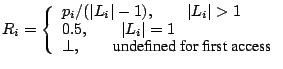| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX '05 Paper
[USENIX '05 Technical Program]
AMP: Program Context Specific Buffer Caching
Feng Zhou, Rob von Behren and Eric Brewer
Project website: https://www.cs.berkeley.edu/~zf/amp/
Abstract:
We present Adaptive Multi-Policy disk caching (AMP), which
uses multiple caching policies within one application, and adapts
both which policies to use and their relative fraction of the cache,
based on program-context specific information. AMP differentiate
disk requests based on the program contexts, or code locations, that
issue them. Compared to recent work, AMP is unique in that it
employs a new robust scheme for detecting looping patterns in access
streams, as well as a low-overhead randomized way of managing many
cache partitions. We show that AMP outperforms non-detection-based
caching algorithms on a variety of workloads by up to 50% in miss
rate reduction. Compared to other detection-based schemes, we show
that AMP detects access patterns more accurately for a series of
synthesized workloads, and incurs up to 15% fewer misses for one
application trace.
1 Detection (classification) Based CachingModern applications access increasing amounts of disk data and have widely varying access patterns. These access patterns deviate from traditional OS workloads with temporal locality. Recent work on detection or classification based caching schemes (2,5,4) exploits consistent access patterns in applications by explicitly detecting the patterns and applying different policies. In this paper, we present Adaptive Multi-Policy caching, a detection-based caching system with several novel features. One major aspect of the design of a detection-based caching scheme is the pattern detection algorithm. UBM (5) detects loops by looking for accesses to physically consecutive blocks in files. One obvious problem is that some loops are to blocks not physically consecutive. DEAR (2) detects loops and probabilistic patterns by sorting blocks by last-access time and frequency. Although it detects non-consecutive loops, it's more expensive and brittle against fluctuations in block ordering. PCC (4) resorts to a simple counter-based pattern detection algorithm. Essentially a stream with many repeating accesses is classified as looping. This scheme, although simple, risks classifying temporally clustered streams with high locality as loops. AMP features a new access pattern detection algorithm. It detects consecutive and non-consecutive loops and is robust against small reorderings. Its overhead is small and can be made constant per access, independent of working set or memory size. AMP is also novel in the way it manages the cache partitions. Both UBM and PCC evict the block with the least estimated ``marginal gain''. Because the marginal gain estimation changes over time, finding this block can be expensive. AMP, in contrast, uses a randomized eviction policy that is much cheaper and robustly achieves similar effectiveness. One decision differentiating these approaches is the definition of an I/O stream to do detection on. For example, UBM (5) does per-file detection and DEAR is based on per-process detection. AMP and PCC (4) do per-program context (referred to as program counter in (4)) detection. The basic idea is to separate access streams by the program context (identified by the function call stack) when the I/O access is made, with the assumption that a single program context is likely to access disk files with the same pattern in the future. This PC-based approach differs radically from previous methods and is the key idea in both PCC and AMP, although the two systems were developed concurrently and independently. Interested readers are referred to (4) and (7) for further motivations for this approach and application traces showing its effectiveness.
|
|
Table 1 shows that AMP detects the correct pattern each time. DEAR detects the correct patterns except for (c) and (f). The DEAR scheme requires two parameters, detection interval and group size. We set the detection interval to half of the stream length, so that DEAR does a single detection over the whole stream. Group size is set to 10. DEAR is quite sensitive to changes in the stream. For example, both (b)(c) and (e)(f) are pairs of similar streams. However DEAR succeeds for one but fails for the other in both cases. As discussed in section 1, the PCC detection scheme tends to mix locality with looping. Here it misclassifies three non-loop streams as loops. Actually it detects the highly temporally clustered stream (a) as looping.
We used trace-driven simulation to study caching performance of AMP. Only a subset of our results are shown here; our full results are presented in (7). All traces were collected on a 2.4 GHz Pentium 4 Xeon PC server using the tracing functionality of our AMP implementation. One difficulty we encountered was that (4) does not does not contain a detailed specification of PCC's partitioned cache manager. Hence, we implemented the PCC pattern detection algorithm and used AMP's cache management module. We believe this gives a fair evaluation of the detection algorithm because it should be orthogonal to the cache management algorithm. We call this hybrid scheme PCC*.
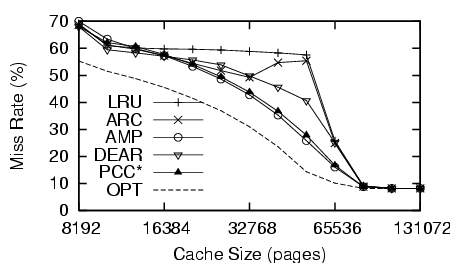
Figure 2 shows results for using cscope to look up 5 symbols in the index (sized 106MB) of Linux kernel source code. Because cscope does big looping accesses to the index file, DEAR, PCC* and AMP all perform similarly and much better than LRU and ARC, which see no improvement until the cache is large enough to hold the whole index file.
|
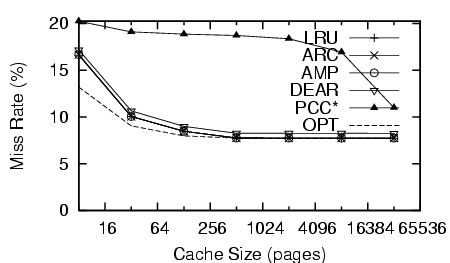
The trace scan (Figure 3) shows a pathological case for PCC*. In this trace, a test program walks the Linux kernel source once and reads each file three times. These ``small loops'' are classified as ``loop'' by PCC and MRU is used. AMP classifies these as ``temporally clustered'' because more recent blocks get accessed. Figure 3 shows that PCC* performs much worse than all others, including LRU.
|
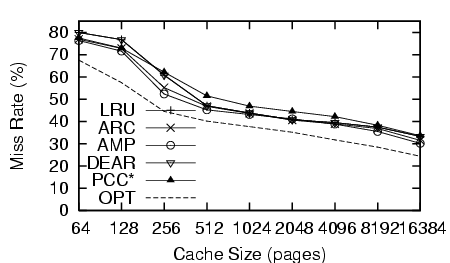
Figure 4 shows performance while building the Linux kernel. Since the accesses in this trace show a high degree of locality and include many small loops, detection based methods would cannot improve things by applying MRU. In reality, PCC* and DEAR show degradation compared to LRU/ARC. PCC classifies some ``small loop'' contexts as loops and loses hits. AMP detects these correctly and shows slight improvements over LRU and ARC.
Our final simulation test was of DBT3 (3), an open-source
implementation of the commercial TPC-H
database benchmark.
This a relatively large trace. The whole database is about 4GB, with
each query against a large portion of the database. It
is run on PostgreSQL 7.4.2. We ran only 16 of the 22 queries
because the other 6 take too long to finish (hours to days) due to
known issues with PostgreSQL 7.
At over 700M samples, this trace was too large for our simulator.
Hence we down-sampled this trace by a factor of 7, reducing it's
working set to ![]() of the original.
Figure 5 shows detection based
methods out-perform ARC/LRU again here. DEAR shows less improvement,
probably because the the complex mix of accesses from the database
process makes DEAR's process-based detection less
accurate. AMP and PCC* yield greater improvements and perform similarly.
For example, for a cache size of 52016 pages, AMP achieves miss rate
of 25.9%, compared with ARC at 55.4% and LRU at 57.6%, a reduction
of more than 50%.
of the original.
Figure 5 shows detection based
methods out-perform ARC/LRU again here. DEAR shows less improvement,
probably because the the complex mix of accesses from the database
process makes DEAR's process-based detection less
accurate. AMP and PCC* yield greater improvements and perform similarly.
For example, for a cache size of 52016 pages, AMP achieves miss rate
of 25.9%, compared with ARC at 55.4% and LRU at 57.6%, a reduction
of more than 50%.
Here we compare our AMP implementation with the default Linux page cache by benchmarking real applications. Our test machine was a Pentium 4 Xeon 2.4GHz server with 1GB of memory running Linux 2.6.8.1 with and without our AMP modifications.
|
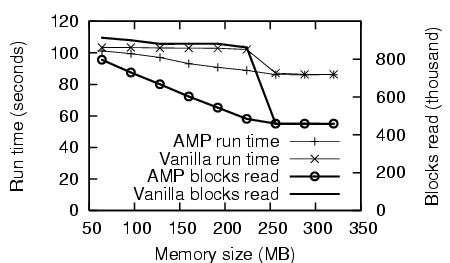
Our first test application was glimpse, a text-retrieval tool. We use the glimpseindex command to index the Linux 2.6.8.1 kernel source files (sized 222MB). The execution times and number of blocks read from disk are shown in Figure 6. AMP shows significant performance improvement over the Linux page cache. Run time decreases by up to 13% and the number of blocks read from disk decreases by up to 43%, both when memory size is 224 MB.
|
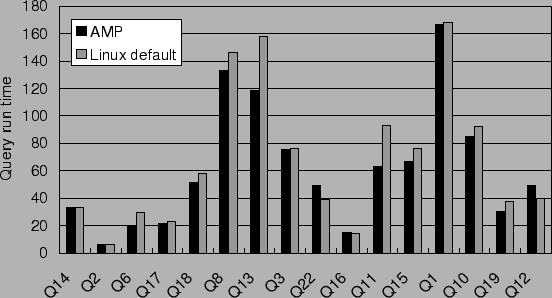
We also ran the DBT3 database workload, in the same configuration as our dbt3 trace. Figure 7 shows the execution times of queries on AMP and plain Linux. AMP did better in 11 queries and worse in 5 (Q14, Q2, Q8, Q22 and Q12) (reason under investigation). AMP shortens the total execution time by 9.6%, from 1091 seconds to 986 seconds. Disk read traffic decreased by 24.8% from 15.4 to 11.6 GB. Write traffic decreased by 6.5%, from 409 MB to 382 MB, probably due to lower cache contention.
We have presented AMP, an adaptive caching system that deduces information about an application's structure and uses it to pick the best cache replacement policy for each program context. Compared to recent and concurrent efforts, AMP is unique in that it uses a low-overhead and robust access pattern detection algorithm, as well as a randomized partition size adaptation algorithm. Simulation confirms the effectiveness and robustness of the pattern detection algorithm. And measurement results on the Linux prototype are promising.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons amp-usenix05.tex
The translation was initiated by on 2005-02-17
|
This paper was originally published in the
Proceedings of the 2005 USENIX Annual Technical Conference,
April 10–15, 2005, Anaheim, CA, USA Last changed: 2 Mar. 2005 aw |
|