Sangeetha Seshadri*, Lawrence Chiu† and Ling Liu*
| *Georgia Institute of Technology 801 Atlantic Drive Atlanta, GA - 30332 {sangeeta,lingliu}@cc.gatech.edu | †IBM Almaden Research Center 650 Harry Road San Jose, CA - 95120 {lchiu}@us.ibm.com |
While system availability requirements are constantly being driven higher, failure recovery time is increasing due to increasing system size, higher performance expectations, virtualization and consolidation. Since software failure recovery is often performed through system-wide recovery, the recovery process itself does not scale with system size [6, 7, 8].
How can failure recovery be made scalable? Partitioning the system into smaller components with independent failure modes can reduce recovery time. However, it also increases management costs and decreases flexibility, while still being susceptible to sympathetic failures. On the other hand, refactoring the software into smaller independent components in order to use techniques such as micro-reboots [8] or software rejuvenation [9] requires sizable investments in terms of development and testing costs, unacceptable in the case of legacy systems. An alternative approach is to be able to perform fine-granularity recovery or micro-recovery, without re-architecting the system. Under this approach, failure recovery is targeted at a small subset of tasks/threads that need to undergo recovery while the rest of the system continues uninterrupted.
Enabling fine grained recovery can be challenging, especially in legacy systems, and the following issues must be addressed:
We address the first three questions, focusing on the challenges of tracking and restoring system state during micro-recovery, evaluating the possibility of recovery success and determining recovery actions. We make two unique contributions in terms of effective state restoration during micro-recovery. First, by analyzing the system state space, we identify the set of events and system states that affect state restoration from the perspective of micro-recovery. We introduce the concepts of Restoration levels and Recovery points to capture failure and recovery context and describe how to flexibly evaluate the possibility of recovery success. Based on the restoration levels and recovery points, we introduce Resource Recovery Protocol (RRP) and State Recovery Protocol (SRP), which provide rules to guide state restoration.
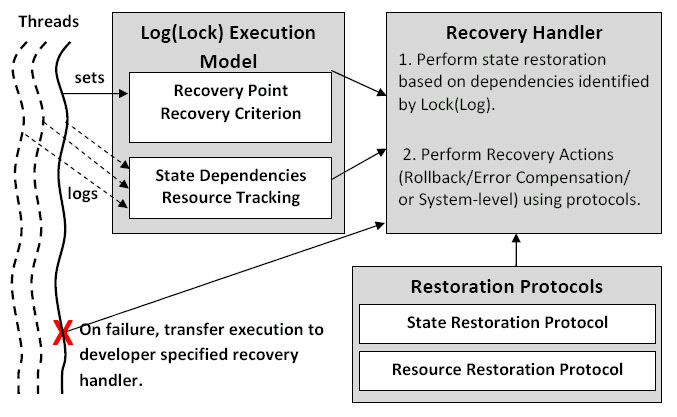
Our second contribution is Log(Lock), a practical and lightweight architecture to track dependencies and perform state restoration in complex, legacy software systems. Log(Lock) passively logs system state changes to help identify dependencies between multiple threads in a concurrent environment. Utilizing this record of state changes and resource ownership, Log(Lock) provides the developer with the failure context necessary to perform micro-recovery. Recovery points and their associated recovery handlers are specified by the developer. Log(Lock) is responsible for tracking dependencies and computing restoration levels at runtime.
We have implemented and evaluated Log(Lock) in a real enterprise storage controller. Our experimental evaluation shows that Log(Lock)-enabled micro-recovery is both efficient (<10% impact on performance) and effective (reduces a four second downtime to only a 35% performance impact lasting six seconds). In summary, micro-recovery with Log(Lock) presents a promising approach to improving storage software robustness and overall storage system availability.
This section gives an overview of the Log(Lock) system design. We first describe the problem statement that motivates the Log(Lock) design. Using examples, we highlight the unique characteristics of micro-recovery in the context of highly concurrent storage controller software. Then we outline the technical challenges for systematic state restoration during micro-recovery. Finally, we briefly describe the system architecture of Log(Lock).
In this section, we motivate the need for a flexible and lightweight state restoration architecture using a highly concurrent storage controller. The storage controller refers to the firmware that controls the cache and provides advanced functionality such as RAID, I/O routing, synchronization with remote instances and virtualization. In modern enterprise-class storage systems, the storage controller has evolved to become extremely complex with millions of lines of code that is often difficult to test. The controller code typically executes over an N-way processing complex using a large number of short concurrent threads (~20 million/minute). While the software is designed to extract maximum concurrency and satisfy stringent performance requirements, unlike database transactions it does not adhere to ACID (atomicity, consistency, isolation and durability) properties. This software is representative of a class expected to sustain high throughput and low response times continuously.
With this architecture, when one thread encounters an exception that causes the system to fail, the common way to return the system to an acceptable, functional state is by restarting and reinitializing the entire system. While the system reinitializes and waits for the operations to be redriven by a host, access to the system is lost contributing to downtime. As the system scales to larger number of cores and as the size of the in-memory structures increase, such system-wide recovery will no longer scale [ 6,8].
Many software systems, especially legacy systems, do not satisfy the conditions outlined as essential for micro-rebootable software [8]. For instance, even though the storage software may be reasonably modular, component boundaries, if they exist, are loosely defined and components are stateful. Under these circumstances, the scope of a recovery action is not limited to a single component.
The goal of micro-recovery is to perform recovery at a fine granularity such as at the thread-level, while determining the scope of recovery actions dynamically, based on dependencies identified at runtime. The key challenges in performing micro-recovery are identifying dependencies based on failure and recovery context, determining recovery actions and restoring the system to a consistent state after a failure.
Figure 1 shows two code snippets: R1 increments the number of active users before performing work and in R2, a background job is triggered when there are no active users in the system. When a panic (user defined or system failure/exception) occurs during the execution of region R1, then assume that the micro-recovery strategy is to reattempt execution of region R1. The recovery action must ensure clean relinquishing of resources such as the lock numActiveUsersLock. It is also important to ensure that the system state is consistent since corruption of the counter can either cause the background jobs to never be triggered or to be triggered in the presence of active users. In Example-1, while it is permissible for other threads to read the value of the numActiveUsers count at anytime provided the numActiveUsersLock has been released, the system must ensure that if and only if a thread fails after performing an increment operation on the count, a decrement operation is performed during recovery. On the other hand, if the failure was caused during the execution of region R2, an idempotent background task that is not critical, the recovery strategy may be to just abort the current execution of the background task. However, recovery must ensure that the lock numActiveUsersLock has been released.
Figure 2 shows the processing of a write command. In the event of encountering a failure, state restoration must ensure that temporary resources obtained from a shared pool are freed correctly in order to avoid resource leaks or starvation. It may also require that certain cache tracks are checked for consistency, depending upon the point of failure. However, for a resource such as a buffer or empty cache track obtained from a shared pool for exclusive use and not message passing, restoring the previous contents is not necessary.
Figure 3 shows a thread that updates a global variable indicating the metadata location, such as for checkpoint activity. In the event of a failure caused due to a failed location, the thread may have the opportunity to modify the location without notifying other threads or causing inconsistency, provided no other thread has already consumed the value. However if that is the case, the system may have to resort to recovery at a higher level.
These examples highlight the fact that consistency requirements for state restoration vary with failure context. For example, in the case of a counter generating unique numbers, the only requirement may be that modifications are monotonous. For a shared resource, the state remains consistent as long as there are no resource leaks that could eventually lead to starvation and system unavailability. Unlike a transactional system, where similar problems are addressed, the semantics of the state and failure may render certain types of conflicts irrelevant from the perspective of system recovery. This emphasizes the need for a flexible state restoration architecture that is also lightweight and efficient, thereby allowing the system to sustain high performance.
For example, consider a failure scenario where a write operation to disk fails because a driver from a third party vendor returns an unidentified error code due to a bug in its code. In this case, since writes are buffered in a fast write cache and the actual write to disk is performed asynchronously, dropping the request is not an option. Another example is a configuration issue that appeared early in the installation process that may have been fixed by trying various combinations of actions that were not correctly undone. As a result the system finds itself in an unknown state that manifests as a failure after some period of normal operation. Such errors are difficult to trace, and although transient may continue to appear every so often.
Some transient failures can be fixed through appropriate recovery actions that may range from dropping the current request to retrying the operation or performing a set of actions that take the system to a known consistent state. Some other examples of such transient faults that occur in storage controller code are: (1) An unsolicited response from an adapter - An adapter (a hardware component not controlled by our microcode) sends a response to a message which we did not send - or do not remember sending; (2) Incorrect Linear Redundancy Code (LRC): A control block has the wrong LRC check bytes, for instance, due to an undetected memory error; (3) Queue full condition: An adapter refuses to accept more work due to a queue full condition. In addition, there are other error scenarios such as violation of service level agreements. The `time-out' conditions are also common in large scale embedded storage systems. While the legacy system grows along multiple dimensions, the growth is not proportional along all dimensions. As a result hard-coded constant timeout values distributed in the code base often create unexpected artificial violations. For a more detailed classification of software failures, please refer to [6].
Threads in the system interact in two fundamental ways: (1) reading/writing shared data and (2) acquiring/releasing resources from/to a common pool. Threads also interact with the outside world through actions such as positioning a disk head or sending a response to an I/O. Often these actions cannot be rolled back and are referred to as outside world processes (OWP) [10]. In such a system, state restoration and micro-recovery must consider the sequence and interleaving of the actions of concurrent threads that gives rise to the following conflicts:
Checkpointing for fault-tolerance is a well known technique [10, 12, 13, 14] that has also been applied to deterministic replay for software debugging [15,16,17]. However, checkpointing techniques are mostly targeted at long-running applications [10] such as scientific workloads [13], or applications where the memory footprint and the system performance requirements can tolerate the overhead imposed by checkpointing [12,14]. A number of unique challenges in the case of storage controller software make checkpointing infeasible: Unlike long-running applications, storage controllers have a high rate of short (< 500μsecs) concurrent threads and are designed to support extremely high throughput and low response times. Given the highly concurrent nature of controllers, both quiescing the system in order to take the checkpoint, as well as logging the tasks in order to re-execute work beyond the checkpoint is expensive in terms of time and space - especially since system state includes large amounts of metadata and cached data. Next, communication with OWPs such as hosts and media cannot be rolled back and hence invalidates checkpoints. Finally, due to the complexity of the code, not all failures will be amenable to micro-recovery, making checkpointing too heavy weight.
System state restoration and conflict serialization is also of interest to transactional systems [18]. Transactional databases use schemes like strict 2-phase locking (2PL) to guarantee conflict serializability [19]. However, such techniques can increase the length of critical sections (i.e. durations of locks) and are inefficient for storage controllers that execute in a highly concurrent environment. Moreover, we show in Section 2.2 that, recovery actions are determined based on both the context and semantics of failure and a ``one size fits all'' serializability, while simplifying recovery procedures, can constrain the recovery process.
In the event of a failure, control transfers to a developer specified recovery handler. The handler performs state restoration actions by utilizing the resource tracking and state dependency information provided by the Log(Lock) execution model, in consultation with the restoration protocols. It also decides on an appropriate recovery strategy such as rollback, error compensation or system-level recovery. The implementation of the Log(Lock) dependency tracking component must ensure efficiency during normal operation while the recovery protocols ensure consistency of state restoration during failure recovery. Below, we summarize the four primary design objectives of Log(Lock):
In the next two sections, we first describe the concepts of `restoration levels' and `recovery points' and present the restoration protocols. Then, we present the Log(Lock) execution model and illustrate application of the protocols through example scenarios.
This section is divided into two parts. In the first part, we model system events, state transitions and interleaving of concurrent threads and demonstrate the discrete state space and recovery scenarios. We introduce the concepts of Restoration Level and Recovery Criterion, that help match a failure context to a recovery strategy. In the second part, we systematically identify the set of recovery strategies that can be applied to each failure scenario and present two protocols for state restoration. The Resource Recovery Protocol (RRP) defines the steps to handle resource ownership conditions and the State Recovery Protocol (SRP) sets forth the rules to perform state restoration.
The state space for system execution consists of all legitimate schedules S(t). System states that represent the failed state of one of the executing threads are relevant from the perspective of micro-recovery. To simplify the subsequent discussion, we apply the following rules to reduce the state space:
From the perspective of state restoration for micro-recovery, the occurrences of the following patterns in the schedule S(t) are of interest and relevant to the selection of a recovery strategy by thread T1. Let → denote the ``happened before'' relation [20].
To determine the right strategy for recovery, it is important to determine which of the above conflicts have occurred and are relevant to recovery. CD does not figure in the recovery criterion since this information is used only to choose between alternate recovery strategies in the recovery handler. We discuss the use of CD conditions during recovery in the state recovery protocol in Section 3.2. In our current design, recovery points and their associated recovery handlers are identified by developers and are associated to an execution context. When a thread leaves a context, the associated recovery points go out of scope. Within a single execution context, multiple recovery points may be defined, any of which could potentially be used during recovery. Then the appropriate recovery point for the current failure scenario is chosen by the logic in the recovery handler. In the developer-specified recovery handler, the feasibility and correctness of restoring the failed system state using a recovery point, is determined using the resource and state recovery protocols described next. Once the valid recovery points have been identified from the available choices, the selection of an appropriate recovery point and recovery strategy may be a decision depending upon factors such as the amount of resources available for recovery and the time required to complete recovery.
The state recovery protocol (SRP) specifies the recovery strategies applicable for different failure and recovery contexts. The rationale behind the SRP rules is that an occurrence of DR, LU or UR events imply that an interaction with other concurrent threads in the system have occurred. When the restoration level does not meet the recovery criterion and interactions with other threads have occurred, then single thread recovery is no longer sufficient. Next, the success of multi-thread recovery depends on the occurrence of an externally visible action and whether the dependency has already been committed. Concretely, the rules of state recovery are:
In a complex legacy system such as a storage controller, not all failures can be handled efficiently through fine-grained recovery - either because the failure and recovery code may be too complex, or system-level recovery may be a more effective recovery technique, or simply because there may be insufficient development and testing resources. Therefore, our approach first involves identifying candidates for fine-grained recovery based on the analysis of failure logs and the software itself. The executing instance of each candidate is known as a recoverable thread. Recall that, for each recoverable thread multiple recovery points and associated recovery criterion may be defined. In the event of a failure, control is transferred to the recovery handler (Section 2.5).
Both the Undo Log and Change Track Logs are maintained only in main memory and are verified for integrity using checksums. In our implementation, the change track log is implemented as a hashtable indexed using the pointer to the lock as key. Unlike database logs or checkpoints for state restoration, these logs do not need to be flushed to stable storage. If a failure crashes the system causing it to lose or corrupt the logs, then we must perform a system-level restart to restore the system to a consistent, functional state and no longer require the software's state restoration logs from before the failure.
Log(Lock) provides four basic primitives to a recoverable thread:
All the above primitives are explicitly inserted into the code by the developer. The startTracking call is used to trigger change tracking for shared state and resources protected by the lock parameter. These accesses are identified by trapping lock/unlock calls. When the recoverable thread determines that the logs for a particular structure are no longer required, it explicitly issues a stopTracking call. In the event of a failure, the system transfers control to the designated recovery handler. The recovery handler can utilize the getRestorationLevel and getResourceOwnership primitives to determine the current restoration level and resource ownership and then invoke recovery procedures appropriately. The restoration level is determined by examining the undo and change track logs.
The goal of our state restoration approach is to return the system to a correct, functional and known state by performing localized recovery and state restoration actions. The recovery actions are targeted at only a small subset of the threads in the system and a small region of the total system state that has been identified as affected by failure-recovery.
Similarly, in the case of the example in Figure 2, assume that the recovery criterion only specifies the constraint on releasing the temporary resource acquired after the recovery point. Therefore, the getResourceOwnership primitive is used to obtain the current ownership status of the temporary resource. If the resource is held by the thread, in order to rollback to recovery point R3, the resource must be cleanly relinquished. The pseudo code for this example and the next is not shown due to lack of space.
In the case of the failure scenario shown in Figure 3, the recovery criterion for recovery point R4 would be that no resources acquired after the recovery point (such as lock MetadataLocationLock) should be held by the thread and that no DR or LU events should have occurred. If the restoration level indicates that no other thread has already consumed this value (i.e., no DR or LU events have occurred), then the changes of the failed thread can be undone safely by replacing with the values in the Undo log. However, if the value is likely to have been consumed by another thread (i.e. DR or LU occurred), then the restoration level does not meet the recovery criterion for R4. So, in accordance with SRP, the error cannot be handled using single-thread recovery. Depending upon the support for multi-thread recovery (provided the CD event has not occurred) recovery may require rollbacks of multiple threads. If however, CD has occurred, then system-level recovery or error-compensation is performed.
Undo logs go out of scope i.e., can be purged when a recoverable thread completes execution. Similarly, change track logs for a lock are purged when the recoverable thread issues a stopTracking call. However, unlike undo logs, change track logs cannot be purged immediately since these centralized logs may be shared by multiple recoverable threads. In that case, the log entries corresponding to the purging thread are only marked for purging and are actually purged when the last recoverable thread using the log issues a stopTracking call on that lock.
Multi-thread recovery i.e., applying state restoration and recovery to more than one thread, can typically handle more failure scenarios compared to single-thread recovery. However, multi-thread recovery is complex to implement. Moreover, multi-thread recovery may result in a domino effect [22] (also referred to as cascading aborts) potentially resulting in unavailability of resources and unbounded recovery time[6]. A simpler and more effective technique would be to limit recovery to a single thread and ensure recovery success through other mechanisms such as dependency tracking and scheduling. Recovery conscious scheduling [6] describes an approach where dependencies between concurrent threads are identified and dependent threads serialized. This approach can help limit the number of concurrent dependent threads and increase single-thread recovery success.
We identified state and resource instances that are changed or accessed rapidly through the observation periods, based on instrumenting the system (Table 2). We also identified representative failure scenarios by analyzing bug reports, failure logs and code. Using these scenarios as candidates for micro-recovery and state restoration, we evaluate Log(Lock) efficiency and effectiveness. In summary, our results show that:
Our workload was generated using a randomized synthetic workload generator which took as inputs the following parameters: read/write ratio, block size and queue depth (i.e. maximum number of outstanding requests from the host). The experiments presented in this paper utilized three distinct read/write ratios: 100% writes, 50%-50% mix of reads and writes and 100% reads. Block size was set to 4 KB and queue depth varied between 16 and 256.
Efficiency refers to the impact of Log(Lock) on system performance. To measure performance, we utilize two metrics: throughput (IOs per second or IOps) and latency (seconds/IO).
Effectiveness refers to the ability of the state restoration architecture to reduce the recovery time and positively impact the availability of the system. Concretely, it refers to the probability of recovery success with the Log(Lock) architecture and the impact on system recovery time.
Effectiveness is measured using the following metrics: (1) recovery success, i.e. the percentage of time the restoration level meets the recovery criterion for single thread recovery, and (2) recovery time, i.e. the time required to restore the system to a consistent state after encountering a failure. Note that in the experiments reported in this paper we focus on single thread recovery while evaluating recovery success. While our Log(Lock) approach can also be applied to multi-thread recovery, as described in Section 4.3, multi-thread recovery can be costly in terms of coding effort, resource consumption and recovery time. Instead, we assume that a technique such as recovery conscious scheduling [6] can help reduce the need for multi-thread recovery and improve the success of single thread recovery.
To evaluate effectiveness, we first measure the recovery success for the candidates identified from Table 2. We measure recovery success across locks with different rates of access and varying duration of tracking. To evaluate the impact on recovery time, we identify candidates for state restoration based on analysis of the software, failure logs and defects.
We present evaluation of the efficiency of our Log(Lock) architecture as compared to the original system, henceforth referred to as baseline. The baseline implementation does not perform state restoration or fine-grained recovery. Instead, it uses a highly efficient system level recovery mechanism that checks all persistent system structures such as non-volatile data in the write cache for consistency, reinitializes software state and redrives lost tasks. Note that no hardware reboot is involved.
| Lock | Contention Cycles (Count) | Number of accesses | Locks/IO |
Fiber channel |
2654991 (578) | 137196747 | 10.34 |
IO state |
219969 (76) | 90122610 | 6.79 |
Resource |
608103 (100) | 63482290 | 4.78 |
Resource state |
124965 (52) | 30040757 | 2.26 |
Throttle timer |
79848 (11) | 113316 | 0.0085 |
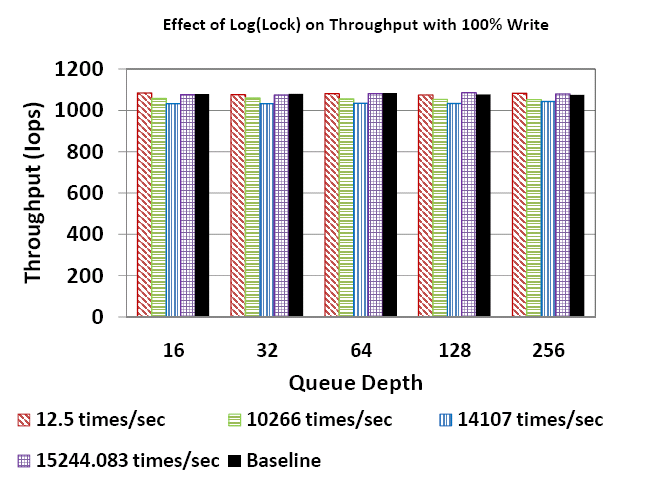
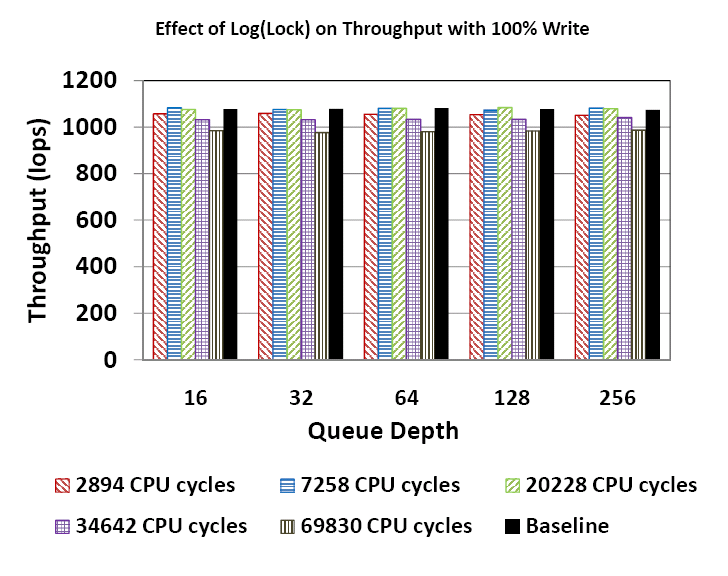
Figure 6 shows the throughput with varying access rates under different queue depths. The numbers show that even for high access rates, the Log(Lock) approach has negligible impact on performance. The lock with access rate 14107 times/sec (the resource pool lock) was tracked for 2429 CPU cycles and results in a 4.5% drop in throughput. We attribute this to the occurrence of nested lock conditions in that particular code path, causing the system to be sensitive to even the small delay introduced by Log(Lock).
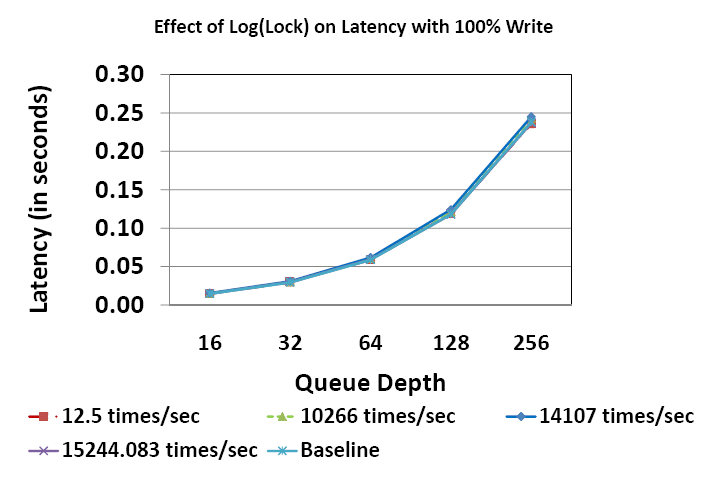
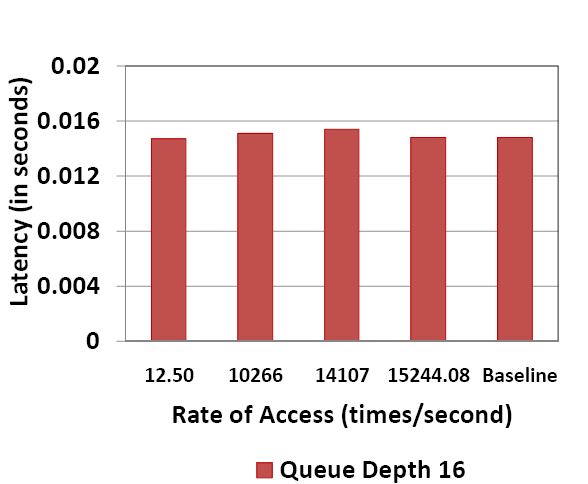
Figure 7 shows the variation of latency with queue depth for different access rates. The curves for the various access rates almost completely overlap showing that across configurations, the impact of Log(Lock) on latency, even for high access rates, is negligible. The observation that the latency increases with queue depth is a queuing effect commonly observed in systems [23] and is independent of Log(Lock). Figure 8 zooms into the points for queue depth 16 to give the reader a closer look at the data. As in the case of throughput, latency increases by ~4% for the resource pool lock and is attributed to the occurrence of nested lock situations in the code path. The important message from Figures 6 and 7 is that Log(Lock) tracking can sustain high performance even while tracking rapidly modified/accessed state or resources.
| Queue Depth | (Duration of tracking in CPU Cycles) | ||||
| 2894 | 7258 | 20228 | 34642 | 69830 | |
| % Increase in latency over baseline | |||||
| 16 | 2.03% | 0.68% | 0.00% | 4.05% | 9.46% |
| 32 | 1.69% | 0.34% | 0.34% | 4.39% | 10.47% |
| 64 | 2.72% | 0.34% | 0.51% | 4.76% | 10.71% |
| 128 | 2.54% | 0.85% | 0.00% | 5.08% | 9.32% |
| 256 | 2.10% | 0.00% | 0.42% | 2.94% | 8.82% |
From Figures 9 and Table 3 we observe that, the performance of the system with Log(Lock) is comparable to the baseline system across various queue depths. For the IO state lock (a lock in the IO path), when the duration of tracking was increased from 2894 CPU cycles to 69830 CPU cycles, the throughput dropped by 8.85% and response time increased by 9.76% on average compared to baseline. This drop in performance can be attributed to two factors: (1) occurrence of more conflicts with increase in duration of tracking and (2) increased possibility of encountering nested lock conditions, which are sensitive to the delay introduced by tracking. In the case of the resource lock, a tracking duration to 34642 CPU cycles resulted in a drop of only ~4.3%, which is nearly identical to the performance with a tracking duration of only 2429 CPU cycles, as shown in Section 5.4.1. We conclude that, though the overhead of tracking is a function of both the frequency and duration of tracking, it is more significantly impacted by the semantics of the lock being tracked and the efficiency of the code path involving the lock.
| Queue Depth | Workload 1 | Workload 2 | ||
| Throughput | Latency | Throughput | Latency | |
| 16 | 0.43% | 0.47% | 0.08% | ~0.00% |
| 32 | 0.25% | ~0.00% | 0.78% | 0.75% |
| 64 | 0.24% | 0.39% | 0.13% | ~0.00% |
| 128 | 0.29% | 0.39% | 0.79% | 0.75% |
| 256 | 0.25% | 0.00% | 0.12% | 0.19% |
Examining the object code for our implementation showed that in the event of a lock being tracked, fewer than 200 assembly instructions were added to the code path. Assuming one instruction executes per CPU cycle, even at a frequency of 15244 times/second, on a 3.00 GHz processor, this amounts to a time overhead of less than 1% (assuming that the size of the state being saved to undo logs is small). Also, note that storage controller code by itself is aggressively optimized to sustain high throughput, minimize the duration of locks in the I/O path and avoid nesting of locks to a large extent. Unlike checkpoints, which require a large amount of state to be copied to stable storage, our techniques copy small amounts of relevant state and information in memory only. The combination of all these factors results in the Log(Lock) system being able to sustain high performance despite an extremely high frequency of access to shared state and resources. In conclusion, we believe that the scenarios where performance will be impacted by tracking are when there are multiple levels of nesting with frequently accessed locks, increasing sensitivity to tracking delay. However, we expect that these situations are uncommon in well-designed systems.
| Lock | Recovery Criterion | Tracking Calls (times/sec) | #Access (times/sec) | Duration (CPU cycles) | Recovery Success |
| Fiber channel | No Residual Resources | 3666 | 15244 | 20228 | 100% |
| IO state | No DR, LU or UR | 2500 | 10266 | 2894 | 99.88% |
| Resource pool | No Residual Resources | 10 | 14107 | 34642 | 100% |
| Resource state | No Residual Resources | 5 | 6675 | 4806 | 100% |
| Throttle timer | No Residual Resources | 10 | 12.59 | 7258 | 100% |
| IO state | No DR, LU or UR | 2444 | 10045 | 69830 | 99.38% |
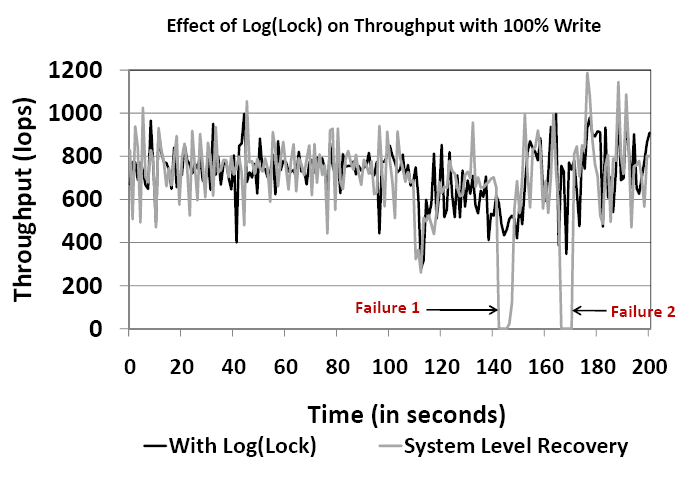
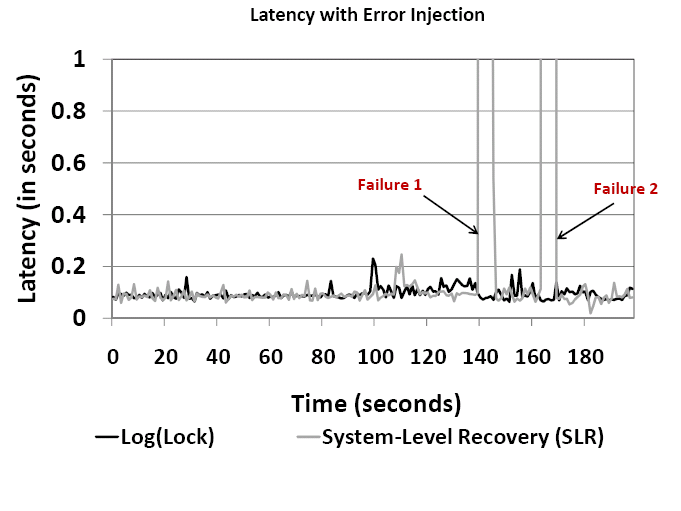
Figures 10 and 11 show the variation of throughput and latency respectively over time. The points of failure injection are marked in the figures. The throughput and latency shown are for a workload with 100% write IOs, queue depth 64 and disk latency 20 ms. The Log(Lock) architecture is compared to system-level recovery (abbreviated as SLR) in the case of the baseline system. Recall that SLR is implemented entirely in software and involves restarting the controller process and verifying data structures and cache data for consistency before redriving IO transactions. Overall, during failure-free operation, the average throughput and latency respectively with Log(Lock) is 708 IOps, 0.0946 sec/IO and 710 IOps, 0.0912 sec/IO for the baseline system.
Log(Lock)-enabled micro-recovery imposes a 35% performance overhead lasting six seconds during recovery. However, system-level recovery results in 4 seconds downtime and it takes an additional 2 seconds to begin sustaining high performance. It is important to remember that as the size of the system and in-memory data structures increase, the recovery time for SLR is bound to increase. This, along with the opportunity for micro-recovery illustrated by the high recovery success shown in the previous experiment, further promote the case for micro-recovery in high performance systems like the storage controller.
Application-specific recovery mechanisms such as recovery blocks [22], and exception handling [26] are used in many software systems. Constructs such as try/throw/catch [27] can be used to transfer control to an exception handler and a similar exception model is used by our implementation. However such exception handling constructs alone are insufficient for performing micro-recovery which requires richer failure context information. The goal of the Log(Lock) architecture is to provide this context information and provide the developer with a set of guidelines to decide the precise way in which the system should be restored given the failure context.
Logging of access patterns has been used for deterministic replay [15, 16, 17] during debugging. However, in micro-recovery, there is no requirement to perform deterministic replay. Also, the purpose of logging access patterns in Log(Lock) is to identify recovery dependencies between concurrent threads.
Even with retrofittable mechanisms such as micro-recovery, we emphasize that failure recovery should be a design concern. One approach to reducing recovery time would be to design the software using components with independent failure modes (e.g. client-server interactions) or use a state space based approach where transitions to functional states can be identified even from a failure state.
Our effort in designing scalable failure recovery continues along a number of directions. One of our ongoing efforts is to reduce the need for programmer intervention in defining recovery actions. We are also interested in deploying and evaluating Log(Lock) in other high performance systems.