan per hour), send spam very slowly (e.g., send one spam per day). This will evade our monitor sensors. However, this also puts a limit on the utility of bots.
In addition, as discussed above, if the botmaster commands each bot randomly and individually to perform different task, the bots are not different from previous generations of isolated, individual malware instances. This is unlikely the way a botnet is used in practice. A more advanced evasion is to differentiate the bots and avoid commanding bots in the same monitored network the same way. This will cause additional effort and inconvenience for the botmaster. To defeat such an evasion, we can deploy distributed monitors on the Internet to cover a larger monitored space.
Note, if the botmaster takes the extreme action of randomizing/individualizing both the C&C communications and attack activities of each bots, then these bots are probably not part of a botnet according to our specific definition because the bots are not performing similar/coordinated commanded activities. Orthogonal to the horizontal correlation approaches such as BotMiner to detect a botnet, we can always use complementary systems like BotHunter [19] that examine the behavior history of distinct host for a dialog or vertical correlation based approach to detect individual bots.
A botmaster can command the bots to perform an extremely delayed task (e.g., delayed for days after receiving commands). Thus, the malicious activities and C&C communications are in different days. If only using one day's data, we may not be able to yield cross-plane clusters. As a solution, we may use multiple-day data and cross check back several days. Although this has the hope of capturing these botnets, it may also suffer from generating more false positives. Clearly, there is a trade-off. The botmaster also faces the trade-off because a very slow C&C essentially impedes the efficiency in controlling/coordinating the bot army. Also, a bot infected machine may be disconnected from the Internet or be powered off by the users during the delay and become unavailable to the botmaster.
In summary, while it is possible that a botmaster can find a way to exploit the limitations of BotMiner, the convenience or the efficiency of botnet C&C and the utility of the botnet also suffer. Thus, we believe that our protocol- and structure-independent detection framework represents a significant advance in botnet detection.
To collect and analyze bots, researchers widely utilize honeypot techniques [4,32,16]. Freiling et al. [16] used honeypots to study the problem of botnets. Nepenthes [4] is a special honeypot tool for automatic malware sample collection. Rajab et al. [32] provided an in-depth measurement study of the current botnet activities by conducting a multi-faceted approach to collect bots and track botnets. Cooke et al. [10] conducted several basic studies of botnet dynamics. In [13], Dagon et al. proposed to use DNS sinkholing technique for botnet study and pointed out the global diurnal behavior of botnets. Barford and Yegneswaran [6] provided a detailed study on the code base of several common bot families. Collins et al. [9] presented their observation of a relationship between botnets and scanning/spamming activities.
Several recent papers proposed different approaches to detect botnets. Ramachandran et al.[34] proposed using DNSBL counter-intelligence to find botnet members that generate spams. This approach is useful for just certain types of spam botnets. In [35], Reiter and Yen proposed a system TAMD to detect malware (including botnets) by aggregating traffic that shares the same external destination, similar payload, and that involves internal hosts with similar OS platforms. TAMD's aggregation method based on destination networks focuses on networks that experience an increase in traffic as compared to a historical baseline. Different from BotMiner that focuses on botnet detection, TAMD aims to detect a broader range of malware. Since TAMD's aggregation features are different from BotMiner's (in which we cluster similar communication patterns and similar malicious activity patterns), TAMD and BotMiner can complement each other in botnet and malware detection. Livadas et al.[29,40] proposed a machine learning based approach for botnet detection using some general network-level traffic features of chat-like protocols such as IRC. Karasaridis et al.[26] studied network flow level detection of IRC botnet controllers for backbone networks. The above two are similar to our work in C-plane clustering but different in many ways. First, they are used to detect IRC-based botnet (by matching a known IRC traffic profile), while we do not have the assumption of known C&C protocol profiles. Second, we use a different feature set on a new communication flow (C-flow) data format instead of traditional network flow. Third, we consider both C-plane and A-plane information instead of just flow records.
Rishi [17] is a signature-based IRC botnet detection system by matching known IRC bot nickname patterns. Binkley and Singh [7] proposed combining IRC statistics and TCP work weight for the detection of IRC-based botnets. In [19], we described BotHunter, which is a passive bot detection system that uses dialog correlation to associate IDS events to a user-defined bot infection dialog model. Different from BotHunter's dialog correlation or vertical correlation that mainly examines the behavior history associated with each distinct host, BotMiner utilizes a horizontal correlation approach that examines correlation across multiple hosts. BotSniffer [20] is an anomaly-based botnet C&C detection system that also utilizes horizontal correlation. However, it is used mainly for detecting centralized C&C activities (e.g., IRC and HTTP).
The aforementioned systems are mostly limited to specific botnet protocols and structures, and many of them work only on IRC-based botnets. BotMiner is a novel general detection system that does not have such limitations and can greatly complement existing detection approaches.
Botnet detection is a challenging problem. In this paper, we proposed a novel network anomaly-based botnet detection system that is independent of the protocol and structure used by botnets. Our system exploits the essential definition and properties of botnets, i.e., bots within the same botnet will exhibit similar C&C communication patterns and similar malicious activities patterns. In our experimental evaluation on many real-world network traces, BotMiner shows excellent detection accuracy on various types of botnets (including IRC-based, HTTP-based, and P2P-based botnets) with a very low false positive rate on normal traffic.
It is likely that future botnets (especially P2P botnets) may utilize evasion techniques to avoid detection, as discussed in Section 4. In our future work, we will study new techniques to monitor/cluster communication and activity patterns of botnets, and these techniques are intended to be more robust to evasion attempts. In addition, we plan to further improve the efficiency of the C-flow converting and clustering algorithms, combine different correlation techniques (e.g., vertical correlation and horizontal correlation), and develop new real-time detection systems based on a layered design using sampling techniques to work in very high speed and very large network environments.
![\includegraphics[width=12cm]{figure/Cc-actvity.eps}](img1.png)
![\includegraphics[width=12cm]{figure/arch.eps}](img2.png)
![\includegraphics[width=10cm]{figure/Flow-cluster.eps}](img3.png)
![\begin{figure*}\centering
\begin{tabular}{llll}
\setlength{\epsfxsize}{0.4\...
...ize}
\subfigure[bps]
{\epsfbox{figure/bps.eps}}
\end{tabular}
\end{figure*}](img17.png)
![\begin{figure*}\centering
\begin{tabular}{llll}
\setlength{\epsfxsize}{0.4\...
...figure[Scaled bps]
{\epsfbox{figure/bps_bin.eps}}
\end{tabular}
\end{figure*}](img34.png)
![\includegraphics[scale=0.4]{figure/clustering.eps}](img40.png)
![\includegraphics[width=8cm]{figure/Activity-cluster.eps}](img50.png)
![\includegraphics[scale=0.5]{figure/bot-dendrogram.eps}](img87.png)