
Wilfredo Sanchez, Apple Computer
Mac OS was developed in the early-1980s around the idea of providing the best possible user experience. Apple succeeded in making Mac OS a best-of-breed operating system for personal computers: Mac OS has set the standards against which modern graphical user interfaces are now modeled. The primary alternative to Mac OS at the time was Microsoft's DOS, which ran on IBM PCs. Mac OS was able to provide the functionality that DOS provided via a visual model which has proven to be much easier for the lay user to understand than the command-driven interface employed by DOS and other systems such as AT&T's Unix. Tight integration with the underlying hardware has allowed the Macintosh platform to extend the experience beyond the software and into the actual management of the machine, with plug-and-play device support and "out of the box" support for many devices. The Macintosh led the way to such technologies as desktop publishing.
Unix has evolved from a different set of goals. Unix has been popular in academic and engineering environments, often used on high-end servers and workstations. Developers at U. C. Berkeley and other academic institutions have used Unix as a testbed for many research endeavors which have resulted in important computing technologies such as TCP/IP. Unix machines were typically shared by many users, requiring support for individual user accounts which could be utilized simultaneously on the same machine. Unix's early exposure to all of these advances lead to a deep understanding of how various subsystems interact, resulting in a relatively robust and modular system. Unix systems served as the basis and continue to support much of the infrastructure for today's Internet.
Unix derivatives such as Sun's Solaris, Cal's BSD Unix, and later Linux have grown to serve key roles as network servers. DOS was eventually replaced by Windows, which sports some of the user interface features pioneered by Mac OS such the desktop, as well as some of the underlying ideas behind Unix such as preemptive multitasking. While Unix systems remain in the lead for reliability and scalability, and Mac OS continues to push user interface innovation forward, Windows has successfully narrowed the gap in both areas.
Mac OS X is Apple's effort to create a best-of-both-breeds operating system which directly leverages the advances and experience Apple has in the user experience arena and the well-established power of BSD. Mac OS X begins with a BSD foundation called Darwin. On Darwin we build the programming toolkits from Mac OS which we call Carbon, which in turn enables us to layer on the new user interface known as Aqua. Carbon also provides a straightforward transition strategy for our existing application base. We also provide a toolkit called Cocoa, which is an object-oriented API derived from NeXT's OpenStep.
This makes for an interesting system architecture. The ideal result is a system that can be the sort of reliable server platform we use today to host high-volume web sites, file services, network gateways, and engineering computation services while also being the simple to use home computer platform of choice. This is a daunting task, because the server platform goals mandate a certain level of complexity (high security, performance tuning parameters, various network servers, etc.), while for most home users, simplicity overrides other concerns.
Unix and Mac OS have evolved independently of each other, and there are fundamental assumptions made in one system which cause numerous failures in the other. The capabilities of the available filesystems, the networking protocols, and the user/system model are profoundly varied, often in ways which cannot be rectified without changing the architecture of system components. Additionally, people use the systems in very different ways and expect different behavior from them.
This paper will discuss some of the issues which have arisen at Apple in the process of combining these disparate environments and some of the solutions that were used to make things work well in Mac OS X. There have been many such issues, and in the interest of brevity, we will visit two key areas here: filesystems and multiple user support. Examples given do not go into a great deal of detail, but enough information is provided to give the reader an idea of the problems and our attempt at a solution.
The use of filesystems demonstrates both implementation and semantic problems between the Unix and Mac environments. We'll start with the implementation issues, which is the obvious material.
The filesystems used in Mac OS are the Mac OS Extended filesystem, also known as HFS+ and its predecessor the Mac OS Standard file system, or HFS (Hierarchical File System). Both filesystems are supported in Mac OS X, though HFS is support is only provided for compatibility and users are encouraged to use HFS+ for new volumes.
The HFS+ volume format, unlike the HFS volume format, fortunately provides storage for Unix-style meta-data (eg. owner and mode bits). This made it a lot easier to enable the use of HFS+ in the Darwin environment. However, a few incompatibilities still exist.
HFS+ is a case preserving, but case insensitive, filesystem. That is, the case of file names is remembered, but access to file names with varying case will yield the same file, and file names which vary only in case are not allowed in any given directory. Typical Unix filesystems are, in contrast, case sensitive. At the start of the Rhapsody project, which preceded the current Mac OS X work, we had anticipated that this would be a big problem. Later, when we started using HFS+ as the primary filesystem in Darwin, we found surprisingly few problems resulting from this behavior, and those which we do find tend to be trivial to fix. We have yet to encounter a problem in this area which requires a complex solution.
Another obvious problem is the different path separators between
HFS+ (colon, ':') and UFS (slash, '/').
This also means that HFS+ file names may contain the slash character
and not colons, while the opposite is true for UFS file names. This
was easy to address, though it involves transforming strings back and
forth. The HFS+ implementation in the kernel's VFS layer converts
colon to slash and vice versa when reading from and writing to the
on-disk format. So on disk, the separator is a colon, but at the VFS
layer (and therefore anything above it and the kernel, such as libc)
it's a slash. However, the traditional Mac OS toolkits expect colons,
so above the BSD layer, the core Carbon toolkit does yet another
translation. The result is that Carbon applications see colons, and
everyone else sees slashes. This can create a user-visible
schizophrenia in the rare cases of file names containing colon
characters, which appear to Carbon applications as slash characters,
but to BSD programs and Cocoa applications as colons.
HFS+ lacks support in the volume format for hard links, a standard feature of UFS. Initially, the attempted creation of a link to a file would yield a "not supported" error. We had discussed some "80%" solutions, such as creating symbolic links instead, but the semantics of symbolic links are significantly different. For troubleshooting reasons it is preferable to fail at link creation time than at some later time due to problems related to these semantic differences. The problem is that there is a significant amount of software which breaks if hard link creation fails, and some of that software needs to be redesigned if hard links cannot be used. In order to accommodate this software, we now emulate hard links by creating a "kernel-level" symbolic link which is visible only to and interpreted by the HFS+ filesystem. This was necessary due to the lack of support in the volume format. The resulting behavior is very similar to that of hard links when viewed from above the kernel, though they are relatively inefficient in comparison.
UFS, on the other hand, does not support file IDs, which is a feature of HFS+. File IDs are persistent handles to a file, and can be used to access a file in a manner similar to which one uses paths in Unix. The nice thing about file IDs is that once the ID for a file is obtained, the file can be renamed or moved anywhere on disk and still be found and opened by the holder of the ID, and file access by ID is faster than access by path, as it avoids the path lookups. Mac OS aliases are similar to symbolic links, with the addition of alternative means of finding the file. Because aliases include the target file's ID, moving the target file does not break the alias as it would a symbolic link.
One of the biggest problems is the lack of complex file support in most Unix filesystems. HFS+ allows for a file to have multiple data streams: one, the data fork, contains the actual file data, and another, the resource fork contains additional resource data. (At the filesystem level, this is really just two files which happen to share a name.) The volume format also allows for arbitrary named file attributes (similar support is in UDF, NFSv4), though the neither Mac OS 9 nor Mac OS X support the use of this feature in the file format.
This has often been a source of compatibility issues between Mac OS and other platforms in the past. When transferring files via the Internet, they usually need to be encoded in a format such as MacBinary, which will combine both streams into one, so that it can be served by a web or FTP server. (Servers which run on Mac OS can do this as needed.)
There were several proposals for how to present complex files to
BSD clients which open() them. One was to combine the
two streams into AppleDouble format. This has the advantage of
containing all of the data in the complex file, and programs like
cp could work properly. The problem then is that if one
were to open a complex C source file in emacs they'd see not only the
program text, but also some weird encoding information and whatever
resource data that was put there by a Carbon application. A fatal
problem with this scheme is that part of the file data (the encoding
info) is creates by the filesystem, and isn't really part of the file
data, and should therefore not be editable. The non-lossy aspect of
this solution is what drew us to is, but the complications turned out
to be too substantial.
The present mechanism presents the data fork to the BSD client a
file is opened by name. If the resource fork is desired, it can be
read by appending a known string to the file path. For example
"foo/bar" gets you the data for file bar, but
"foo/bar/.namedfork/resource" will get you the resource
fork for bar. (The actual appended string may change.) Note that the
file is not somehow acting as a directory; it is not listable, and
stat() calls still show it as a file. This mechanism can
be carried to other filesystems with complex files, such as UDF. (UDF
also has allows attributes for directories.)
The are flaws in this plan as well. Most Unix software will only
see the data fork of a file, so "cp foo bar" will result
in a new file bar which is missing the resource data from foo (if
there was any). Backup and archiving software may also lose data. We
still have the problem of sharing files with systems that don't
support complex files. Mac OS X will continue to support complex
files, but we are moving away from their use in order to increase our
ability to operate in a heterogeneous environment.
A third option which we did not explore is to show the two forks
are separate files altogether. This is similar to some AppleShare
implementations on Unix, which export a Unix filesystem as an
AppleShare volume. When a file "foo", written by a Mac
OS client is viewed from the Unix side, there is another file (usually
named in a convention similar to ".foo.resource" or
".resources/foo>") which contains the resource data. If
these servers are also serving Unix clients (including local access),
which is often the case, files tend to get moved around in the Unix
side, and the resource file is left in the old location. The result
is an effective loss of the resource data and a need somehow to manage
(periodically clean up) these disassociate resource files. The HFS+
filesystem can probably address this problem by magically moving the
resource file along with the data, but strange behavior of this sort
tends to produce bugs, and this approach didn't seem to offer
significant advantages over the alternatives, and it got dropped.
Interestingly, the Carbon team has run into exactly this problem on UFS, where there is no obvious place to store resource forks, the present implementation of Carbon uses a similar solution as the one employed by Unix AppleShare servers.
Other filesystem problems are more subtle, and are due to different semantic expectations made by Mac OS and Unix systems as well as implementation details.
One example of this is the delete semantics of Mac OS as compared to the unlink semantics of Unix. In Mac OS, if you try to delete a file which someone else has open, the delete fails. This ensures that if another application is using your file, the file is not deleted from under that application. Unix achieves this by going ahead and removing the link, but the file continues to exist while it it open (though there is no longer a way to open that file). There are good arguments to be made for either method, and some Mac OS programs rely on the Mac OS behavior (files are sometimes used as a semaphores), while many Unix programs expect unlink to always succeed (one trick in the Unix world is to open a file for writing and then unlinking it so as to obtain a private bit of filesystem-backed memory to scribble on).
It is worth noting that the difference is behavior is in part due to the implementation of the respective filesystems. In UFS, meta-data is store with the file's inode, and inodes are stored separately from file data. In HFS+, the file meta-data is stored with the file data; there is no inode. Removal of the file in HFS+ therefore means removal of all access to the file. The unlink behavior in UFS come naturally from the separation of data and inodes; you simply delete the file, but keep the inode around as long as it is in use. On the other hand, one can do really fast searching of a volume for files with a given name in HFS+ because of how its storage is layed out. What is interesting here is that implementation details can lead to ideas and extensions which may not have been part of the original design.
In order to handle the differing semantics, a delete()
system call was added to BSD so that we have both semantics available.
Typically, Unix programs will call unlink() and Carbon
applications will call delete(). An unlink will always
succeed, so it is still possible for a Carbon application which has a
file open to lose that file when it is closed, if a BSD program
unlinked it. This is acceptable because the goal is to allow Carbon
programs to continue to cooperate with each other as designed, and BSD
programs don't usually delete files belonging to a Carbon program, so
the software tends to work as expected.
We should also be aware that while the primary goal here is to get Mac OS X to operate properly with these differing software stacks, we still have millions of Classic Mac OS users and these users need to share files and media with our new Mac OS X users. One example of trouble is Unix permissions on HFS+ volumes. Mac OS 9 will not read or write Unix meta-data; though HFS+ supports it, Mac OS 9 will ignore those bits completely. That's acceptable until you start moving a disk between Mac OS 9 and Mac OS X systems (or if you dual boot your system and also, to a lesser degree, if you run the Classic environment in Mac OS X).
This may be a problem if you expect permissions to be enforced
across systems, but if you are handing someone your disk or booting
into another OS, you are bound to get dissapointed eventually. A more
interesting situation, however, occurs when files get created in Mac
OS 9 and are seen later by Mac OS X. The files have no Unix meta-data
set, and therefore no permissions or owner. User 0
(root) and group 0 (wheel) are reasonable defaults, but a
file mode of 0000 is almost certainly not what the user
wants. Fortunately, we are able to distinguish between "no meta-data
set" and zero values for mode and owner info. What we do in this case
is present the owner, group, and mode as some reasonable default,
which is determined by examining the permissions on the directory node
on which the filesystem is mounted. Note that the actual permissions
on disk remain unset unless someone sets them explicitly; an unmount
and remount with a different default will effect the mode of such
files. This allows for a flexible administration of the default mode
such that some disk default to more open permissions than others, as
desired.
As mentioned before, HFS is also supported. This is primarily to allow for the transfer of data to and from removable media and existing hard drive volumes which are formatted for HFS. Further constraints are found here, but this is similar to DOS filesystem support in Linux, and for the file transfer, HFS presents few problems. Because HFS does not store mode bits, a default is used in the same manner that we use for unset modes in HFS+ files. The significant new problem here is that files transferred to and from an HFS volume will lose permission information.
Above the kernel, there are file name conventions in Unix which
have manifested as limitations and bugs in various Unix software. UFS
allows any printable character in a file name, but many Unix shell
scripts and programs have problems with files that contain "special"
characters such as whitespace and punctuation. In Mac OS, users have
not been subject to this limitation in the system and should not be
subject to them in Mac OS X. One good example of this is the
make command, which uses whitespace as a file name
delimiter, making it difficult to produce program output called, for
example, Netscape Navigator®. There is no reason why
this has to be the case, but it is an unfortunate historical artifact
of how Unix grew up.
As mentioned above, Unix has a heavy reliance on file paths. One
of many such examples is the Bourne shell: if the sh
program does not exist in /bin, the system won't even
boot properly. While Mac OS is not immune from such problems, it does
allow the user to relocate or rename even such important items as the
System Folder. This is a particularly significant issue because,
although we use BSD as the core system software, we do not want to
require our users to understand how BSD works. Ideally, the typical
Macintosh user does not even know that BSD is there. The very
presence of such folders as "usr" and "etc"
on disk is therefore awkward, and we hide those directories and their
contents at the application level in order to avoid confusion as to
why they are there and cannot be moved or deleted. One idea is to put
all system files into a Mac OS-style System Folder, and make that
folder opaque to the user. This requires that there be other methods
for managing the system software than allowing users to poke in there
themselves, and we still have the problem that standard Unix paths are
required to exist at the root level of the boot volume. This is still
an area which we are actively working to improve upon.
The original Mac OS had a wonderful feature that applications were kept in one file (though both forks of that file were sometimes used). You could therefore drag one icon from your install floppy onto your hard disk or another floppy, and you were done. You could drag the one icon to the trash, and get rid of that program. Over the years, we have gotten into a model where there are several files to deal with. Most of the application files are kept in one folder, but applications also put various files into parts of the System Folder, such as preferences, system extensions, and fonts. A product like Adobe Photoshop® installs many files onto your system: there is the actual executable program; a folder with plug-ins such as filters, file translators, and effects; another with color palette, and brushes and patterns; help files; and samples.
By BSD conventions, which are as reasonable as any Unix conventions, files are located according to function; you might put the program in/usr/bin, the icons in /usr/share/photoshop,
the plug-ins in /usr/libexec, and so on. While it has
certain advantages, the problem with this approach is that files are
scattered around the disk, making it somewhat difficult to install and
uninstall software. This is addressable by using a package installer
scheme with receipts and so on, but that is easily broken if the user
uses different installers or bypasses the installer by unrolling a tar
archive.
One of the neat ideas we inherited from NeXT is the notion of opaque directories, which at the user level behave more like files than folders. We call these "bundles," and use them in a variety of ways whenever we need to encapsulate a set of files into one user-visible object. You can put all application data into one such bundle with several subdirectories and files in it. The program executable goes in there, as well as any additional resources and plug-ins. The Finder treats the bundle as one opaque object which can be drag-installed, just like the good ol' days.
We follow a similar scheme for system-wide libraries. Instead of
putting headers in /usr/include, libraries in
/usr/lib, and additional resources wherever they go, we
create a single framework bundle which encapsulates everything needed
for that library. The compiler knows how to find specific files in
the framework, because each type of bundle has a well-defined
structure.
Unix has its roots in environments where computing machines were expensive and rare, which mandated that they be shared. It was important that computational resources be utilized as well as possible in order to amortize cost, and give everyone involved a chance to get some cycles in for their respective projects.
Therefore, Unix had an early notion of timesharing, and features like multitasking on a single processor, user accounts, and security became important early on. Note that security has many aspects. One important aspect is some level of protection for one process from another process' mistakes. Because time was often critical, it was readily apparent that one running program's ability to (usually accidentally) impede or destroy the progress of another was unacceptable. This lead to the need for preemption and separate, protected address spaces for each process. Other security mechanisms such as file permissions to some degree extend naturally from this basic inter-process security; each process runs on behalf of a given user, and is restricted to that user's permissions for access to files and certain system calls. The private memory allocated to each process ensures that one running program cannot hijack another's memory and affect its execution.
When the Macintosh was introduced, it was to be the first truly personal computer. As such, it has very different needs. These machines were designed so that one person could buy and use them (hence the term personal). There was no need for time sharing as there would not be more than one console, and users would only need to run one program at a time. The hardware was much more modest. The original Mac OS could barely squeeze into the 128K of available RAM.
It later became clear that running a few programs side-by-side could be very useful, but this wasn't really true until personal computers had gained enough power and memory for this to be feasible. (Aside from computational power, you also needed such things as larger-screen displays.)
It is easy in hindsight, given the spiffy computers we have today, to look at Mac OS today and think that some of the original decisions which we still carry with the system were not well considered, but that would be an grossly unfair assessment of the situation. Today, we find greater computational resources in "embedded systems" than was in the first Macintosh. Mac OS was designed to devote the limited resources of the personal computer to one user.
Mac OS has had some notion of file permissions since the introduction of file sharing, but that model does not extend to local volumes. Mac OS 9 added support for multiple user logins, so that each user can have his or her own preferences remembered between logins, independent of the rest, and it has some file security. However, this support is rather superficial compared to Unix. There is still a single shared address space, and all programs have device-level access to the hardware. Even so, it is sufficient for some uses, particularly in light of the fact that only one user can use the machine at a time.
In Unix, users are a concept understood even by the kernel. Mac OS software has never had to deal with such a pervasive user model before, and in Mac OS X the challenge is to introduce this feature without breaking existing software products that our users rely on.
It is also important to note that users are accustomed to having a great deal of control over the system without many barriers, but in BSD, even something as seemingly trivial as setting the time of day requires "superuser" access. Now there are files on your disk which you can't move around, and folders you can't even open to look in. This appears to require a great deal of user education, which is not desirable for a system that is supposed to be intuitive to use.
Some of this, however, is intentional. We want to move away from the model where the casual user fiddles around with the system software on a day-to-day basis. This was necessary in Mac OS 9 because many software packages install (or ask the user to install) software such as system extensions into the system folder. Mac OS X discourages this sort of manipulation of the system software and instead tries to provide other (less destabilizing) methods by which developers can extend the system software.
In general, the issue of trading off user convenience vs. system security is a complex one. A lot of this should probably be left for the user to decide, depending on what the machine is being used for, and such factors as its network connectivity. However, a lot of these tradeoffs can be avoided by writing smarter software, which lets the system's security model fit more naturally into how the user interacts with the system. It is important to present security as a feature and not an annoyance, as the annoyed user is likely to disable security altogether, perhaps despite the risks. This issue is system-wide, and needs to be revisited periodically as we move forward.
Another problem we have run into is a Unix problem which is not specific to Mac OS X at all, but is one that Unix systems have not yet felt compelled to address.
Unix filesystems store owner and group information on disk by writing the user's and group's system ID (typically a natural number) with each file's meta-data. On any given workstation, this name-to-ID mapping is always consistent (though not always one-to-one). If one were to take a disk from one computer and attach it to another, some hard problems arise. What do you do with the user/group IDs which are on the disk? If the two machines are on the same NetInfo network, and the user and group IDs on the disk are in the parent NetInfo server, you are in good shape, since they will be consistent across the hosts. However, if the machines are in different NetInfo domains (more often there will probably only be the local domain, so this is the most likely scenario), then these IDs may have no useful meaning at all on the second machine. Even more difficult, some IDs may be consistent (eg. system user IDs), while others are not, and there is no reliable way to know which IDs are correct.
There are many permutations of how this problem may affect file permissions. An ID on one host may map to a different user on the other, or to no user at all. A person may have an account on both machines, but the user name and/or ID may be different on each.
Our solution here is truly nontrivial. We keep track of volumes which are "local" to the running system. When a new volume is introduced, we ask the user to decide what action to take. We can:
chgrp() calls are ignored. Ignore setuid bits. This
is similar the the behavior of DOS filesystems or HFS (not HFS+)
volumes, which don't have any storage for users and groups anyway.
chmod() and
chgrp() settings will stick.
The problems described above are all solvable in Mac OS X because we can change both the Carbon and BSD implementations to accommodate each other, but one of the reasons that we need Carbon in the first place is that the existing Mac OS Toolbox cannot live well on the new Core OS. This brings about a much harder problem: what do we do about the thousands of software titles, already in use by millions of our customers, which were written and built against the old Toolbox?
The Classic environment in Mac OS X creates a virtual machine inside of Mac OS X which boots a largely unmodified version of Mac OS 9. Applications which are built for Mac OS 9 and have not been "Carbonized" run in this environment. The Classic environment replaces the hardware abstraction layer in Mac OS 9 with a series of shims that pass requests to parts of Mac OS X. For example, a memory request in Mac OS 9 gets fulfilled by a memory request in the Darwin kernel. Mac OS 9 can thereby use resources managed by Mac OS X.
The resource sharing has varying limitations. For example, if Mac OS 9 wants to mount a disk, Classic can accomplish that by creating a shim at the SCSI level which are then handled by I/O Kit in the Darwin kernel (arrow A in figure 1). Because Classic is making raw SCSI requests, that disk cannot be mounted by BSD on the native side, or there will be serious problems, so the disk cannot be shared by both native and Classic applications. This is, in fact the way disks were initially accessed by Classic.
Another option is to store a disk image in a file on the Mac OS X filesystem. This provides Mac OS 9 with disk storage without taking a drive away from the native environment (arrow B in figure 1). One advantage here was that while Mac OS 9 only knows about HFS and HFS+ filesystems, this disk image could live on any filesystem provided by BSD in Darwin. A third implementation shimmed the Mac OS 9 disk driver to that in Darwin (arrow C in figure 1), removing direct SCSI access and enabling the use of a single partition on a disk, rather than taking over the whole device.
Lastly, filesystem calls in Mac OS 9 could be passed to the Mac OS X HFS+ filesystem, enabling the sharing of files on HFS+ filesystems between native and Classic applications, which is now the preferred mode (arrow D in figure 1). We could take things a step further, and have Classic call into the Carbon library (at this point, we are still making system calls to the kernel), which can emulate HFS+ semantics on several filesystems. It might be possible, then, to have Mac OS 9 in Classic using files on UFS and NFS volumes while remaining ignorant of these filesystems.
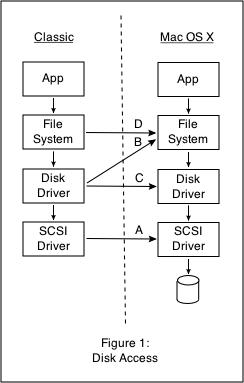
There are tradeoffs made as you move along. Most applications access files via standard API, but not all do. For example, Norton Disk Doctor wants to talk to the disk driver. When we've move up to arrow D, the Mac OS 9 disk driver is out of service, and Disk Doctor will not work. Similarly, Apple's Drive Setup application goes straight down to the SCSI level, which is absent in the B, C, and D cases.
Ironically, the Macintosh's historically closed architecture played a key role in making this possible. Because details about hardware were not public, and direct hardware access has been closely guarded in Mac OS 9, application writers never found it convenient to write around the standard APIs, and this use of the layering of the system works for the vast majority of applications.
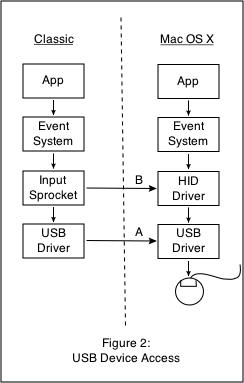
The same strategy worked for other devices. USB devices can be shimmed at the USB driver level, which gives Mac OS 9 exclusive access, or at the HID layer, which allows sharing with native applications (arrows A and B in figure 2). Screen usage is done via Core Graphics (Quartz), which works rather nicely: Mac OS 9 can claim window regions, which are then managed by the Mac OS X window server.
Wilfredo Sánchez is a 1995 graduate of the Massachusetts Institute of Technology, after which he co-founded an Internet publishing company, Agora Technology Group, in Cambridge, Massachusetts; he then worked on enabling electronic commerce and dynamic applications via the world wide web at Disney Online in North Hollywood, California. Fred is presently a senior software engineer at Apple Computer in Cupertino, California. He works primarily on the BSD subsystem in Mac OS X as a member of the Core Operating System group, and as engineering lead for Apple's open source projects. Fred is also a member of the Apache Software Foundation, a NetBSD and FreeBSD developer, and a contributor to various other projects.
Patrick W. Dirks, the Mac OS X filesystems technical lead at Apple, and Brent Knight from the Classic team contributed significantly to this paper. Errors, however, are Fred's doing.
An updated version of this paper will be available online at
https://www.mit.edu/people/wsanchez/papers/USENIX_2000/.