![]()
![]()
![]()
Next: Fault tolerance Up: Adaptive
and Reliable Previous: Cilk-NOW job architecture
Adaptive parallelism allows a Cilk job to take advantage of idle machines whether or not they are idle when the job starts and whether or not they will remain idle for the duration of the job. In order to efficiently utilize machines that may join and leave a running job, the overhead of supporting this feature must not excessively slow down the work of any worker at a time when it is not joining or leaving. As we saw in the previous section, a new worker joins a job easily enough by registering with the clearinghouse and then stealing a closure. A worker leaves a job by migrating all of its closures to other workers, and here the danger lies. When we migrate a waiting closure, other closures with continuations that refer to this closure must somehow update these continuations so they can find the waiting closure at its new location. (Without adaptive parallelism, waiting closures never move.) Naively, each migrated waiting closure would have to inform every other closure of its new location. In this section, we show how we can take advantage of Cilk's well structuring and the work-stealing scheduler to make this migration extremely simple and efficient. (Experimental results documenting the efficiency of Cilk-NOW's adaptive parallelism have been omitted for lack of space but can be found in [6].)
Our approach is to impose additional structure on the organization of closures and continuations, such that the structure is cheap to maintain while simplifying the migration of closures. Specifically, we maintain closures in "subcomputations" that migrate en masse, and every continuation in a closure refers to a closure in the same subcomputation. In order to send a value from a closure in one subcomputation to a closure in another, we forward the value through intermediate "result closures," and give each result closure the ability to send the value to precisely one other closure in one other subcomputation. With this structure and these mechanisms, all of the overhead associated with adaptive parallelism (other than the actual migration of closures) occurs only when closures are stolen, and as we saw in Section 2, the number of steals grows at most linearly with the critical path of the computation and is not a function of the work. The bulk of this section's exposition concerns the organization of closures in subcomputations and the implementation of continuations. After covering these topics, the mechanism by which closures are migrated to facilitate adaptive parallelism is quite straightforward.
In Cilk-NOW, every closure is maintained in one of three pools associated with a data structure called a subcomputation. A subcomputation is a record containing (among other things) three pools of closures. The ready pool is the list of ready closures described in Section 2. The waiting pool is a list of waiting closures. The assigned pool is a list of ready closures that have been stolen away. Program execution begins with one subcomputation--the root subcomputation--allocated by worker 0 and containing a single closure--the initial thread of cilk_main--in the ready pool. In general, a subcomputation with any closures in its ready pool is said to be ready, and ready subcomputations can be executed by the scheduler as described in Section 2 with the additional provision that each waiting closure is kept in the waiting pool and then moved to the ready pool when its join counter decrements to zero. The assigned pool is used in work stealing as we shall now see.
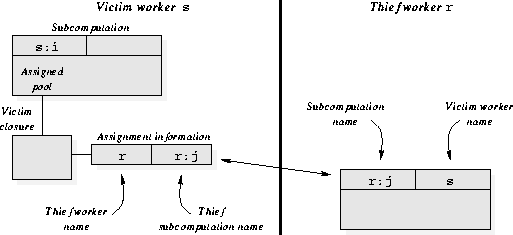
The act of work stealing creates a new subcomputation on the thief which is linked to a copy of the stolen closure kept in an assigned pool on the victim. If a worker needs to steal work, then before sending a steal request to a victim, it allocates a new subcomputation from a simple runtime heap and gives the subcomputation a unique name. The subcomputation's name is formed by concatenating the thief worker's name and a number unique to that worker. The first subcomputation allocated by a worker r is named r:1, the second is named r:2, and so on. The root subcomputation is named 0:1. The steal request message contains the name of the thief's newly allocated subcomputation. When the victim worker gets the request message, if it has any ready subcomputations, then it chooses a ready subcomputation in round-robin fashion, removes the closure at the tail of the subcomputation's ready pool, and places this victim closure in the assigned pool. As illustrated in Figure 5, the victim worker then assigns the closure to the thief's subcomputation by adding to the closure an assignment information record allocated from a simple runtime heap, and then storing the name of the thief worker and the name of the thief's subcomputation (as contained in the steal request message) in the assignment information. Finally, the victim worker sends a copy of the closure to the thief. When the thief receives the stolen closure, it records the name of the victim worker in its subcomputation, and it places the closure in the subcomputation's ready pool. Now the thief's subcomputation is ready, and the thief worker may commence executing it. Notice that the victim closure and thief subcomputation can refer to each other via the thief subcomputation's name which is stored both in the victim closure's assignment information and in the thief subcomputation, as illustrated in Figure 5.
Figure 5: A victim closure stolen from the
subcomputation s:i of victim worker s is assigned to
the thief subcomputation r:j. The victim closure is
placed in the assigned pool and augmented with assignment information
that records the name of the thief worker and the name of the thief
subcomputation. The thief subcomputation records its own name and the
name of the victim worker. Thus, the victim closure and thief
subcomputation can refer to each other via the thief subcomputation's
name.
When a worker finishes executing a subcomputation, the link between the subcomputation and its victim closure is destroyed. Specifically, when a subcomputation has no closures in any of its three pools, then the subcomputation is finished. A worker with a finished subcomputation sends a message containing the subcomputation's name to the subcomputation's victim worker. Using this name, the victim worker finds the victim closure. This closure is removed from its subcomputation's assigned pool and then the closure and its assignment information are freed. The victim worker then acknowledges the message, and when the thief worker receives the acknowledgment, it frees its subcomputation. When the root subcomputation is finished, the entire Cilk job is finished.
In addition to allocating a new subcomputation, whenever a worker steals a closure, it also allocates a new "result" closure, and it alters the continuation in the stolen closure so that it refers to the result closure. Consider a thief stealing a closure, and suppose the victim closure contains a continuation referring to a closure that we call the target. (The victim and target closures must be in the same subcomputation in the victim worker.) Continuations are implemented as the address of the target closure concatenated with the index of an argument slot in the target closure. Therefore, the continuation in the victim closure contains the address of the target closure, and this address is only meaningful to the victim worker. Thus, when the thief worker receives the stolen closure, it replaces the continuation with a new continuation referring to an empty slot in a newly allocated result closure. The stolen and result closures are part of the same subcomputation. The result closure's thread is a special system thread whose operation we shall explain shortly. This thread takes one argument: a result value. The result value is initially missing, and the continuation in the stolen closure is set to refer to this argument slot. The result closure is waiting and its join counter is 1.
Using continuations to send values from one thread to another operates as described in Section 2, but when a value is sent to a result closure, communication between different subcomputations occurs. When a result closure receives its result value, it becomes ready, and when its thread executes, it forwards the result value to another closure in another subcomputation as follows. When a worker executing a subcomputation executes a result closure's thread, it sends a message to the subcomputation's victim worker. This message contains the subcomputation's name as well as the result value that is the thread's argument. When the victim worker receives this message, it uses the subcomputation name to find the victim closure, and then it uses the continuation in the victim closure to send the result value to the target.
To summarize, each subcomputation contains a collection of closures and every continuation in a closure refers to another closure in the same subcomputation. To send a value from a closure in one subcomputation to a closure in another, the value must be forwarded through an intermediate result closure.
With this structure, migrating a subcomputation from one worker to another is fairly straightforward. At the source worker, the entire subcomputation is "pickled" by giving each of the subcomputation's closures a number and replacing each continuation's pointer with the corresponding number. Then, after sending the closures to the destination worker, the destination worker reconstructs the subcomputation by reversing the pickling operation. The subcomputation keeps its name, so after a migration, the first component of the subcomputation name will be different than the name of the worker. When the subcomputation and all of its closures have been migrated to their destination worker, this worker sends a message to the subcomputation's victim worker to inform the victim closure of its thief subcomputation's new thief worker. Additionally, for each of the subcomputation's assigned closures, it sends a message to the thief worker to inform the thief subcomputation of its victim closure's new victim worker. Thus, all of the links between victim closures and thief subcomputations are restored.