
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Security '04 Paper
[Security '04 Technical Program]
Finding User/Kernel Pointer Bugs With Type InferenceRob Johnson David Wagner
Abstract:
Today's operating systems struggle with vulnerabilities from careless
handling of user space pointers. User/kernel pointer bugs have
serious consequences for security: a malicious user could exploit a
user/kernel pointer bug to gain elevated privileges, read sensitive
data, or crash the system. We show how to detect user/kernel pointer
bugs using type-qualifier inference, and we apply this method to the
Linux kernel using CQUAL, a type-qualifier inference tool. We
extend the basic type-inference capabilities of CQUAL to support
context-sensitivity and greater precision when analyzing structures so
that CQUAL requires fewer annotations and generates fewer false
positives. With these enhancements, we were able to use CQUAL to
find 17 exploitable user/kernel pointer bugs in the Linux kernel.
Several of the bugs we found were missed by careful hand audits, other
program analysis tools, or both.
1 IntroductionSecurity critical programs must handle data from untrusted sources, and mishandling of this data can lead to security vulnerabilities. Safe data-management is particularly crucial in operating systems, where a single bug can expose the entire system to attack. Pointers passed as arguments to system calls are a common type of untrusted data in OS kernels and have been the cause of many security vulnerabilities. Such user pointers occur in many system calls, including, for example, read, write, ioctl, and statfs. These user pointers must be handled very carefully: since the user program and operating system kernel reside in conceptually different address spaces, the kernel must not directly dereference pointers passed from user space, otherwise security holes can result. By exploiting a user/kernel bug, a malicious user could take control of the operating system by overwriting kernel data structures, read sensitive data out of kernel memory, or simply crash the machine by corrupting kernel data. User/kernel pointer bugs are unfortunately all too common. In an attempt to avoid these bugs, the Linux programmers have created several easy-to-use functions for accessing user pointers. As long as programmers use these functions correctly, the kernel is safe. Unfortunately, almost every device driver must use these functions, creating thousands of opportunities for error, and as a result, user/kernel pointer bugs are endemic. This class of bugs is not unique to Linux. Every version of Unix and Windows must deal with user pointers inside the OS kernel, so a method for automatically checking an OS kernel for correct user pointer handling would be a big step in developing a provably secure and dependable operating system.
We introduce type-based analyses to detect and eliminate user/kernel pointer bugs. In particular, we augment the C type system with type qualifiers to track the provenance of all pointers, and then we use type inference to automatically find unsafe uses of user pointers. Type qualifier inference provides a principled and semantically sound way of reasoning about user/kernel pointer bugs. We implemented our analyses by extending CQUAL[7], a program verification tool that performs type qualifier inference. With our tool, we discovered several previously unknown user/kernel pointer bugs in the Linux kernel. In our experiments, we discovered 11 user/kernel pointer bugs in Linux kernel 2.4.20 and 10 such bugs in Linux 2.4.23. Four bugs were common to 2.4.20 and 2.4.23, for a total of 17 different bugs, and eight of these 17 were still present in the 2.5 development series. We have confirmed all but two of the bugs with kernel developers. All the bugs were exploitable. We needed to make several significant improvements to CQUAL in order to reduce the number of false positives it reports. First, we added a context-sensitive analysis to CQUAL, which has reduced the number of false positives and the number of annotations required from the programmer. Second, we improved CQUAL's handling of C structures by allowing fields of different instances of a structure to have different types. Finally, we improved CQUAL's analysis of casts between pointers and integers. Without these improvements, CQUAL reported far too many false positives. These two improvements reduce the number of warnings 20-fold and make the task of using CQUAL on the Linux kernel manageable. Our principled approach to finding user/kernel pointer bugs contrasts with the ad-hoc methods used in MECA[15], a prior tool that has also been used to find user/kernel pointer bugs. MECA aims for a very low false positive rate, possibly at the cost of missing bugs; in contrast, CQUAL aims to catch all bugs, at the cost of more false positives. CQUAL's semantic analysis provides a solid foundation that may, with further research, enable the possibility of formal verification of the absence of user/kernel pointer bugs in real OS's. All program analysis tools have false positives, but we show that programmers can substantially reduce the number of false positives in their programs by making a few small stylistic changes to their coding style. By following a few simple rules, programmers can write code that is efficient and easy to read, but can be automatically checked for security violations. These rules reduce the likelihood of getting spurious warnings from program verification or bug-finding tools like CQUAL. These rules are not specific to CQUAL and almost always have the benefit of making programs simpler and easier for the programmer to understand. In summary, our main contributions are
We begin by describing user/kernel pointer bugs in Section 2. We then describe type qualifier inference, and our refinements to this technique, in Section 3. Our experimental setup and results are presented in Sections 4 and 5, respectively. Section 6 discusses our false positive analysis and programming guidelines. We consider other approaches in Section 7. Finally, we summarize our results and give several directions for future work in Section 8.
|
 |
In certain cases, Linux allows kernel pointers to be treated
as if they were user pointers. This is analogous to the standard
C rule that a nonconst
2variable can be passed to a function
expecting a const argument, and is an example of qualifier subtyping.
The notion of subtyping should be intuitively familiar from the world
of object-oriented programming. In Java, for instance, if ![]() is a
subclass of
is a
subclass of ![]() , then an object of class
, then an object of class ![]() can be used wherever an
object of class
can be used wherever an
object of class ![]() is expected, hence
is expected, hence ![]() can be thought of as a subtype
of
can be thought of as a subtype
of ![]() (written
(written ![]() ).
).
CQUAL supports subtyping relations on user-defined qualifiers, so we can
declare that kernel is a subtype of user, written as
![]() . CQUAL then extends qualifier subtyping
relationships to qualified-type subtyping rules as follows.
First, we declare that
. CQUAL then extends qualifier subtyping
relationships to qualified-type subtyping rules as follows.
First, we declare that
![]() ,
because any
,
because any
![]() under kernel control can be treated as a
under kernel control can be treated as a
![]() possibly under user control.
The general rule is3
possibly under user control.
The general rule is3
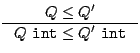
The rule for subtyping of pointers is slightly more complicated.
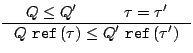
So far, we have described the basis for a type-checking
analysis. If we were willing to manually insert a
![]() or
or
![]() qualifier at every level of every type declaration
in the Linux kernel, we would be able to detect user/pointer bugs
by running standard type-checking algorithms.
However, the annotation burden of marking up the entire Linux kernel
in this way would be immense, and so we need some way to reduce
the workload on the programmer.
qualifier at every level of every type declaration
in the Linux kernel, we would be able to detect user/pointer bugs
by running standard type-checking algorithms.
However, the annotation burden of marking up the entire Linux kernel
in this way would be immense, and so we need some way to reduce
the workload on the programmer.
We reduce the annotation burden using type inference. The key observation is that the vast majority of type qualifier annotations would be redundant, and could be inferred from a few base annotations, like those in Figure 2. Type qualifier inference provides a way to infer these redundant annotations: it checks whether there is any way to extend the source code annotations to make the result type-check. CQUAL implements type qualifier inference. For example, this allows CQUAL to infer from the code
int bad_ioctl(void * user badp)that badq must be a user pointer (from the assignment badq = badp), but it is used as a kernel pointer (since badq is passed to copy_from_user). This is a type error. In this case, the type error indicates a bona fide security hole.
{
char badbuf[8];
void *badq = badp;
copy_to_user(badbuf, badq, 8);
}
Notice that, in this example, the programmer didn't have to write an annotation for the type of badq--instead, it was inferred from other annotations. Inference can dramatically reduce the number of annotations required from the programmer. In our experiments with Linux, we needed less than 300 annotations for the whole kernel; everything else was inferred by CQUAL's type inference algorithm.
As mentioned before, the theoretical underpinnings of type inference are sound, but C contains several constructs that can be used in unsound ways. Here we explain how CQUAL deals with these constructs.
We made several enhancements to CQUAL to support our user/kernel analysis. The challenge was to improve the analysis' precision and reduce the number of false positives without sacrificing scalability or soundness. One of the contributions of this work is that we have developed a number of refinements to CQUAL that meet this challenge. These refinements may be generally useful in other applications as well, so our techniques may be of independent interest. However, because the technical details require some programming language background to explain precisely, we leave the details to to the extended version of this paper and we only summarize our improvements here.
Together, these refinements dramatically reduce CQUAL's false positive rate. Before we made these improvements, CQUAL reported type errors (almost all of which were false positives) in almost every kernel source file. Now CQUAL finds type errors in only about 5% of the kernel source files, a 20-fold reduction in the number of false positives.
In addition to developing new refinements to type qualifier inference, we also created a heuristic that dramatically increases the ``signal-to-noise'' ratio of type inference error reports. We implemented this heuristic in CQUAL, but it may be applicable to other program analysis tools as well.
 |
Before explaining our heuristic, we first need to explain how CQUAL
detects type errors.
When CQUAL analyzes a source program, it creates a qualifier constraint
graph representing all the type constraints it discovers. A typing error
occurs whenever there is a valid path
4from
qualifier ![]() to qualifier
to qualifier ![]() where the user-specified type system
requires that
where the user-specified type system
requires that
![]() . In the user/kernel example, CQUAL looks for
valid paths from user to kernel.
Since each edge in an error path is derived
from a specific line of code, given an error path, CQUAL can
walk the user through the sequence of source code statements that gave
rise to the error, as is shown in Figure 3.
This allows at least rudimentary error reporting, and it is what
was implemented in CQUAL prior to our work.
. In the user/kernel example, CQUAL looks for
valid paths from user to kernel.
Since each edge in an error path is derived
from a specific line of code, given an error path, CQUAL can
walk the user through the sequence of source code statements that gave
rise to the error, as is shown in Figure 3.
This allows at least rudimentary error reporting, and it is what
was implemented in CQUAL prior to our work.
Unfortunately, though, such a simple approach is totally inadequate for a system as large as the Linux kernel. Because typing errors tend to ``leak out'' over the rest of the program, one programming mistake can lead to thousands of error paths. Presenting all these paths to the user, as CQUAL used to do, is overwhelming: it is unlikely that any user will have the patience to sort through thousands of redundant warning messages. Our heuristic enables CQUAL to select a few canonical paths that capture the fundamental programming errors so the user can correct them.
Many program analyses reduce finding errors in the input program to finding invalid paths through a graph, so a scheme for selecting error paths for display to the user could benefit a variety of program analyses.
To understand the idea behind our heuristic, imagine an ideal error
reporting algorithm. This algorithm would pick out a small set, ![]() ,
of statements in the original source code that break the
type-correctness of the program. These statements may or may not be
bugs, so we refer to them simply as untypable statements.
The algorithm should select these
statements such that, if the programmer fixed these lines of code,
then the program would type-check. The ideal algorithm would then
look at each error path and decide which statement in
,
of statements in the original source code that break the
type-correctness of the program. These statements may or may not be
bugs, so we refer to them simply as untypable statements.
The algorithm should select these
statements such that, if the programmer fixed these lines of code,
then the program would type-check. The ideal algorithm would then
look at each error path and decide which statement in ![]() is
the ``cause'' of this error path. After bucketing the error paths by
their causal statement, the ideal algorithm would select one
representive error path from each bucket and display it to the user.
is
the ``cause'' of this error path. After bucketing the error paths by
their causal statement, the ideal algorithm would select one
representive error path from each bucket and display it to the user.
Implementing the ideal algorithm is impossible, so we approximate it as best we can. The goal of our approximation is to print out a small number of error traces from each of the ideal buckets. When the approximation succeeds, each of the untypable statements from the ideal algorithm will be represented, enabling the programmer to address all his mistakes.
Another way to understand our heuristic is that it tries to eliminate ``derivative'' and ``redundant'' errors, i.e., errors caused by one type mismatch leaking out into the rest of the program, as well as multiple error paths that only differ in some minor, inconsequential way.
The heuristic works as follows. First, CQUAL sorts all the error paths in order of increasing length. It is obviously easier for the programmer to understand shorter paths than longer ones, so those will be printed first. It is not enough to just print the shortest path, though, since the program may have two or more unrelated errors.
Instead, let ![]() be the set of all qualifier variables that
trigger type errors. To eliminate derivative errors we require that, for
each qualifier
be the set of all qualifier variables that
trigger type errors. To eliminate derivative errors we require that, for
each qualifier ![]() , CQUAL prints out at most one path passing
through
, CQUAL prints out at most one path passing
through ![]() . To see why this rule works, imagine a local variable
that is used as both a user and kernel pointer. This variable
causes a type error, and the error may spread to other variables through
assignments, return statements, etc. When using our heuristic,
these other, derivative errors
will not be printed because they necessarily will have longer error
paths. After printing the path of the original error, the qualifier variable
with the type error will be marked, suppressing any extraneous error
reports. Thus this heuristic has the additional benefit of selecting
the error path that is most likely to highlight the actual programming
bug that caused the error. The heuristic will also clearly eliminate
redundant errors since if two paths differ only in minor,
inconsequential ways, they will still share some qualifier variable with a type
error. In essence, our heuristic approximates the buckets of the ideal
algorithm by using qualifier variables as buckets instead.
. To see why this rule works, imagine a local variable
that is used as both a user and kernel pointer. This variable
causes a type error, and the error may spread to other variables through
assignments, return statements, etc. When using our heuristic,
these other, derivative errors
will not be printed because they necessarily will have longer error
paths. After printing the path of the original error, the qualifier variable
with the type error will be marked, suppressing any extraneous error
reports. Thus this heuristic has the additional benefit of selecting
the error path that is most likely to highlight the actual programming
bug that caused the error. The heuristic will also clearly eliminate
redundant errors since if two paths differ only in minor,
inconsequential ways, they will still share some qualifier variable with a type
error. In essence, our heuristic approximates the buckets of the ideal
algorithm by using qualifier variables as buckets instead.
Before we implemented this heuristic, CQUAL often reported over 1000 type errors per file, in the kernel source files we analyzed. Now, CQUAL usually emits one or two error paths, and occasionally as many as 20. Furthermore, in our experience with CQUAL, this error reporting strategy accomplishes the main goals of the idealized algorithm described above: it reports just enough type errors to cover all the untypable statements in the original program.
We performed experiments with three separate goals. First, we wanted to verify that CQUAL is effective at finding user/kernel pointer bugs. Second, we wanted to demonstrate that our advanced type qualifier inference algorithms scale to huge programs like the Linux kernel. Third, we wanted to construct a Linux kernel provably free of user/kernel pointer bugs.
To begin, we annotated all the user pointer accessor functions and the dereference operator, as shown in Figure 2. We also annotated the kernel memory management routines, kmalloc and kfree, to indicate they return and accept kernel pointers. These annotations were not strictly necessary, but they are a good sanity check on our results. Since CQUAL ignores inline assembly code, we annotated several common functions implemented in pure assembly, such as memset and strlen. Finally, we annotated all the Linux system calls as accepting user arguments. There are 221 system calls in Linux 2.4.20, so these formed the bulk of our annotations. All told, we created 287 annotations. Adding all the annotations took about half a day. The extended version of this paper lists all the functions we annotated.
The Linux kernel can be configured with a variety of features and drivers. We used two different configurations in our experiments. In the file-by-file experiments we configured the kernel to enable as many drivers and features as possible. We call this the ``full'' configuration. For the whole-kernel analyses, we used the default configuration as shipped with kernels on kernel.org.
CQUAL can be used to perform two types of analyses: file-by-file or whole-program. A file-by-file analysis looks at each source file in isolation. As mentioned earlier, this type of analysis is not sound, but it is very convenient. A whole-program analysis is sound, but takes more time and memory. Some of our experiments are file-by-file and some are whole-program, depending on the goal of the experiment.
To validate CQUAL as a bug-finding tool we performed file-by-file analyses of Linux kernels 2.4.20 and 2.4.23 and recorded the number of bugs CQUAL found. We also analyzed the warning reports to determine what programmers can do to avoid false positives. Finally, we made a subjective evaluation of our error reporting heuristics to determine how effective they are at eliminating redundant warnings.
|
We chose to analyze each kernel source file in isolation
because programmers depend on separate compilation, so this model best
approximates how programmers actually use static analysis tools in practice.
As described in Section 3, analyzing one file at
a time is not sound. To partially compensate for this,
we disabled the subtyping relation
![]() . In the
context of single-file analysis, disabling subtyping
enables CQUAL to detect
inconsistent use of pointers, which is likely to represent a programming error.
The following example illustrates a
common coding mistake in the Linux kernel:
. In the
context of single-file analysis, disabling subtyping
enables CQUAL to detect
inconsistent use of pointers, which is likely to represent a programming error.
The following example illustrates a
common coding mistake in the Linux kernel:
void dev_ioctl(int cmd, char *p)
{
char buf[10];
if (cmd == 0)
copy_from_user(buf, p, 10);
else
*p = 0;
}
The parameter, p, is not explicitly annotated as a user
pointer, but it almost certainly is intended to be used as a
user pointer, so dereferencing it in the
``else'' clause is probably a serious, exploitable bug. If we allow
subtyping, i.e. if we assume kernel pointers can be used where
user pointers are expected, then CQUAL will just conclude that
p must be a kernel pointer. Since CQUAL doesn't see
the entire kernel at once, it can't see that dev_ioctl is
called with user pointers, so it can't detect the error. With
subtyping disabled, CQUAL will enforce consistent usage of
p: either always as a user pointer or always as a
kernel pointer. The dev_ioctl function will therefor
fail to typecheck.
In addition, we separately performed a whole kernel analysis on Linux kernel 2.4.23. We enabled subtyping for this experiment since, for whole kernel analyses, subtyping precisely captures the semantics of user and kernel pointers.
We had two goals with these whole-kernel experiments. First, we wanted to verify that CQUAL's new type qualifier inference algorithms scale to large programs, so we measured the time and memory used while performing the analysis. We then used the output of CQUAL to measure how difficult it would be to develop a version of the Linux kernel provably free of user/kernel pointer bugs. As we shall see, this study uncovered new research directions in automated security analysis.
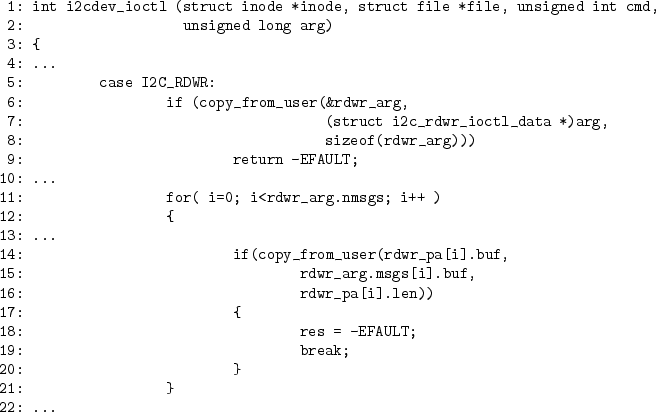 |
All our experimental results are summarized in Table 2.
 |
When we performed the same experiment on Linux 2.4.23, CQUAL generated 264 unique warnings in 155 files. Six warnings were real bugs, and 258 were false positives. We have confirmed 4 of the bugs with kernel developers. Figure 5 shows a simple user/kernel bug that an adversary could easily exploit to gain root privileges or crash the system.
We also did a detailed analysis of the false positives generated in this experiment and attempted to change the kernel source code to eliminate the causes of the spurious warnings; see Section 6.
Second, soundness matters. For example, Yang, et al. used their unsound bug-finding tool, MECA, to search for user/kernel bugs in Linux 2.5.63. We can't make a direct comparison between CQUAL and MECA since we didn't analyze 2.5.63. However, of the 10 bugs we found in Linux 2.4.23, 8 were still present in 2.5.63, so we can compare MECA and CQUAL on these 8 bugs. MECA missed 6 of these bugs, so while MECA is a valuable bug-finding tool, it cannot be trusted by security software developers to find all bugs.
Our attempt to create a verified version of Linux 2.4.23 suggests future research directions. The main obstacles to developing a verifiable kernel are false positives due to field unification and field updates, which are described in the extended version of this paper. A sound method for analyzing these programming idioms would open the door to verifiably secure operating systems.
Bugs and warnings are not distributed evenly throughout the kernel. Of the eleven bugs we found in Linux 2.4.23, all but two are in device drivers. Since there are about 1500KLOC in drivers and 700KLOC in the rest of the kernel, this represents a defect rate of about one bug per 200KLOC for driver code and about one bug per 400KLOC for the rest of the kernel. (Caveat: These numbers must be taken with a grain of salt, because the sample size is very small.) This suggests that the core kernel code is more carefully vetted than device driver code. On the other hand, the bugs we found are not just in ``obscure'' device drivers: we found four bugs in the core of the widely used PCMCIA driver subsystem. Warnings are also more common in drivers. In our file-by-file experiment with 2.4.23, 196 of the 264 unique warnings were in driver files.
Finally, we discovered a significant amount of bug turnover. Between Linux kernels 2.4.20 and 2.4.23, 7 user/kernel security bugs were fixed and 5 more introduced. This suggests that even stable, mature, slowly changing software systems may have large numbers of undiscovered security holes waiting to be exploited.
We analyzed the false positives from our experiment with Linux kernel 2.4.23. This investigation serves two purposes.
First, since it is impossible to build a program verification tool that is simultaneously sound and complete,5 any system for developing provably secure software must depend on both program analysis tools and programmer discipline. We propose two simple rules, based on our false positive analysis, that will help software developers write verifiably secure code.
Second, our false positive analysis can guide future reasearch in program verification tools. Our detailed classification shows tool developers the programming idioms that they will encounter in real code, and which ones are crucial for a precise and useful analysis.
|
Our methodology was as follows. To determine the cause of each warning, we attempted to modify the kernel source code to eliminate the warning while preserving the functionality of the code. We kept careful notes on the nature of our changes, and their effect on CQUAL's output. Table 3 shows the different false positive sources we identified, the frequency with which they occurred, and whether each type of false positives tended to indicate code that could be simplified or made more robust. The total number of false positives here is less than 264 because fixing one false positive can eliminate several others simultaneously. The extended version of this paper explains each type of false positive, and how to avoid it, in detail.
Based on our experiences analyzing these false positives, we have developed two simple rules that can help future programmers write verifiably secure code. These rules are not specific to CQUAL. Following these rules should reduce the false positive rate of any data-flow oriented program analysis tool.
As an example of Rule 1, if a temporary variable sometimes holds a user pointer and sometimes holds kernel pointer, then replace it with two temporary variables, one for each logical use of the original variable. This will make the code clearer to other programmers and, with a recent compiler, will not use any additional memory. 6 Reusing temporary variables may have improved performance in the past, but now it just makes code more confusing and harder to verify automatically.
As an example of the second rule, if a variable is conceptually a pointer, then declare it as a pointer, not a long or unsigned int. We actually saw code that declared a local variable as an unsigned long, but cast it to a pointer every time the variable was used. This is an extreme example, but subtler applications of these rules are presented in the extended version of this paper.
Following these rules is easy and has almost no impact on
performance, but can dramatically reduce the number of false positives
that program analysis tools like CQUAL generate. From
Table 3, kernel programmers could eliminate all but
37 of the false positives we saw (a factor of ![]() reduction)
by making a few simple changes to
their code.
reduction)
by making a few simple changes to
their code.
CQUAL has been used to check security properties in programs before. Shankar, et al., used CQUAL to find format string bugs in security critical programs[11], and Zhang, et al., used CQUAL to verify the placement of authorization hooks in the Linux kernel[16]. Broadwell, et al. used CQUAL in their Scrash system for eliminating sensitive private data from crash reports[2]. Elsman, et al. used CQUAL to check many other non-security applications, such as Y2K bugs[4] and Foster, et al. checked correct use of garbage collected ``__init'' data in the Linux kernel[6].
Linus Torvalds' program checker, Sparse, also uses type qualifiers to find user/kernel pointer bugs[12]. Sparse doesn't support polymorphism or type inference, though, so programmers have to write hundreds or even thousands of annotations. Since Sparse requires programmers to write so many annotations before yielding any payoff, it has seen little use in the Linux kernel. As of kernel 2.6.0-test6, only 181 files contain Sparse user/kernel pointer annotations. Sparse also requires extensive use of type qualifier casts that render its results completely unsound. Before Sparse, programmers had to be careful to ensure their code was correct. After Sparse, programmers have to be careful that their casts are also correct. This is an improvement, but as we saw in Section 5, bugs can easily slip through.
Yang, et al. developed MECA[15], a program checking tool carefully designed to have a low false positive rate. They showed how to use MECA to find dozens of user-kernel pointer bugs in the Linux kernel. The essential difference between MECA and CQUAL is their perspective on false positives: MECA aims for a very low false positive, even at the cost of missing bugs, while CQUAL aims to detect all bugs, even at the cost of increasing the false positive rate. Thus, the designers of MECA ignored any C features they felt cause too many false positives, and consequently MECA is unsound: it makes no attempt to deal with pointer aliasing, and completely ignores multiply-indirected pointers. MECA uses many advanced program analysis features, such as flow-sensitivity and a limited form of predicated types. MECA can also be used for other kinds of security analyses and is not restricted to user/kernel bugs. This results in a great bug-finding tool, but MECA can not be relied upon to find all bugs. In comparison, CQUAL uses principled, semantic-based analysis techniques that are sound and that may prove a first step towards formal verification of the entire kernel, though CQUAL's false alarm rate is noticeably higher.
CQUAL only considers the data-flow in the program being analyzed, completely ignoring the control-flow aspects of the program. There are many other tools that are good at analyzing control-flow, but because the user/kernel property is primarily about data-flow, control-flow oriented tools are not a good match for finding user/kernel bugs. For instance, model checkers like MOPS[3], SLAM[1], and BLAST[8] look primarily at the control-flow structure of the program being analyzed and thus are excellent tools for verifying that security critical operations are performed in the right order, but they are incapable of reasoning about data values in the program. Conversely, it would be impossible to check ordering properties with CQUAL. Thus tools like CQUAL and MOPS complement each other.
There are several other ad-hoc bug-finding tools that use simple lexical and/or local analysis techniques. Examples include RATS[9], ITS4[13], and LCLint[5]. These tools are unsound, since they don't deal with pointer aliasing or any other deep structure of the program. Also, they tend to produce many false positives, since they don't support polymorphism, flow-sensitivity, or other advanced program analysis features.
We have shown that type qualifier inference is an effective technique for finding user/kernel bugs, but it has the potential to do much more. Because type qualifier inference is sound, it may lead to techniques for formally verifying the security properties of security critical software. We have also described several refinements to the basic type inference methodology. These refinements dramatically reduce the number of false positives generated by our type inference engine, CQUAL, enabling it to analyze complex software systems like the Linux kernel. We have also described a heuristic that improves error reports from CQUAL. All of our enhancements can be applied to other data-flow oriented program analysis tools. We have shown that formal software analysis methods can scale to large software systems. Finally, we have analyzed the false positives generated by CQUAL and developed simple rules programmers can follow to write verifiable code. These rules also apply to other program analysis tools.
Our research suggests many directions for future research. First, our false positive analysis highlights several shortcomings in current program analysis techniques. Advances in structure-handling would have a dramatic effect on the usability of current program analysis tools, and could enable the development of verified security software. Several of the classes of false positives derive from the flow-insensitive analysis we use. Adding flow-sensitivity may further reduce the false-positive rate, although no theory of simultaneously flow-, field- and context-sensitive type qualifiers currently exists. Alternatively, researchers could investigate alternative programming idioms that enable programmers to write clear code that is easy to verify correct. Currently, annotating the source code requires domain-specific knowledge, so some annotations may accidentally be omitted. Methods for checking or automatically deriving annotations could improve analysis results.
Our results on Linux 2.4.20 and 2.4.23 suggest that widely deployed, mature systems may have even more latent security holes than previously believed. With sound tools like CQUAL, researchers have a tool to measure the number of bugs in software. Statistics on bug counts in different software projects could identify development habits that produce exceptionally buggy or exceptionally secure software, and could help users evaluate the risks of deploying software.
The extended version of this paper is available from
https://www.cs.berkeley.edu/~rtjohnso/.
CQUAL is open source software hosted on SourceForge, and is
available from
https://www.cs.umd.edu/~jfoster/cqual/.
We thank Jeff Foster for creating CQUAL and helping us use and improve it. We thank John Kodumal for implementing an early version of polymorphism in CQUAL and for helping us with the theory behind many of the improvements we made to CQUAL. We thank the anonyous reviewers for many helpful suggestions.
This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -dir html -split 0 -show_section_numbers -white -local_icons cquk.tex
The translation was initiated by Rob Johnson on 2004-05-19
|
This paper was originally published in the
Proceedings of the 13th USENIX Security Symposium,
August 9–13, 2004 San Diego, CA Last changed: 23 Nov. 2004 aw |
|