



Next: Exploiting the sleep mode
Up: Results
Previous: Results
Understanding cache behavior
Figure 7 shows the compression energy of several
successive optimizations of the compress program. The
baseline implementation is itself an optimization of the original
compress code. The number preceding the dash refers to the
maximum length of codewords. The graph illustrates the need to be
aware of the cache behavior of an application in order to minimize
energy. The data structure of compress consists of two
arrays: a hash table to store symbols and prefixes, and a code table
to associate codes with hash table indexes. The tables are initially
stored back-to-back in memory. When a new symbol is read from the
input, a single index is used to retrieve corresponding entries from
each array. The ``16-merge'' version combines the two tables to form
an array of structs. Thus, the entry from the code table is brought
into the cache when the hash entry is read. The reduction in energy
is negligible: though one type of miss has been eliminated, the
program is actually dominated by a second type of miss: the probing of
the hash table for free entries. The Skiff data cache is small (16KB)
compared to the size of the hash table (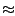 270KB), thus the
random indexing into the hash table results in a large number of
misses. A more useful energy and performance optimization is to make
the hash table more sparse. This admits fewer collisions which
results in fewer probes and thus a smaller number of cache misses. As
long as the extra memory is available to enable this optimization,
about 0.53Joules are saved compared with applying no
compression at all. This is shown by the ``16-sparse'' bar in the
figure. The baseline and ``16-merge'' implementations require more
energy than sending uncompressed data. A 12-bit version of compress
is shown as well. Even when peripheral overhead energy is
disregarded, it outperforms or ties the 16-bit schemes as its reduced
memory energy due to fewer misses makes up for poorer compression.
270KB), thus the
random indexing into the hash table results in a large number of
misses. A more useful energy and performance optimization is to make
the hash table more sparse. This admits fewer collisions which
results in fewer probes and thus a smaller number of cache misses. As
long as the extra memory is available to enable this optimization,
about 0.53Joules are saved compared with applying no
compression at all. This is shown by the ``16-sparse'' bar in the
figure. The baseline and ``16-merge'' implementations require more
energy than sending uncompressed data. A 12-bit version of compress
is shown as well. Even when peripheral overhead energy is
disregarded, it outperforms or ties the 16-bit schemes as its reduced
memory energy due to fewer misses makes up for poorer compression.
Another way to reduce cache misses is to fit both tables completely in
the cache. Compare the following two structures:
struct entry{ struct entry{
int fcode; signed fcode:20;
unsigned short code; unsigned code:12;
}table[SIZE]; }table[SIZE];
Each entry stores the same information, but the array on the
left wastes four bytes per entry. Two bytes are used only to align
the short code, and overly-wide types result in twelve wasted
bits in fcode and four bits wasted in code. Using
bitfields, the layout on the right contains the same information yet
fits in half the space. If the entry were not four bytes, it would
need to contain more members for alignment. Code with such structures
would become more complex as C does not support arrays of bitfields,
but unless the additional code introduces significant instruction
cache misses, the change is low-impact. A bitwise AND and a shift are
all that is needed to determine the offset into the compact structure.
By allowing the whole table to fit in the cache, the program with the
compacted array has just 56,985 data cache misses compared with 734,195
in the un-packed structure; a 0.0026% miss rate versus 0.0288%. The
energy benefit for compress with the compact layout is
negligible because there is so little CPU and memory energy to eliminate
by this technique. The ``11-merge'' and ``11-compact'' bars
illustrate the similarity. Nevertheless, 11-compact runs 1.5 times
faster due to the reduction in cache misses, and such a strategy could
be applied to any program which needs to reduce cache misses for
performance and/or energy. Eleven bit codes are necessary even with
the compact layout in order to reduce the size of the data structure.
Despite a dictionary with half the size, the number of bytes to
transmit increases by just 18% compared to ``12-merge.'' Energy,
however, is lower with the smaller dictionary due to less energy spent
in memory and increased speeds which reduce peripheral overhead.
Figure 7:
Optimizing compress (Text data)
|
|
Next: Exploiting the sleep mode
Up: Results
Previous: Results
Kenneth Barr
2003-03-04
![\includegraphics[width=3in]{figures/energy-send-lzw.eps}](img25.png)