Next: Scalability
Up: High-Performance
Caching With The Previous: Implementation Techniques
In two throughput experiments, get requests for objects of 10K and 1K size are generated at the highest possible rate. A single physical client sends requests for randomly chosen virtual clients. (The Ethernet driver and the hit-server software are constructed such that, provided the utilized bandwidth does not exceed that of one card, there is no measurable difference between the packets coming through a single or through multiple cards.) To ensure an infinite burst, the request generator does not wait for a request to be completed. Avoiding the request-generation problems mentioned in [1], this method is good for generating up to 161,000 requests per second. To be sure to saturate the hit-server in a realistic way, we send requests with random gaps such that the hit-server gets slightly more requests on average than it completes. For the experiments, all objects were resident in the hit-server so that no miss-server communication was required.
For 10K objects, we achieve a throughput of 594Mbps with the current hardware, 7,000 transactions per second. For 1K objects, the bandwidth is 304Mbps, approximately 36,000 transactions per second. Note that all delivered data is authenticated. Corroborating these results, our video-clip server can serve up to 402 clients with different MPEG I video clips (1.5 Mbps) simultaneously.
The crucial question is of course whether our approach performs significantly better than conventional server architectures. Therefore, we compare Lava with some other research systems and commercial Web servers in our envisioned LAN scenario (many NCs in a local cluster). The reader should note that the results cannot simply be extrapolated to other application fields, e.g., wide-area networks. In particular, the systems are not functionally equivalent: e.g., the commercial Web servers support TCP clients but cannot be customized like the Lava architecture.
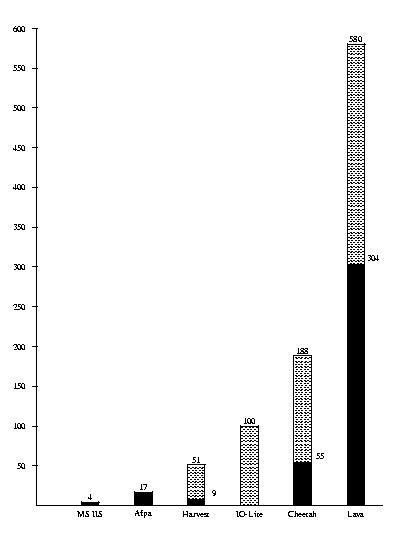
Figure 5 illustrates that for our LAN-based application Lava's hit-server offers an order-of-magnitude increase over conventional systems. We report net data throughput, i.e., do not count headers etc.
The numbers for Harvest [3] and Cheetah are taken from [11] and converted to Mbps. Both systems run on a 200 MHz PentiumPro machine like the Lava hit-server. Harvest runs on top of the BSD operating system, Cheetah on top of MIT's Xok system. IO-Lite [16] runs on a 233 MHz Alpha station with two 100Mbps network adapters. For comparison with industry-standard servers, we include numbers for Microsoft's Internet Information Server 4.0 running on a 166 MHz Pentium with Windows NT 4.0. Afpa [15] is an NT-based server running on a Pentium 166 processor. Both the MIIS and Afpa peformance have been measured in our lab by eliminating all client and network bottlenecks and increasing load until server was saturated. Similar to our experiment, the measurements for Cheetah, Harvest, MIIS, and Afpa are based on a LAN with no competing traffic; get requests are always served from the systems' respective main-memory caches. All systems implement the HTTP functionality; for Lava however, the client library translates HTTP requests to object-protocol requests on the client side.
Figure 5: Server Throughput. Net
data throughput in Mbps for get operations. (Headers, checksums,
etc. are not considered to be net data.) Black bars denote the
throughput for 1K objects, shaded bars for 10K objects. All
systems are measured on a local area network and deliver data
from their respective main-memory object cache.
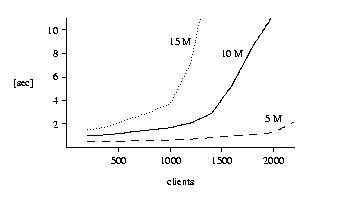
Based on the get-throughput experiment, we simulated a system where a hit-server is used as a boot server for 1000 NCs. For booting, each NC had to download an individual set of objects, together 10Mbyte per NC. We assumed that all 1000 NCs are turned on within the same 5-minute interval, equally distributed over time. We further assumed that each NC, once it is booted, starts working and then every second gets a 20K object. When a user turns on her/his NC, how long would (s)he have to wait until the 10M of boot data are downloaded? We found an average boot latency of 1.7s with a standard deviation of 0.9s (see Figure 6).
Figure 6: Average Boot Latency. All
clients boot within the same 5-minute interval. Boot data is
client-specific but of equal size for all clients (5M, 10M, or
15M).
Miss handling does not substantially degrade the hit-server's throughput, since most of the work (loading the object) has to be done by the miss-server. Only during transferring an object from the miss-server into the hit-server, the hit-server's delivery rate decreases by 18%, basically because the miss-server communication consumes 100Mbps from the total transfer bandwidth. (Transferring a 1M object takes approximately 0.1s.) Table 2 shows miss costs relative to hits for a single-disk Linux file system used as miss-server.
Table 2: Hit/miss costs. The miss
server file system runs on a 166MHz Pentium with a Caviar 33100
disk. All data reflect ideal situations in which requests are not
delayed by competing requests. Congestion at the miss-server or
at a hit-server's Ethernet card would increase the latency. For
the bandwidth ratios, we assume that the hit-server concurrently
delivers objects of the same size on all cards.
For local networks, the throughput experiment gives some evidence that the Lava architecture enables an order-of-magnitude larger server/NC configurations than conventional server architectures. Whether the architecture can be modified to work efficiently in a wide area network is an open research problem.
Next: Scalability Up: High-Performance Caching With The Previous: Implementation Techniques
Vsevolod Panteleenko