
|
| Pp. 15–28 of the Proceedings |  |
This paper introduces the basic features that make up TrustedBSD, describes the goals and processes by which these are being accomplished, details a subset of the features, and reflects on lessons learned as well as future directions for work.
An early observation made during this process was that supposedly-equivalent security checks would often be implemented differently. For example, different access control checks were used for the two ways in which debugging can be attached to a process, ptrace() and the process file system. Little or no code sharing, combined with an incremental development style, has lead to inconsistent and undocumented protection behavior, especially in the areas of inter-process authorization and file system permission evaluation.
Correctness is clearly an important part in any security project; however, without appropriate tools to verify correctness, it can be difficult to achieve. Access control consistency (and hence abstraction), careful documentation, and extensive and rigorous testing are necessary to accomplish this goal.
POSIX.1e[9] Access Control Lists (ACLs) allow object owners to specify finer granularity protections for file system objects. The ACL implementation leverages the availability of a general EA service, and provides a high level of compatibility with the permission model. ACLs are not only a relatively simple implementation task, but are also a ``bullet feature'' expected by many operating system consumers, making them a particularly appealing target.
POSIX.1e capabilities decompose the root privilege set into several logical components, decoupling privilege from the UID of the process. Processes may manage the availability, inheritance, and effectiveness of capabilities, limiting the scope of damage due to compromise. This implementation leverages EAs to bind capabilities to binaries, and improved security abstractions to replace the superuser access control checks.
Free UNIX-like systems have traditionally lacked such features, which can provide higher levels of protection; mandatory policy enforcement is one of the determining features associated with the traditional trusted operating system. Many of the enforcement points for MAC already exist in FreeBSD by virtue of the existing security models, including the Jail[12] model, but improved labeling and access control abstractions, as well as the ability to store labels persistently in EAs, are required for most MAC policies.
The starting point for this work has been POSIX.1e, a withdrawn IEEE specification draft intended to provide portable interfaces for Access Control Lists, Auditing, Capabilities, Information Labeling, and Mandatory Access Control. As many of these topics are contentious within the security community, large parts of the draft are effectively unusable as they constitute a consensus on the need for a feature, rather than practical interface details needed for actual implementation. However, the ACL and Capability components of the draft are quite usable, with partial implementations of both widespread. We selected Draft 17, the final draft of the specification, as a starting point. We made extensions or modifications where necessary to disambiguate aspects of the draft, provide functionality not anticipated by the draft writers, or to handle non-POSIX and BSD-specific extensions.
POSIX.1e does not describe extended attributes (EAs), although a number of POSIX.1e implementations rely on EAs to provide storage to support its features. This includes SGI's Trusted Irix[18], FreeBSD, and now also Linux[8]. As EAs will likely be consumed by applications directly, as well as by kernel security services, adopting consistent application interface syntax and semantics is highly desirable. The POSIX.1e online discussion mailing list has provided a forum for the discussion of EA interfaces; a final interface has not been agreed upon, but there is a reasonable consensus on the desired semantics.
The mandatory access control interface described in POSIX.1e, on the other hand, may be too specific to the MLS and Biba MAC models, which each define a dominance operator, requiring a policy that orders labels. The interface also lacks a means by which user processes can host objects and enforcement points, but rely on the operating system to provide label management and policy service. There is substantial consensus in the broader community that more general access control primitives are required to support a broad array of flexible policy mechanisms, and that the POSIX.1e interfaces may provide a useful starting point for that work.
Working with existing models, where possible, offers substantial benefits in the form of application portability. It also allows for a faster design and implementation process, as there is greater understanding of the model (including its limitations), reducing development risk. Where portability standards do not exist, it is desirable to develop new standards, such as with EAs. Creating many divergent ``Trusted Sendmail'' implementations to account for many MAC interfaces, for example, is clearly undesirable, both from the perspective of increased workload, risk associated with reduced review, and divergent (and conflicting) security properties.
For many open source projects, the motivations for developers are different from those of closed source commercial products: they are highly motivated to do the work, but often have limited resources to bring about the results they seek. This can result in a ``many testers but few developers'' syndrome for features that are either less popular or technically difficult to implement. The volunteer nature of the work means that the model of success is often based on the degree to which the software is available and used, and the effectiveness in attracting new developers to a project, rather than monetary compensation.
The limitations of version control and collaboration tools often drive the organization of open source software projects that use them. For example, CVS's inability to effectively handle a three-tier development process (central repository, per-project repository, local development tree) makes it difficult to track the rapidly moving central FreeBSD source repository without pushing changes back into the central source tree. This further encourages the wide-spread open source technique of providing early access to work still under development, allowing for broader exposure of the code and therefore more effective testing. Providing early access to the EA implementation greatly facilitated the development of TrustedBSD features by permitting independent development of other features, otherwise made difficult by CVS's inability to handle a hierarchal model. Likewise, allowing early access to the ACL implementation, even though it was still partially complete, allowed for far broader testing and greater numbers of developers.
Releasing early and often during the development process often means submitting the necessary hooks to support easier development, such as reserving system call numbers and adding prototype interfaces. These techniques are appropriate where hooks and interfaces are intended to remain relatively static, but allow the feature under development to generate few modification conflicts even as the base tree moves forward. For example, a number of the TrustedBSD APIs appeared in the 4.x-STABLE FreeBSD release branch, although the underlying implementations were not present. The development of improved abstractions and modular service interfaces allows the development process to be further streamlined-as better abstractions are introduced, the changes to the base source distribution necessary to support new features get progressively smaller.
The open source development process also allows a new element to be introduced in the software portability process: direct code sharing to improve interface portability. This facilitates the development of parallel implementations in a number of ways: the code may be directly ``borrowed'' from another distribution if the licenses are compatible, direct inspection of parallel code can improve consistency and correctness, and it is possible to take advantage of the source code for third party tools relying on the service to perform testing. The TrustedBSD project has frequently made use of open access to other systems' source to understand the interfaces and implementation quirks of services on those systems. Implementing ACLs, for example, was greatly facilitated by the ability to recompile and test the Linux getfacl and setfacl tools on FreeBSD to determine that they behaved consistently with the FreeBSD implementations, and that our ACL library routines behaved correctly.
For the TrustedBSD Project to succeed, it must leverage the benefits of the open source model while avoiding the pitfalls: in general, this means adapting the development cycle and processes to that of the FreeBSD Project, which has shown remarkable success in navigating the challenges of distributed collaboration and development. Understanding the social aspects of open source software development is also important, including accepting the open source success model, leveraging distributed development and testing, and using open source as a tool for improved portability.
TrustedBSD testing tools fit into two general categories: tests intended to evaluate the correctness of specific aspects of the implementation, and tests intended to evaluate the overall correctness of larger scenarios. Smaller context-specific tests attempt to exhaustively explore the behavior of a specific piece of access control or related security functionality by constructing the relevant characteristic arguments and context, then comparing the results of the function with declared expectations.
An example of this includes the proc_to_proc regression test, which was developed to explore the correctness of authorization policy for inter-process system calls. Inter-process calls typically involve two processes: the first (subject) process invokes a system call which will affect another (object) process. Depending on the credentials associated with processes, and the security model in use, the kernel should reject some calls, and accept others. For example, the ptrace() system call allows a process to attach debugging services to another process, permitting it to read and write the memory contents and state of the process, as well as control its execution flow. Such a service allow the subject process to gain access to any resources available to object process, and as such, constitutes a substantial security risk if not properly protected. The following sample output from proc_to_proc illustrates a test failure when a process successfully signals another process instead of receiving the EPERM error.
[21. unpriv1 on daemon1].signal: expected
EPERM, got 0
(e:1000 r:1000 s:1000 P_SUGID:0)
(e:1000 r:0 s:0 P_SUGID:1)
Larger scenario tests attempt to explore whether more general expectations for correct behavior are met by the system. These tests typically perform compound operations, checking only that, given the correct starting state and sequence of operations, the desired end property is present. For example, the setuid_protected test evaluates whether or not a process that has executed a setuid binary undergoes the expected credential transformation, and, if so, is then protected from manipulation by other processes present in the system.
In both types of test, a clear notion of ``correct'' and an understanding of potential failure modes is required to design useful and complete tests. This is not a challenge unique to informal regression testing of security functionality on open source operating systems, but is complicated by a lack of clarity as to what the intended model should be.
The regression test design and implementation task offers substantial benefits to both TrustedBSD developers, and to the broader FreeBSD community. The test suites have already been used to simplify a number of access control checks, as well as point out inconsistencies in access control implementation. By using these tests in the development process, it is possible to gain greater assurance that the new features being added are implemented correctly, and that they do not weaken existing protections.
The EA interface provides simple semantics: for each file or directory, zero or more names may be defined. EA names exist in disjoint namespaces, of which two are defined: EXTATTR_NAMESPACE_SYSTEM and EXTATTR_NAMESPACE_USER. Namespaces determines the protection properties of an EA-access to the system namespace is limited to the kernel and privileged processes, while EAs in the user namespace are protected using the discretionary and mandatory protections on the file or directory. Each defined name may have zero or more bytes of data associated with it. No EAs are defined for a newly created file or directory, although consumers of EAs may define names and values during the creation process. Two operations are defined, allowing EAs to be atomically retrieved and set.
For a first implementation, we selected a simple design that permitted us to move on to additional new features that rely on EAs, allowing later performance optimization by those with greater expertise in file systems. Rather than modify the on-disk file system format, we chose to store EA data in backing files. This allowed us to avoid a lengthy and bug-prone development process, avoid conflicts with other on-going development on FFS, and avoid requiring low-level file system modifications to allow developers and users to experiment with EAs or features that rely on them. Each backing file stores one named EA from a single namespace for all files in the file system, and is treated as an array of EA instances indexed by inode number. Both the file itself and each instance of an EA have headers. The file header contains a backing file format version, as well as a field defining maximum size any EA instance can take on, permitting the array record size to be calculated as the sum of the EA instance header size and maximum EA instance size. EA instance headers indicate whether or not the instance is defined for the given inode, the size of the EA instance if defined, as well as a copy of the inode generation number, used for synchronization purposes. A privileged user process can invoke the extattrctl() system call to start EA support on a given UFS-based file system, and then enable individual EAs by associating backing files with EA names and namespaces.
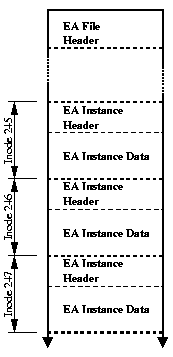
It is also possible to have EAs automatically started and enabled for the file system at mount-time by specifying the UFS_EXTATTR_AUTOSTART kernel option. When enabled, the mount code will search the .attribute/system and .attribute/user directories off of the file system root for valid backing files. When a file is found, an EA with the same name is enabled in the appropriate namespace. This permits atomic starting of EA services with the mount operation, preventing race conditions that might be present as a result of a delay in EAs becoming available while other files in the file system are accessible.
This implementation offers acceptable performance, requiring an additional seek for most operations if the EA has not already been loaded from disk. Currently, the UFS EA implementation relies on the file system buffer cache to cache the backing file, rather than implementing a custom EA cache; the temporal locality properties of most services currently layered on EAs allow this caching to be effective in mitigating most performance costs.
This implementation is sufficient to implement services such as ACLs, Capabilities, and MAC above the EA interface. However, it suffers from a number of limitations, including the treatment of EA meta-data as ``data'' from the perspective of the file system synchronization policy, in particular, with regards to the soft updates mechanism used in FFS. One important synchronization failure mode occurs if an EA is not always enabled when the file system is active. In this scenario, two problems arise: first, EAs are not garbage collected at file deletion, and second, services relying on EAs cannot update meta-data. The inode generation number replication into EA instance headers permits some synchronization problems to be detected, by preventing old EA data from being used with a new file, as the inode generation number is changed when the inode is re-allocated. In large part, the service meta-data update problem is solved by allowing the atomic auto-starting of EAs at mount-time. Currently, work is in the planning stages for a block-level implementation in FFS, which would have stronger performance and consistency properties while retaining the same interface, requiring no change to services above it.
The ACL evaluation algorithm selects an appropriate part of the credential and an entry in the ACL that are combined during permission evaluation; this order of preference matches first the owner, then additional user entries, then group entries, and finally, the ``other'' entry. The POSIX.1e ACL mask plays an important role in providing compatibility for ACL-unaware programs: it places a bound on the maximum rights provided by any additional users or group entries. If an extended ACL is available for an inode, the chmod() operation on the file is modified: rather than setting the file group bits, the ACL mask is modified. As a result, modification of the group bits in the permission effectively masks the rights for all entries of the ACL other than the file owner and other entries, allowing programs not aware of ACL interfaces to place an upper bound on file accessibility. Additional compatibility is provided by a default ACL placed on directories, which is combined with the permission set provided by the process on open() or create() to produce the new access ACL for a file created in that directory, allowing ACL-unaware applications to create a new file with an appropriate ACL.
The FreeBSD implementation splits the ACL data over the existing inode mode field in UFS, and two EAs, posix1e.acl_access for the access ACL on an inode, and posix1e.acl_default for the default ACL. At the VFS layer, two new vnode operations are introduced: VOP_GETACL to retrieve available ACLs from a vnode, and VOP_SETACL to set ACLs on the vnode. The caller may specify the ACL type determining whether the ACL operation is intended for the access or default ACL. When ACL support is compiled into the kernel, ACL code is enabled in a number of other UFS vnode operations, including VOP_ACCESS which invokes a generic vaccess_acl_posix1e() access check routine, as well as during file and directory creation via VOP_CREATE(), VOP_MKNOD(), VOP_MKDIR(), and VOP_SYMLINK(), where the default ACL, if any, is combined with the requested file mode to produce the access ACL for the child. As the ACL is split over both the inode mode and EA storage, the fields must be synchronized during certain operations-in particular, the ACL vnode operations, but also during file creation to combine the default ACL and request mode.
As a result of splitting the access ACL in this manner, many frequently performed operations, such as stat() and chmod() incur no additional overhead. The access ACL must be read for open() and access() calls on a file, and during actual ACL read or update operations. Access ACLs impose a slightly higher cost on directory operations than on file operations, although they also exhibit higher locality: directory lookup and listing requires that the access ACL be evaluated for the ACL_EXECUTE and ACL_READ permissions, respectively. Creation of a new file or sub-directory within a directory also exhibits higher cost because both the access and default ACLs must be retrieved for the parent, and then new access and default ACLs may be written out for the child.
In practice, ACL operations have high temporal locality lending them to caching, and suffer from higher latency rather than actual disk I/O utilization increase. When ACLs are not enabled on the file system, there is no measurable performance difference from the pre-ACL implementation, in keeping with the ``minimal impact on current configurations'' mandate. When ACLs are enabled but not used, an overhead is perceived due to reads associated with determining if an access ACL is defined, and for the lookup of default ACLs during file or sub-directory creation. When ACLs are enabled and utilized, higher costs are perceived during file and sub-directory creation if a default ACL is set on the directory in which new children are created. To improve the actual cost of ACLs when in use, the primary target for optimization is the EA implementation: the measured costs of ACL operations is effectively identical to the measured cost of the EA operation supporting the ACL operation.
The POSIX.1e ACL specification offers a largely complete and unambiguous specification for an ACL implementation; some extensions, however, are required to add more complete functionality in FreeBSD, such as the ability to perform ACL operations on directories via a file handle. Although the ACL mask behavior increases complexity, it provides relatively transparent support for ACL-unaware applications. While the ACL specification is not identical to the variations used in many commercial UNIX variants, it offers compatible semantics. The ACL implementation will be included in FreeBSD 5.0-RELEASE, and a number of applications, including Samba, already work properly with ACLs on FreeBSD 5.0-CURRENT development branch.
An initial experimental implementation has provided the desired functionality of enforcing three fixed MAC policies: MLS, a fixed-label Biba policy, and a generalization of the native FreeBSD Jail compartmentalization policy. In the long term, we hope to provide a more general framework for introducing mandatory access control mechanism. The policies are enforced over a fairly wide set of system objects, including processes as the target for inter-process operations, system management objects such as sysctl nodes, file system objects such as files and directories, and network objects such as sockets, interfaces, and mbufs. MAC labels are described by a struct mac which is appropriate for use on both subjects and objects, and currently contains three fields relevant to the three policies.
To support the labeling of subjects (processes), the ucred structure is extended to include an additional struct mac. cred0, the process credential for the first kernel process, is initialized to high integrity, low secrecy, and is not present in any jail compartment. All other processes inherit this credential, unless an intermediate process has modified it; privileged processes are permitted to update the MAC fields in accordance with the MAC policies. The user login mechanisms have been updated to retrieve per-user label information from the login.conf user class data. This requires that components of the system making use of the setusercontext() call now also set the SET_MACLABEL flag. Eventually, additional sources of information, such as incoming terminal and network label, may be used to make a policy-driven label determination.
For inter-process authorization, the existing p_can*() primitives were modified to call the mac_ucan*() versions of the call which could return a new failure mode.
To handle the labeling of transient kernel objects, a new label structure was created, struct objlabel, which contains the necessary ownership and protection information, including owner and ACL, as well as a struct mac for mandatory protection. struct objlabel behaves in a similar manner to struct ucred, in that a set of initial object labels are initialized by appropriate kernel subsystems, and then inherited (copy-on-write) by various children objects. For example, packets inherit the object label of the interface they originate from. for objects created by subjects, the new object label is based on a composition of the subject credential, and possible object parents. A series of new access control check primitives were introduced that check authorization between subject credentials and object labels, and were liberally scattered through system operations.
Some objects, such as sockets, play the interesting role of both subject and object: FreeBSD caches the subject's credential with the socket on creation, which allows the properties of the socket to remain static when transfered or inherited; this also allows UID-based decisions to be made on delivery of packets to sockets in the ipfw firewall code. This permits MAC delivery decisions to be made at the network layer without directly inspecting the receiving process or dealing with the ambiguity of multiple processes having access to a single socket. However, sockets are also objects when written to or read from by processes that have access to them, and therefore have an object label. Both types of events (acting on the socket as a subject and as an object) require mediation.
Currently, file system objects do not make use of the object label abstraction, instead mapping MAC labels into EAs on the file system, reading them when an access control check must be made. A new access control primitive, vaccess_mac() accepts subject credentials, vnode properties, and MAC labels loaded from EAs, and returns an access control decision which is then composed with the results of the discretionary access control check, vaccess_acl_posix1e() to generate a final access control result. In the future, we will look at allowing file systems to maintain objlabel structures directly, improving their ability to utilize more general abstractions.
Many MAC implementations make use of poly-instantiation to resolve namespace use conflicts by processes with conflicting labels. For example, UNIX processes may expect to be able to write files to /tmp at will-however, information flow policies may not permit a process with one integrity level to be aware of files written to the directory by a process with a lower integrity level. If the two processes select the same file name, under traditional UNIX semantics, one process will receive an error: this is not permitted under information flow MAC policies. Poly-instantiation allows different processes to appear to address the same namespace while being partitioned from one another: in the case of the file system, this might mean that the namei() name lookup routine points the processes at different underlying directories. TrustedBSD does not currently implement automatic poly-instantiation for directories, or for other namespaces such as the IP port and System V IPC namespaces, and in that sense, is incomplete. For the purposes of processes making use of the /tmp directory, appropriate setting of the TMPDIR environment variable has proven sufficient for the present-however, in the future, this issue will need to be addressed.
Since this is still a highly experimental environment, performance figures are not yet available, but appear to be similar to those of ACLs: when not involving file system accesses, the performance cost for most objects is negligible; when an EA operation is required, the performance corresponds to the required EA operations. The impact on the network subsystem is of particular interest, as new label operations are now interposed on existing packet and interface operations, and may impose a performance hit. Future MAC work on FreeBSD will include improved abstractions for managing labels, more pervasive use of these abstractions, such as in the file systems, and implementation of features such as poly-instantiation, processes making use of ranges of labels to mediate access between normally isolated process classes, and work to measure and optimize performance.
A number of trusted systems have been developed in the form of both research operating systems, and extensions to existing commercial systems. Trusted Mach[19] and other experimental trusted operating systems have explored the impact of secure design when building from the ground up. Many UNIX vendors offer trusted versions of their systems built in-house, such as SGI's Trusted IRIX[18]. There are also operating system security extension products that introduce trusted operating system features, such as PitBull from Argus Systems[1]. Open source trusted system work includes the LOMAC extensions for Linux[6], SELinux[13], POSIX.1e ACLs[8] and Capabilities[15] for Linux, and the Linux RSBAC project[17].
The TrustedBSD project benefits from both past and current research, building on the exploration of access control requirements and models, as well as research into improved abstractions and interfaces.
A major focus of the TrustedBSD work has been to emphasize portability of the feature sets, particularly with other open source operating systems. Both Andreas Gruenbacher, author of the Linux ACL and EA implementations, and Andrew Morgan, author of the Linux Privileges implementation, have been vital to this approach through their discussion of the POSIX.1e specification, and implementation feedback and critique. Thanks also to the Trust Technology group at SGI, including Casey Schaufler, Richard Offer, and Linda Walsh, all of whom have provided feedback on the POSIX.1e specification, and system/application requirements.
Substantial contributions of funding, development resources, and travel and communication reimbursement have been provided by NAI Labs, BSDi, Safeport Network Services, without whom the TrustedBSD Project would not have been possible.
As features reach maturity, they are integrated back into the base FreeBSD distribution: https://www.FreeBSD.org/
|
This paper was originally published in the
Proceedings of the FREENIX Track: 2001 USENIX Annual Technical Conference,
June 25-30, 2001, Boston, Masssachusetts, USA
Last changed: 21 June 2001 bleu |
|
