
Allemany and Felten [1] reduce useless concurrency with OS support to provide the same functionality that we support in hardware using cache-based advisory locking. The method is a variation on the technique of Bershad discussed in Section 6.1. They propose incrementing a counter of active threads on entrance to a critical section, and decrementing on exit. The OS decrements the counter while an active thread is switched out. Processes must wait until the count of active threads is below some threshold (1, in our case) before being allowed to proceed. Delayed processes do not excessively delay other processes because the count is decremented by the OS.
These techniques appear valuable for systems without hardware support for advisory locking and in fact their approach works better than ours under high contention. However, hardware advisory locking and conditional load are more resilient to processor failure and have lower overhead in the low-contention case. As with hardware versus software DCAS, the hardware implementation is simple and fast; further measurements are required to determine if it is compellingly so.
In other work, Israeli and Rappaport [15] implement n-way
atomic Compare and Swap and n-way LL/SC for P
processors out of single CAS. However, this approach is primarily of
theoretical interest because it requires a large amount of space (at
least P bits for every word in the shared memory), requires
words to be P bits wide, takes  to execute, and only
interlocks against other multi-word atomic instructions.
Anderson and Moir [2] improve upon this, requiring only
realistic sized words,
to execute, and only
interlocks against other multi-word atomic instructions.
Anderson and Moir [2] improve upon this, requiring only
realistic sized words, 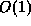 time, but still requiring a prohibitively
large amount of space.
time, but still requiring a prohibitively
large amount of space.
Finally, Software Transactional Memory [19]
is an attempt to implement
Transactional Memory in software, depending only on LL/ SC .
Unfortunately, their implementation will not work correctly on
existing implementations of LL/ SC
because their code ( AcquireOwnerships) depends on the ability
to interleave two outstanding LL/SC's simultaneously,
which is not supported.
The LLP/ SCP instructions we proposed would enable
their techniques to be used to provide software transactional memory for
multiple, independently chosen, words of memory.
However, the space and computational overhead in their implementation
is excessive for general use![]() .
Moreover, the STM operations are only atomic with respect to
other STM operations, and not to general reads and writes.
.
Moreover, the STM operations are only atomic with respect to
other STM operations, and not to general reads and writes.