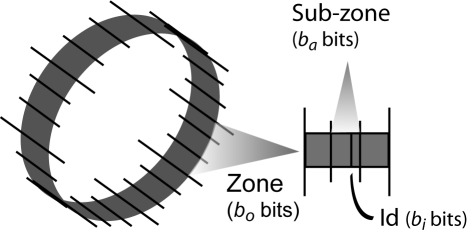A Phoenix host selects a subset of hosts to store backup data, expecting that at least one host in the subset survives an Internet catastrophe. This subset is a core, chosen using the Uniform heuristic described above.
Choosing cores requires knowledge of host software configurations. As described in Section 5, we use the container mechanism for advertising configurations. In our prototype, we implement containers using the Pastry [32] distributed hash table (DHT). Pastry is an overlay of nodes that have identifiers arranged in a ring. This overlay provides a scalable mechanism for routing requests to appropriate nodes.
Phoenix structures the DHT identifier space hierarchically. It splits
the identifier space into zones, mapping containers to zones.
It further splits zones into sub-zones, mapping sub-containers
to equally-sized sub-zones. Figure 8 illustrates
this hierarchy. Corresponding to the hierarchy, Phoenix creates host
identifiers out of three parts. To generate its identifier, a host
concatenates the hash representing its operating system
![]() , the hash representing an attribute
, the hash representing an attribute
![]() , and the hash representing its IP address. As
Figure 8 illustrates, each part has
, and the hash representing its IP address. As
Figure 8 illustrates, each part has ![]() ,
, ![]() ,
and
,
and ![]() bits, respectively. To advertise its configuration, a host
creates a hash for each one of its attributes. It therefore generates
as many identifiers as the number of attributes in
bits, respectively. To advertise its configuration, a host
creates a hash for each one of its attributes. It therefore generates
as many identifiers as the number of attributes in
![]() . It then joins the DHT at multiple points,
each point being characterized by one of these identifiers.
Since the hash of the operating system is the initial, ``most
significant'' part of all the host's identifiers, all identifiers of a
host lie within the same zone.
. It then joins the DHT at multiple points,
each point being characterized by one of these identifiers.
Since the hash of the operating system is the initial, ``most
significant'' part of all the host's identifiers, all identifiers of a
host lie within the same zone.
To build Core(![]() ) using Uniform, host
) using Uniform, host ![]() selects hosts
at random. When trying to cover an attribute
selects hosts
at random. When trying to cover an attribute ![]() ,
, ![]() first selects a
container at random, which corresponds to choosing a number
first selects a
container at random, which corresponds to choosing a number ![]() randomly from
randomly from
![]() . The next step is to select a
sub-container and a host within this sub-container both at
random. This corresponds to choosing a random number
. The next step is to select a
sub-container and a host within this sub-container both at
random. This corresponds to choosing a random number ![]() within
within
![]() and another random number
and another random number ![]() within
within
![]() , respectively. Host
, respectively. Host ![]() creates a Phoenix identifier by
concatenating these various components as
creates a Phoenix identifier by
concatenating these various components as
![]() . It
then performs a lookup on the Pastry DHT for this identifier. The
host
. It
then performs a lookup on the Pastry DHT for this identifier. The
host ![]() that satisfies this lookup informs
that satisfies this lookup informs ![]() of its own
configuration. If this configuration covers attribute
of its own
configuration. If this configuration covers attribute ![]() ,
, ![]() adds
adds
![]() to its core. If not,
to its core. If not, ![]() repeats this process.
repeats this process.
The hosts in ![]() 's core maintain backups of its data. These hosts
periodically send announcements to
's core maintain backups of its data. These hosts
periodically send announcements to ![]() . In the event of a
catastrophe, if
. In the event of a
catastrophe, if ![]() loses its data, it waits for one of these periodic
announcements from a host in its core, say
loses its data, it waits for one of these periodic
announcements from a host in its core, say ![]() . After receiving such
a message,
. After receiving such
a message, ![]() requests its data from
requests its data from ![]() . Since recovery is not
time-critical, the period between consecutive announcements that a
host sends can be large, from hours to a day.
. Since recovery is not
time-critical, the period between consecutive announcements that a
host sends can be large, from hours to a day.
A host may permanently leave the system after having backed up its files. In this situation, other hosts need not hold any backups for this host and can use garbage collection to retrieve storage used for the departed host's files. Thus, Phoenix hosts assume that if they do not receive an acknowledgment for any announcement sent for a large period of time (e.g., a week), then this host has left the system and its files can be discarded.
Since many hosts share the same operating systems, Phoenix identifiers
are not mapped in a completely random fashion into the DHT identifier
space. This could lead to some hosts receiving a disproportionate
number of requests. For example, consider a host ![]() that is either the
first of a populated zone that follows an empty zone or is the last
host of a populated zone that precedes an empty zone. Host
that is either the
first of a populated zone that follows an empty zone or is the last
host of a populated zone that precedes an empty zone. Host ![]() receives requests sent to the empty zone because, by the construction
of the ring, its address space includes addresses of the empty
zone. In our design, however, once a host reaches its load limit, it can simply discard new requests by the Phoenix protocol.
receives requests sent to the empty zone because, by the construction
of the ring, its address space includes addresses of the empty
zone. In our design, however, once a host reaches its load limit, it can simply discard new requests by the Phoenix protocol.
Experimenting with the Phoenix prototype, we found that constructing cores performed well even with an unbalanced ID space. But a simple optimization can improve core construction further. The system can maintain an OS hint list that contains canonical names of operating systems represented in the system. When constructing a core, a host then uses hashes of these names instead of generating a random number. Such a list could be maintained externally or generated by sampling. We present results for both approaches in Section 7.
We implemented Phoenix using the Macedon [31] framework for implementing overlay systems. The Phoenix client on a host takes a tar file of data to be backed up as input together with a host configuration. In the current implementation, users manually specify the host configuration. We are investigating techniques for automating the configuration determination, but we expect that, from a practical point of view, a user will want to have some say in which attributes are important.