
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
Paper - 1999 USENIX Annual Technical Conference, June 6-11, 1999, Monterey, California, USA
[Technical Program]
Why does file system prefetching work?Elizabeth Shriver
Christopher Small
Keith A. Smith
AbstractMost file systems attempt to predict which disk blocks will be needed in the near future and prefetch them into memory; this technique can improve application throughput as much as 50%. But why? The reasons include that the disk cache comes into play, the device driver amortizes the fixed cost of an I/O operation over a larger amount of data, total disk seek time can be decreased, and that programs can overlap computation and I/O. However, intuition does not tell us the relative benefit of each of these causes, or techniques for increasing the effectiveness of prefetching. To answer these questions, we constructed an analytic performance model for file system reads. The model is based on a 4.4BSD-derived file system, and parameterized by the access patterns of the files, layout of files on disk, and the design characteristics of the file system and of the underlying disk. We then validated the model against several simple workloads; the predictions of our model were typically within 4% of measured values, and differed at most by 9% from measured values. Using the model and experiments, we explain why and when prefetching works, and make proposals for how to tune file system and disk parameters to improve overall system throughput.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (1) Seek_Time[dis] = |
|
When the request reaches the head of the queue, the disk checks its cache to see if the data are in cache. If not, the disk mechanism moves the disk head to the desired track (seeking) and waits until the desired sector is under the head (rotational latency). The disk then reads the desired data into the disk cache. The disk controller then contends for access to the bus, and transfers the data to the host from the disk cache at a rate determined by the speed of the bus controller and the bus itself. Once the host receives the data and copies them into the memory space of the file system, the system awakens any processes that are waiting for the read to complete.
The disk cache is used for multiple purposes. One is as a pass-through speed-matching buffer between the disk mechanism and the bus. Most disks do not retain data in the cache after the data have been sent to the host. A second purpose is as a readahead buffer. Data can be readahead into the disk cache to service future requests. Most frequently, this is done by the disk saving in a cache segment the data that comes after the requested data. Modern disks such as the Seagate Cheetah only readahead data when the requested addresses suggest that a sequential access pattern is present.
The disk cache is divided into cache segments. Each segment contains data prefetched from the disk for one sequential stream. The number of cache segments usually can be set on a per-disk basis; the typical range of allowable values is between one and sixteen.
Disk performance is covered in more detail by Shriver [Shriver97] and by Ruemmler and Wilkes [Ruemmler94].
Prefetching is not a new idea; in the 1970's, Multics supported prefetching [Feiertag72], as did Unix [Ritchie78]. Earlier work has focused on the benefit of prefetching, either by allowing applications to give prefetching hints to the operating system [Cao94,Patterson95,Mowry96], or by automatically discovering file access patterns in order to better predict which blocks to prefetch [Griffioen94,Lei97,Kroeger96]. Techniques studied have included neural networks [Madhyastha97a] and hidden Markov models [Madhyastha97b]. Our work differs from this work in three ways. First, we address only common case workloads that have sequential access patterns. Second, our model is parameterized by the file system's behavior such as caching strategy and file layout, and takes into account the behavioral characteristics of the disks used to store files. Third, our model predicts the performance of the file system.
Substantial work has been done studying the interaction between prefetching and caching [Cao95,Patterson95,Kimbrel96]. Others have examined methods to work around the file system cache to achieve the desired performance (e.g., [Kotz95]).
The benefit of prefetching is not limited to workloads where files are read sequentially; Small studied the effect of prefetching on random-access, zero think time workloads on the VINO operating system, and showed that even with these workloads the performance gain from prefetching was more than 20% [Small98].
Much work has been done in disk modeling. The usual approach to analyzing detailed disk drive performance is to use simulation (e.g., [Hofri80,Seltzer90,Worthington94]). Most early modeling studies (e.g., [Bastian82,Wilhelm77]) concentrated on rotational position sensing for mainframe disk drives, which had no cache at the disk and did no readahead. Most prior work has not been workload specific, and has, for example, assumed that the workload has uniform random spatial distributions (e.g., [Seeger96,Ng91,Merchant96]). Chen and Towsley, and Kuratti and Sanders, modeled the probability that no seek was needed [Chen93,Kuratti95]; Hospodor reported that an exponential distribution of seek times matched measurements well for three test workloads [Hospodor95]. Shriver and colleagues, and Barve and associates present analytic models for modern disk drives, representing readahead and queueing effects across a range of workloads [Shriver97,Shriver98,Barve99].
In this section, we present the file system, disk, and workload parameters that we need for our model. As we present the needed file system and disk parameters, we also give the values for the platforms which we used to validate the model. We close this section with presenting the details of the model.
We used two platforms; one with a slow bus (i.e., 10 MB/s), and one with a fast bus (i.e., 20 MB/s). Details of our test/experiment platforms are in Section 5.
| parameter | definition | validated platform |
|---|---|---|
| BlockSize | the amount of data whicht he file system processes at once | 8 KB |
| DirectBlocks | the number of blocks that can be accessed before the indirect block needs to be accessed | 12 |
| ClusterSize | the amount of a file that is stored contiguously on disk | 64 KB |
| CylinderGroupSize | number of bytes on a disk that file system treats as "close" | 16 MB |
| SystemCallOverhead | time needed to check the file system cache for the requested data | 10 microseconds |
| MemoryCopyRate | rate at which data are copied from the file system cache to the application memory | 10 microseconds / KB |
Based on our understanding of the file system cache policies, we determined a set of parameters that allow us to capture the performance of the file system cache; these can be found in Table 1. For our fast machine, the SystemCallOverhead value was 5 microseconds and the MemoryCopyRate was 5 microseconds/KB.
To predict the disk response time, we need to know several parameters of the disk being used.
The workload parameters that affect file system cache performance are the ones needed to predict the disk performance and the file layout on disk. Table 2 presents this set of parameters; most of these parameters were taken from earlier work on disk modeling [Shriver98]. 1
| parameter | definition | unit |
|---|---|---|
| temporal locality measures | ||
| request_rate | tate at which requests arrive at the storage device | requests/second |
| cylinder_group_id | cylinder group (location) of the file | integer |
| arrival_process | inter-request timing (constant [open, closed], Poisson, or bursty) | - |
| spacial locality measures | ||
| data_span | the span (range) of data accessed | bytes |
| request_size | the length of a host read or write request | bytes |
| run_length | lenght of a run, a contiguous set of requests | bytes |
Our approach has been to use the technique presented in our earlier work on disk modeling, which models the individual components of the I/O path, and then composes the models together [Shriver97]. We use some of the ideas presented in the disk cache model to model the file system cache.
The mean disk response time is the sum of disk overhead, disk head positioning time, and time to transfer the data from disk to the file system cache:
DRT = DiskOverhead + PositionTime + E[disk_request_size] / min(BusTR, DiskTR)
(Note: E[x] denotes the expected, or average value for x.) The amount of time spent positioning the disk head, PositionTime, depends on the current location of the disk head, which is determined by the previous request. For example, if this is the first request for a block in a given cluster, PositionTime will include both seek time and time for the rotational latency. Let E[SeekTime] be the mean seek time and E[RotLat] be the mean rotational latency (1/2 the time for a full disk rotation). Thus, the disk response time for the first request in a cluster is
(2) DRT[random request] = DiskOverhead + E[SeekTime] + E[RotLat] +
E[disk_request_size]/min(BusTR, DiskTR)
The mean disk request size, E[disk_request_size] , can be computed by averaging the request sizes; these can be computed by simulating the algorithm to determine the amount of data prefetched, where the simulation stops when the amount of accessed data is equal to ClusterSize. If the file system is servicing more than one file, the actual amount prefetched can be smaller than expected due to blocks being evicted before use. If the file system is not prefetching data, the E[disk_request_size] is the file system block size, BlockSize.
Sometimes the requested data are in the disk cache due to readahead; in these cases, the disk response time is
(3) DRT[cached_request] = DiskOverhead + E[disk_request_size]/BusTR
We first compute the amount of time needed for all of the file system accesses TotalFSRT, and then compute the mean response time for each access, FSRT, by averaging:
(4) FSRT = (data_span/request_size) * TotalFSRT
Let us first look at the simplest case: reading one file that resides entirely in one cluster, the mean response time to read the cluster contains file system overhead plus the time needed to access the data from disk:
---
ClusterRT = FSOverhead + DRT[first request] + \ DRT(remaining request )
/ i
---
i
where the first request and remaining requests are the disk requests
for the blocks in the cluster and
DRT[first request]
is
from equation (2).
If
n
files are being serviced at once,
the
DRT[remaining request i]'s each contain
E[SeekTime] + E[RotLat]
if n is more than
CacheSegments,
the number of disk cache segments.
If not, some of the data will be in disk cache and equation (3)
is used.
The
FSOverhead
can be measured experimently or computed as
SystemCallOverhead + E[request_size]/MemoryCopyRate.
The number of requests per cluster can be computed as
data_span/disk_request_size.
If the files span multiple clusters, we have
TotalFSRT = NumClusters * ClusterRTwhere we approximate the number of clusters as NumClusters = data_span/ClusterSize. To capture the ``extra'' cluster due to only the first DirectBlocks blocks being stored on the same cluster, this value is incremented by 1 if (ClusterSize / BlockSize) / DirectBlocks is not 1 and data_span / BlockSize > DirectBlocks.
If the device driver or disk controller scheduling algorithm is CLOOK or CSCAN and the queue is not zero, then there is a large seek time (for CLOOK) or a full stroke seek time (for CSCAN) for each group of n accesses, when n is the number of files being serviced by the file system; we call this time extra_seek_time.
If the n files being read are larger than DirectBlocks, we must include the time required to read the indirect block:
(5) TotalFSRT = n * NumClusters * ClusterRT +
num_requests * extra_seek_time +
DRT[indirect_block]
where
num_requests
is the number of disk requests in a file.
Since the location of the indirect block is on a random cylinder group,
equation (2) is used to compute
DRT[indirect block].
Of course, if the file contains more blocks than can be referenced
by both the inode and the indirect block, multiple indirect block terms are
needed.
In the introduction to this paper, we listed the reasons that prefetching improves performance: the disk cache comes into play, the device driver amortizes the fixed cost of an I/O over a larger amount of data, and total disk seek time can be decreased. In this section we discuss the terms introduced by our model and attempt to explain where the time goes, and when and why prefetching works. To do this, we collected detailed traces of a variety of workloads. These traces allowed us to compute the file system and disk response times experienced by the test machines. These response times were also used in our validations as discussed in Appendix A.
We performed experiments on two hardware configurations: a 200 MHz Pentium Pro processor and a 450 MHz Pentium II processor. Each machine had 128 MB of main memory. We conducted all of our tracing and measurements on a 4 GB Seagate ST34501W (Cheetah) disk, connected via a 10 MB/second PCI SCSI controller (for the 200 MHz processor) or via a 20 MB/second PCI SCSI controller (for the 450 MHz processor). Our test machines were running version 3.1 of the BSD/OS operating system. The file system parameters for our test file systems are found in Table 1 and the disk parameters are in Section 4.2.
We collected our traces by adding trace points to the BSD/OS kernel. At each trace point the kernel wrote a record to an in-memory buffer describing the type of event that had occurred and any related data. The kernel added a time stamp to each trace record, using the CPU's on-chip cycle counter. A user-level process periodically read the contents of the trace buffer.
To document the response time for application-level read requests, we used a pair of trace points at the entry and exit of the FFS read routine. Similarly, we measured disk-level response times using a pair of trace points in the SCSI driver, one when a request is issued to the disk controller, and a second when the disk controller indicates that the I/O has completed. Additional trace points documented the exact sequence (and size) of the prefetch requests issued by the file system, and the amount of time each request spent on the operating system's disk queue.
The numbers discussed in this section are for the machine with the faster bus unless stated otherwise.
When an application makes a read request of the file system, the file system checks to see if the requested data are in its cache, and if not, issues an I/O request to the disk. The data will be found in the file system cache if it was prefetched and has not been evicted. If the data are not in the file system's cache, the file system must read it from the disk. There are two possible scenarios:
 |
 |
Modern disks are capable of caching data for concurrent workloads, where each workload is reading a region of the disk sequentially. If there are enough cache segments for the current number of sequential workloads, the disk will readahead for each workload, and each workload will benefit. However, if there are more sequential workloads than cache segments, depending on the cache replacement algorithm used by the disk, the disk's ability to prefetch may have little or no positive effect on performance. In addition, disk readahead is only valuable when the file system prefetch size is less than the cluster size, since, after that, the entire cluster is fetched with one disk access. In the case of our file system parameters, this occurred when the file was 128 KB or smaller.
On our slow bus configuration, we measured the disk overhead of performing an I/O operation at 1.2 to 1.8 ms, which is on the same order as the time to perform a half-rotation (3 ms). The measured transfer rate of the bus is 9.3 MB/s; by saving an I/O operation, we can transfer an additional 11 to 16 KB. As an example, assume that 64 KB of data will be used by the application. If the requested data are in the disk cache, using a file block of 8 KB will take at least 14.1 ms (1.8 ms overhead four times + 6.9 ms for data transfer); 2 a file block of 64 KB will take 8.7 ms (1.8 ms overhead + 6.9 ms for data transfer), just a little over half the I/O time.
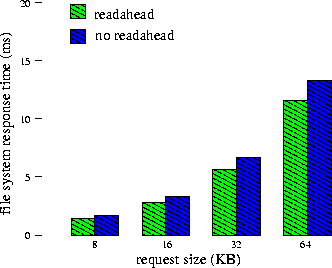
The impact of I/O cost amortization can be seen when comparing the measured file system response time when servicing one file, with and without prefetching. Figure 3 show these times for the slower hardware configuration. With prefetching disabled, the file system requests data in BlockSize units, increasing the number of requests, and the amount of disk and file system overhead. The additional overheads increase the resulting performance by 13-29%.
 |
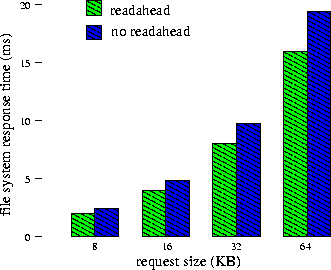
When we ran our tests on the machine with the faster bus, we noted anomalous disk behavior that we do not yet understand. According to our measurements, it should (and does, in most cases) take roughly 0.78 ms to read an 8 KB block from the disk cache over the bus on this machine. However, under certain circumstances, 8 KB reads from the disk cache complete more quickly, taking roughly 0.56 ms.3 This happened only when file system prefetching is disabled, i.e., when the file system requests multiple consecutive 8 KB blocks, and when there is only one application reading from the disk. The net result is that, in these rare situations, performance is slightly better with file system prefetching disabled. This behavior also was displayed with the slower bus, but as you can see in Figure 3, the bus is slow enough so that the response time with prefetching is smaller than the response time without prefetching.
As the number of active workloads increases, the latency for each workload will increase, but the disk throughput can, paradoxically, increase as well. Due to the type of scheduling algorithms used for the device driver queue, more elements in the read queue can mean smaller seeks between each read, and hence greater disk throughput. On the other hand, a longer queue means that each request will, on average, spend more time in the queue, and thus the read latency will be greater.
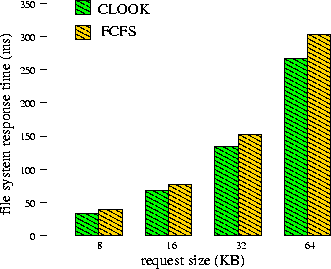 |
Figure 4 displays the file system response time with the device driver implementing the CLOOK scheduling algorithm (the standard algorithm), and implementing FCFS, which will not reduce the seek time. The performance gain from using CLOOK over FCFS is 14%.
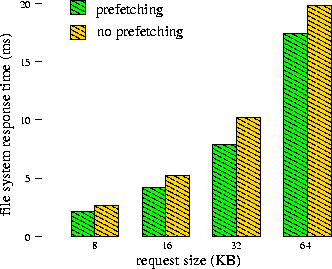
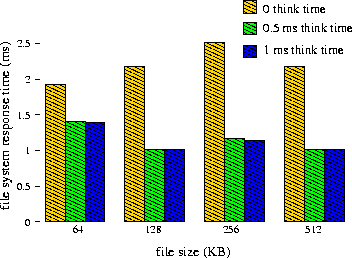
As was discussed in Section 1, if an application performs substantial computation as well as I/O, prefetching may allow the application to overlap the two, increasing application throughput and decreasing file system response time. For example, on our test hardware, computing the MD5 checksum of a 10 KB block of data takes approximately one millisecond. A program reading data from the disk and computing the MD5 checksum will exhibit delays between successive read requests, giving the file system time to prefetch data in anticipation of the next read request. Figure 5 shows the file system response times with a request size of 10 KB for files of varying lengths. The figure shows the response time given no delay (representing the application having no I/O / computation overlap), with an application delay of 0.5 ms, and with an application delay of 1.0 ms (as with MD5). As the file size increases, so do the savings due to prefetching. With a 64 KB file there is a 36% improvement, compared to a 114% improvement when reading a 512 KB file.
 |
We developed an analytic model that predicts the response time of the file system with a maximum relative error of 9% (see Appendix A). Given the wide range of conceivable file system layouts and prefetching policies, an accurate analytic model simplifies the task of setting system parameters that may improve performance enough to be worth implementing and studying in more detail.
Our model has allowed us to develop two suggestions for decreasing the file system response time. If it is reasonable to assume that the prefetched data will be used, and we have room in the file system cache, once the disk head has been positioned over a cluster, the entire cluster should be read. This will decrease the file system and disk overheads.
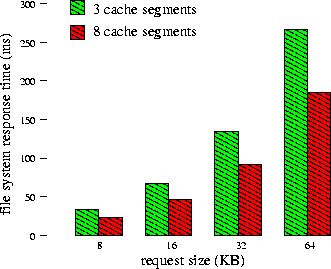
The number of disk cache segments restricts the number of sequential workloads for which the disk cache can perform readahead, which means that if the number of disk cache segments is smaller than the number of concurrent workloads, it can be as if the disk had no cache at all. One enhancement that we suggest is for the file system to dynamically modify the number of disk cache segments to be the number of files being concurrently accessed from that disk. This is a simple and inexpensive SCSI operation, and can mean the difference between having the disk cache work effectively and having it not work at all. Figure 6 compares the measured file system response time when servicing 8 workloads with 3 cache segments and the predicted response time with 8 cache segments. This shows us a 44-46% decrease in the response time when the number of cache segments is set to the number of concurrent workloads.
 |
Our current model does not handle file system writes; we would like to extend it to support writes. We would like to use our analytic model to compare different file system prefetching polices and parameter settings to determine the ``best'' setting for a particular workload. Workloads which seem promising are web server, scientific workloads [Miller91], and database benchmarking workloads.
Many thanks to Bruce Hillyer for many interesting conversations.
To validate the model, we ran a set of simple microbenchmark workloads, collecting traces of both file system and disk events. From these traces, we determined the mean disk and application-level response times for a variety of synthetic and real workloads. The results in this section are presented for the machine with the slower bus.
We created simple workloads which opened files, read them sequentially, and closed them. We recorded only the reads, i.e., not the open and close operations. We varied the request size and size of the file (which, in turn, varied data_span and run_length). Our workloads have a closed arrival process; files greater than 96 KB spanned at least two cylinder groups.
We ran our workloads using one process to access a single file; we repeated the experiments 100 times and averaged to compute the measured FSRT. Table 3 includes the measured and model-computed FSRT using equations (4) and (5), as well as the relative errors of the model. In all but one case the model's estimate is within 4% of the measured result; when reading 32 KB of a 64 KB file the model error is 9%, which is higher, but still quite good for an analytic model of this type.
| request size (KB) | file size (KB) | measured EFSRT] (ms) | computed E[FSRT] (ms) | error |
|---|---|---|---|---|
| 8 | 64 | 2.16 | 2.16 | 0% |
| 16 | 4.15 | 4.31 | 4% | |
| 32 | 7.88 | 8.62 | 9% | |
| 64 | 17.41 | 17.24 | 1% | |
| 8 | 128 | 2.70 | 2.69 | 1% |
| 16 | 5.41 | 5.37 | 1% | |
| 32 | 10.74 | 10.74 | 0% | |
| 64 | 21.08 | 21.48 | 2% | <
We then reran our experiments with multiple concurrent processes, each accessing a different file with the same workload specification (i.e., same request size and same file size). All of the files were opened at the beginning of the experiment; the files which were used during one experiment run were randomly chosen among a set of files that spanned the 4 GB disk. We flushed the disk cache between each of the 50 experiment runs. Table 4 presents our results using equations (4) and (5). We see that the model's error is 6% or less in all cases.
| number of files | request size (KB) | file size (KB) | measured E[FSRT] (ms) | computed E[FSRT] (ms) | error |
|---|---|---|---|---|---|
| 2 | 8 | 64 | 8.80 | 8.80 | 0% |
| 16 | 17.27 | 17.61 | 2% | ||
| 32 | 34.89 | 35.22 | 1% | ||
| 64 | 68.96 | 70.43 | 2% | ||
| 3 | 8 | 64 | 12.82 | 12.90 | 1% |
| 16 | 25.60 | 25.81 | 1% | ||
| 32 | 50.85 | 51.61 | 1% | ||
| 64 | 99.98 | 103.23 | 3% | ||
| 4 | 8 | 64 | 24.61 | 23.09 | 6% |
| 16 | 49.16 | 46.17 | 6% | ||
| 32 | 98.10 | 92.35 | 6% | ||
| 64 | 193.86 | 184.70 | 5% | ||
| 8 | 8 | 64 | 43.83 | 43.52 | 1% | w
| 16 | 87.54 | 87.04 | 1% | ||
| 32 | 174.06 | 174.08 | 0% | ||
| 64 | 344.04 | 348.16 | 1% | ||
| 16 | 8 | 64 | 77.96 | 79.50 | 2% |
| 16 | 155.48 | 159.00 | 2% | ||
| 32 | 308.20 | 318.01 | 3% | ||
| 64 | 604.90 | 636.01 | 5% | ||
We modified the file system to disable prefetching and reran our single file experiments. Table 5 contains our results using equations (4) and (5) with E[disk_request_size] = BlockSize. The maximum relative error is 7%.
1 The previous disk model includes additional workload parameters that support specifications of spatial locality; these are not needed for our current model since we assume that the files are accessed sequentially. The earlier disk model also supports a read fraction parameter; in this paper, we only model file reads.
2 With the file system performing prefetching, there will be four disk requests having a mean disk request size of 16 KB.
3 We are in communication with Seagate in an attempt to determine why we are seeing this behavior.
|
This paper was originally published in the
Proceedings of the 1999 USENIX Annual Technical Conference, June 6-11, 1999, Monterey, California, USA
Last changed: 1 Mar 2002 ml |
|
