| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
FAST 2002 Paper
[FAST Tech Program Index]
GPFS:
A Shared-Disk File System for Large Computing Clusters Frank Schmuck and Roger Haskin Abstract GPFS is IBM’s parallel, shared-disk file system for cluster computers, available on the RS/6000 SP parallel supercomputer and on Linux clusters. GPFS is used on many of the largest supercomputers in the world. GPFS was built on many of the ideas that were developed in the academic community over the last several years, particularly distributed locking and recovery technology. To date it has been a matter of conjecture how well these ideas scale. We have had the opportunity to test those limits in the context of a product that runs on the largest systems in existence. While in many cases existing ideas scaled well, new approaches were necessary in many key areas. This paper describes GPFS, and discusses how distributed locking and recovery techniques were extended to scale to large clusters.
1 IntroductionSince the beginning of computing, there have always been problems too big for the largest machines of the day. This situation persists even with today’s powerful CPUs and shared-memory multiprocessors. Advances in communication technology have allowed numbers of machines to be aggregated into computing clusters of effectively unbounded processing power and storage capacity that can be used to solve much larger problems than could a single machine. Because clusters are composed of independent and effectively redundant computers, they have a potential for fault-tolerance. This makes them suitable for other classes of problems in which reliability is paramount. As a result, there has been great interest in clustering technology in the past several years. One fundamental drawback of clusters is that programs must be partitioned to run on multiple machines, and it is difficult for these partitioned programs to cooperate or share resources. Perhaps the most important such resource is the file system. In the absence of a cluster file system, individual components of a partitioned program must share cluster storage in an ad-hoc manner. This typically complicates programming, limits performance, and compromises reliability. GPFS is a parallel file system for cluster computers that
provides, as closely as possible, the behavior of a general-purpose POSIX file
system running on a single machine. GPFS evolved from the Tiger Shark multimedia
file system Traditional supercomputing applications, when run on a cluster, require parallel access from multiple nodes within a file shared across the cluster. Other applications, including scalable file and Web servers and large digital libraries, are characterized by interfile parallel access. In the latter class of applications, data in individual files is not necessarily accessed in parallel, but since the files reside in common directories and allocate space on the same disks, file system data structures (metadata) are still accessed in parallel. GPFS supports fully parallel access both to file data and metadata. In truly large systems, even administrative actions such as adding or removing disks from a file system or rebalancing files across disks, involve a great amount of work. GPFS performs its administrative functions in parallel as well.
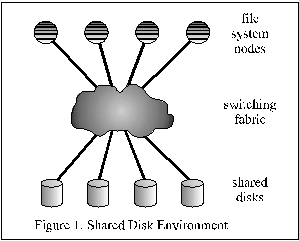
GPFS achieves its extreme scalability through its shared-disk
architecture (Figure 1) The switching fabric that connects file system nodes to disks may consist of a storage area network (SAN), e.g. fibre channel or iSCSI. Alternatively, individual disks may be attached to some number of I/O server nodes that allow access from file system nodes through a software layer running over a general-purpose communication network, such as IBM’s Virtual Shared Disk (VSD) running over the SP switch. Regardless of how shared disks are implemented, GPFS only assumes a conventional block I/O interface with no particular intelligence at the disks. Parallel read-write disk accesses from multiple nodes in the cluster must be properly synchronized, or both user data and file system metadata will become corrupted. GPFS uses distributed locking to synchronize access to shared disks. GPFS distributed locking protocols ensure file system consistency is maintained regardless of the number of nodes simultaneously reading from and writing to the file system, while at the same time allowing the parallelism necessary to achieve maximum throughput. This paper describes the overall architecture of GPFS, details some of the features that contribute to its performance and scalability, describes its approach to achieving parallelism and data consistency in a cluster environment, describes its design for fault-tolerance, and presents data on its performance. 2 General Large File System IssuesThe GPFS disk data structures support file systems with up
to 4096 disks of up to 1TB in size each, for a total of 4 petabytes per file
system. The largest single GPFS file system in production use to date is 75TB
(ASCI White 2.1 Data Striping and Allocation, Prefetch and Write-behindAchieving high throughput to a single, large file requires striping the data across multiple disks and multiple disk controllers. Rather than relying on a separate logical volume manager (LVM) layer, GPFS implements striping in the file system. Managing its own striping affords GPFS the control it needs to achieve fault tolerance and to balance load across adapters, storage controllers, and disks. Although some LVMs provide similar function, they may not have adequate knowledge of topology to properly balance load. Furthermore, many LVMs expose logical volumes as logical unit numbers (LUNs), which impose size limits due to addressability limitations, e.g., 32-bit logical block addresses. Large files in GPFS are divided into equal sized blocks,
and consecutive blocks are placed on different disks in a round-robin fashion.
To minimize seek overhead, the block size is large (typically 256k, but can be
configured between 16k and 1M). Large blocks give the same advantage as extents
in file systems such as Veritas To exploit disk parallelism when reading a large file from
a single-threaded application GPFS prefetches data into its buffer pool,
issuing I/O requests in parallel to as many disks as necessary to achieve the
bandwidth of which the switching fabric is capable. Similarly, dirty data
buffers that are no longer being accessed are written to disk in parallel. This
approach allows reading or writing data from/to a single file at the aggregate
data rate supported by the underlying disk subsystem and interconnection
fabric. GPFS recognizes sequential, reverse sequential, as well as various
forms of strided access patterns. For applications that do not fit one of these
patterns, GPFS provides an interface that allows passing prefetch hints to the
file system Striping works best when disks have equal size and performance. A non-uniform disk configuration requires a trade-off between throughput and space utilization: maximizing space utilization means placing more data on larger disks, but this reduces total throughput, because larger disks will then receive a proportionally larger fraction of I/O requests, leaving the smaller disks under-utilized. GPFS allows the administrator to make this trade-off by specifying whether to balance data placement for throughput or space utilization. 2.2 Large Directory SupportTo support efficient file name lookup in very large
directories (millions of files), GPFS uses extens�ible hashing As a directory grows, extensible hashing adds new
directory blocks one at a time. When a create operation finds no more room in
the directory block designated by the hash value of the new name, it splits the
block in two. The logical block number of the new directory block is derived
from the old block number by adding a '1' in the n+1st bit
position, and directory entries with a '1' in the n+1st bit
of their hash value are moved to the new block. Other directory blocks remain
unchanged. A large directory is therefore, in general, represented as a sparse
file, with holes in the file representing directory blocks that have not yet
been split. By checking for sparse regions in the directory file, GPFS can
determine how often a directory block has been split, and thus how many bits of
the hash value to use to locate the directory block containing a given name.
Hence a lookup always requires only a single directory block access, regardless
of the size and structure of the directory file 2.3 Logging and RecoveryIn a large file system it is not feasible to run a file
system check (fsck) to verify/restore file system consistency each time the
file system is mounted or every time that one of the nodes in a cluster goes
down. Instead, GPFS records all metadata updates that affect file system
consistency in a journal or write-ahead log Each node has a separate log for each file system it mounts, stored in that file system. Because this log can be read by all other nodes, any node can perform recovery on behalf of a failed node – it is not necessary to wait for the failed node to come back to life. After a failure, file system consistency is restored quickly by simply re-applying all updates recorded in the failed node’s log. For example, creating a new file requires updating a directory block as well as the inode of the new file. After acquiring locks on the directory block and the inode, both are updated in the buffer cache, and log records are spooled that describe both updates. Before the modi�fied inode or directory block are allowed to be written back to disk, the corresponding log records must be forced to disk. Thus, for example, if the node fails after writing the directory block but before the inode is written to disk, the node’s log is guaranteed to con�tain the log record that is necessary to redo the missing inode update. Once the updates described by a log record have been
written back to disk, the log record is no longer needed and can be discarded.
Thus, logs can be fixed size, because space in the log can be freed up at any
time by flushing dirty metadata back to disk in the background. 3 Managing Parallelism and Consistency in a Cluster3.1 Distributed Locking vs. Centralized ManagementA cluster file system allows scaling I/O throughput beyond what a single node can achieve. To exploit this capability requires reading and writing in parallel from all nodes in the cluster. On the other hand, preserving file system consistency and POSIX semantics requires synchronizing access to data and metadata from multiple nodes, which potentially limits parallelism. GPFS guarantees single-node equivalent POSIX semantics for file system operations across the cluster. For example if two processes on different nodes access the same file, a read on one node will see either all or none of the data written by a concurrent write operation on the other node (read/write atomicity). The only exceptions are access time updates, which are not immediately visible on all nodes.[1] There are two approaches to achieving the necessary synchronization: 1. Distributed Locking: every file system operation acquires an appropriate read or write lock to synchronize with conflicting operations on other nodes before reading or updating any file system data or metadata. 2. Centralized Management: all conflicting operations are forwarded to a designated node, which performs the requested read or update. The GPFS architecture is fundamentally based on distributed locking. Distributed locking allows greater parallelism than centralized management as long as different nodes operate on different pieces of data/metadata. On the other hand, data or metadata that is frequently accessed and updated from different nodes may be better managed by a more centralized approach: when lock conflicts are frequent, the overhead for distributed locking may exceed the cost of forwarding requests to a central node. Lock granularity also impacts performance: a smaller granularity means more overhead due to more frequent lock requests, whereas a larger granularity may cause more frequent lock conflicts.
In the following sections we first describe the GPFS distributed lock manager and then discuss how each of the techniques listed above improve scalability by optimizing – or in some cases avoiding – the use of distributed locking. 3.2 The GPFS Distributed Lock ManagerThe GPFS distributed lock manager, like many others Lock tokens also play a role in maintaining cache consistency between nodes. A token allows a node to cache data it has read from disk, because the data cannot be modified elsewhere without revoking the token first. 3.3 Parallel Data AccessCertain classes of supercomputer applications require writing to the same file from multiple nodes. GPFS uses byte-range locking to synchronize reads and writes to file data. This approach allows parallel applications to write concurrently to different parts of the same file, while maintaining POSIX read/write atomicity semantics. However, were byte-range locks implemented in a naive manner, acquiring a token for a byte range for the duration of the read/write call and releasing it afterwards, locking overhead would be unacceptable. Therefore, GPFS uses a more sophisticated byte-range locking protocol that radically reduces lock traffic for many common access patterns. Byte-range tokens are negotiated as follows. The first node to write to a file will acquire a byte-range token for the whole file (zero to infinity). As long as no other nodes access the same file, all read and write operations are processed locally without further interactions between nodes. When a second node begins writing to the same file it will need to revoke at least part of the byte-range token held by the first node. When the first node receives the revoke request, it checks whether the file is still in use. If the file has since been closed, the first node will give up the whole token, and the second node will then be able to acquire a token covering the whole file. Thus, in the absence of concurrent write sharing, byte-range locking in GPFS behaves just like whole-file locking and is just as efficient, because a single token exchange is sufficient to access the whole file. On the other hand, if the second node starts writing to a file before the first node closes the file, the first node will relinquish only part of its byte-range token. If the first node is writing sequentially at offset o1 and the second node at offset o2, the first node will relinquish its token from o2 to infinity (if o2 > o1) or from zero to o1 (if o2 < o1). This will allow both nodes to continue writing forward from their current write offsets without further token conflicts. In general, when multiple nodes are writing sequentially to non-overlapping sections of the same file, each node will be able to acquire the necessary token with a single token exchange as part of its first write operation. Information about write offsets is communicated during this token negotiation by specifying a required range, which corresponds to the offset and length of the write() system call currently being processed, and a desired range, which includes likely future accesses. For sequential access, the desired range will be from the current write offset to infinity. The token protocol will revoke byte ranges only from nodes that conflict with the required range; the token server will then grant as large a sub-range of the desired range as is possible without conflicting with ranges still held by other nodes.
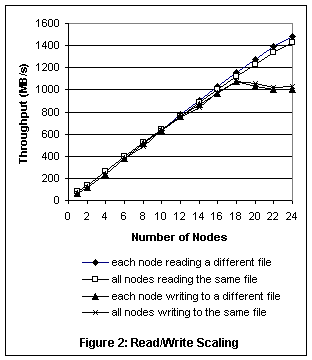
The measurements shown in Figure 2 demonstrate how I/O throughput in GPFS scales when adding more file system nodes and more disks to the system. The measurements were obtained on a 32-node IBM RS/6000 SP system with 480 disks configured as 96 4+P RAID-5 devices attached to the SP switch through two I/O server nodes. The figure compares reading and writing a single large file from multiple nodes in parallel against each node reading or writing a different file. In the single-file test, the file was partitioned into n large, contiguous sections, one per node, and each node was reading or writing sequentially to one of the sections. The writes were updates in place to an existing file. The graph starts with a single file system node using four RAIDs on the left, adding four more RAIDs for each node added to the test, ending with 24 file system nodes using all 96 RAIDs on the right. It shows nearly linear scaling in all tested configurations for reads. In the test system, the data throughput was not limited by the disks, but by the RAID controller. The read throughput achieved by GPFS matched the throughput of raw disk reads through the I/O subsystem. The write throughput showed similar scalability. At 18 nodes the write throughput leveled off due to a problem in the switch adapter microcode.[2] The other point to note in this figure is that writing to a single file from multiple nodes in GPFS was just as fast as each node writing to a different file, demonstrating the effectiveness of the byte-range token protocol described above. As long as the access pattern allows predicting the region of the file being accessed by a particular node in the near future, the token negotiation protocol will be able to minimize conflicts by carving up byte-range tokens among nodes accordingly. This applies not only to simple sequential access, but also to reverse sequential and forward or backward strided access patterns, provided each node operates in different, relatively large regions of the file (coarse-grain sharing). As sharing becomes finer grain (each node writing to multiple, smaller regions), the token state and corresponding message traffic will grow. Note that byte-range tokens not only guarantee POSIX semantics but also synchronize I/O to the data blocks of the file. Since the smallest unit of I/O is one sector, the byte-range token granularity can be no smaller than one sector; otherwise, two nodes could write to the same sector at the same time, causing lost updates. In fact, GPFS uses byte-range tokens to synchronize data block allocation as well (see next section), and therefore rounds byte-range tokens to block boundaries. Hence multiple nodes writing into the same data block will cause token conflicts even if individual write operations do not overlap (“false sharing”). To optimize fine-grain sharing for applications that do
not require POSIX semantics, GPFS allows disabling normal byte-range locking by
switching to data shipping mode. File access switches to a method best
described as partitioned, centralized management. File blocks are assigned to
nodes in a round-robin fashion, so that each data block will be read or written
only by one particular node. GPFS forwards read and write operations
originating from other nodes to the node responsible for a particular data
block. For fine-grain sharing this is more efficient than distributed locking,
because it requires fewer messages than a token exchange, and it avoids the
overhead of flushing dirty data to disk when revoking a token. The eventual
flushing of data blocks to disk is still done in parallel, since the data
blocks of the file are partitioned among many nodes.
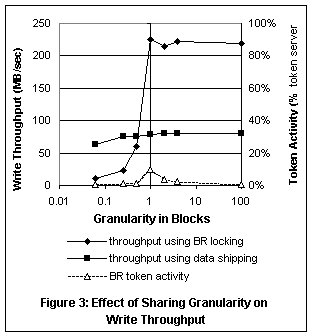
Figure 3 shows the effect of sharing granularity on write throughput, using data shipping and using normal byte-range locking. These measurements were done on a smaller SP system with eight file system nodes and two I/O servers, each with eight disks. Total throughput to each I/O server was limited by the switch.[3] We measured throughput with eight nodes updating fixed size records within the same file. The test used a strided access pattern, where the first node wrote records 0, 8, 16, …, the second node wrote records 1, 9, 17, …, and so on. The larger record sizes (right half of the figure) were multiples of the file system block size. Figure 3 shows that byte-range locking achieved nearly the full I/O throughput for these sizes, because they matched the granularity of the byte-range tokens. Updates with a record size smaller than one block (left half of the figure) required twice as much I/O, because of the required read-modify-write. The throughput for byte-range locking, however, dropped off far below the expected factor of one half due to token conflicts when multiple nodes wrote into the same data block. The resulting token revokes caused each data block to be read and written multiple times. The line labeled “BR token activity” plots token activity measured at the token server during the test of I/O throughput using byte-range locking. It shows that the drop in throughput was in fact due to the additional I/O activity and not an overload of the token server. The throughput curve for data shipping in Figure 3 shows that data shipping also incurred the read-modify-write penalty plus some additional overhead for sending data between nodes, but it dramatically outperformed byte-range locking for small record sizes that correspond to fine grain sharing. The data shipping implementation was intended to support fine-grain access, and as such does not try to avoid the read-modify-write for record sizes larger than a block. This fact explains why data shipping throughput stayed flat for larger record sizes. Data shipping is primarily used by the MPI/IO library.
MPI/IO does not require POSIX semantics, and provides a natural mechanism to
define the collective that assigns blocks to nodes. The programming interfaces
used by MPI/IO to control data shipping, however, are also available to other
applications that desire this type of file access 3.4 Synchronizing Access to File MetadataLike other file systems, GPFS uses inodes and indirect blocks to store file attributes and data block addresses. Multiple nodes writing to the same file will result in concurrent updates to the inode and indirect blocks of the file to change file size and modification time (mtime) and to store the addresses of newly allocated data blocks. Synchronizing updates to the metadata on disk via exclusive write locks on the inode would result in a lock conflict on every write operation. Instead, write operations in GPFS use a shared write lock on the inode that allows concurrent writers on multiple nodes. This shared write lock only conflicts with operations that require exact file size and/or mtime (a stat() system call or a read operation that attempts to read past end-of-file). One of the nodes accessing the file is designated as the metanode for the file; only the metanode reads or writes the inode from or to disk. Each writer updates a locally cached copy of the inode and forwards its inode updates to the metanode periodically or when the shared write token is revoked by a stat() or read() operation on another node. The metanode merges inode updates from multiple nodes by retaining the largest file size and latest mtime values it receives. Operations that update file size or mtime non-monotonically (trunc() or utimes()) require an exclusive inode lock. Updates to indirect blocks are synchronized in a similar fashion. When writing a new file, each node independently allocates disk space for the data blocks it writes. The synchronization provided by byte-range tokens ensures that only one node will allocate storage for any particular data block. This is the reason that GPFS rounds byte-range tokens to block boundaries. Periodically or on revocation of a byte-range token, the new data block addresses are sent to the metanode, which then updates the cached indirect blocks accordingly. Thus, GPFS uses distributed locking to guarantee POSIX semantics (e.g., a stat() system call sees the file size and mtime of the most recently completed write operation), but I/O to the inode and indirect blocks on disk is synchronized using a centralized approach (forwarding inode updates to the metanode). This allows multiple nodes to write to the same file without lock conflicts on metadata updates and without requiring messages to the metanode on every write operation. The metanode for a particular file is elected dynamically with the help of the token server. When a node first accesses a file, it tries to acquire the metanode token for the file. The token is granted to the first node to do so; other nodes instead learn the identity of the metanode. Thus, in traditional workloads without concurrent file sharing, each node becomes metanode for the files it uses and handles all metadata updates locally. When a file is no longer being accessed on the metanode and ages out of the cache on that node, the node relinquishes its metanode token and stops acting as metanode. When it subsequently receives a metadata request from another node, it sends a negative reply; the other node will then attempt to take over as metanode by acquiring the metanode token. Thus, the metanode for a file tends to stay within the set of nodes actively accessing that file. 3.5 Allocation MapsThe allocation map records the allocation status (free or in-use) of all disk blocks in the file system. Since each disk block can be divided into up to 32 subblocks to store data for small files, the allocation map contains 32 bits per disk block as well as linked lists for finding a free disk block or a subblock of a particular size efficiently. Allocating disk space requires updates to the allocation map, which must be synchronized between nodes. For proper striping, a write operation must allocate space for a particular data block on a particular disk, but given the large block size used by GPFS, it is not as important where on that disk the data block is written. This fact allows organizing the allocation map in a way that minimizes conflicts between nodes by interleaving free space information about different disks in the allocation map as follows. The map is divided into a large, fixed number n of separately lockable regions, and each region contains the allocation status of 1/nth of the disk blocks on every disk in the file system. This map layout allows GPFS to allocate disk space properly striped across all disks by accessing only a single allocation region at a time. This approach minimizes lock conflicts, because different nodes can allocate space from different regions. The total number of regions is determined at file system creation time based on the expected number of nodes in the cluster. For each GPFS file system, one of the nodes in the cluster is responsible for maintaining free space statistics about all allocation regions. This allocation manager node initializes free space statistics by reading the allocation map when the file system is mounted. The statistics are kept loosely up-to-date via periodic messages in which each node reports the net amount of disk space allocated or freed during the last period. Instead of all nodes individually searching for regions that still contain free space, nodes ask the allocation manager for a region to try whenever a node runs out of disk space in the region it is currently using. To the extent possible, the allocation manager prevents lock conflicts between nodes by directing different nodes to different regions. Deleting a file also updates the allocation map. A file created by a parallel program running on several hundred nodes might have allocated blocks in several hundred regions. Deleting the file requires locking and updating each of these regions, perhaps stealing them from the nodes currently allocating out of them, which could have a disastrous impact on performance. Therefore, instead of processing all allocation map updates at the node on which the file was deleted, those that update regions known to be in use by other nodes are sent to those nodes for execution. The allocation manager periodically distributes hints about which regions are in use by which nodes to facilitate shipping deallocation requests.
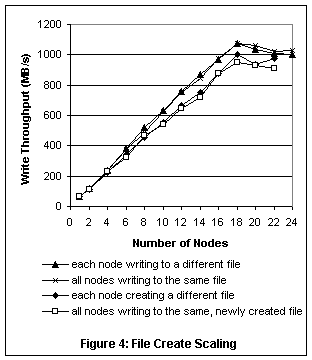
To demonstrate the effectiveness of the allocation manager hints as well as the metanode algorithms described in the previous section we measured write throughput for updates in place to an existing file against creation of a new file (Figure 4). As in Figure 2, we measured all nodes writing to a single file (using the same access pattern as in Figure 2), as well as each node writing to a different file. The measurements were done on the same hardware as Figure 2, and the data points for the write throughput are in fact the same points shown in the earlier figure. Due to the extra work required to allocate disk storage, throughput for file creation was slightly lower than for update in place. Figure 4 shows, however, that create throughput still scaled nearly linearly with the number of nodes, and that creating a single file from multiple nodes was just as fast as each node creating a different file. 3.6 Other File System MetadataA GPFS file system contains other global metadata, including file system configuration data, space usage quotas, access control lists, and extended attributes. Space does not permit a detailed description of how each of these types of metadata is managed, but a brief mention is in order. As in the cases described in previous sections, GPFS uses distributed locking to protect the consistency of the metadata on disk, but in most cases uses more centralized management to coordinate or collect metadata updates from different nodes. For example, a quota manager hands out relatively large increments of disk space to the individual nodes writing a file, so quota checking is done locally, with only occasional interaction with the quota manager. 3.7 Token Manager ScalingThe token manager keeps track of all lock tokens granted to all nodes in the cluster. Acquiring, relinquishing, upgrading, or downgrading a token requires a message to the token manager. One might reasonably expect that the token manager could become a bottleneck in a large cluster, or that the size of the token state might exceed the token manager’s memory capacity. One way to address these issues would be to partition the token space and distribute the token state among several nodes in the cluster. We found, however, that this is not the best way — or at least not the most important way — to address token manager scaling issues, for the following reasons. A straightforward way to distribute token state among nodes might be to hash on the file inode number. Unfortunately, this does not address the scaling issues arising from parallel access to a single file. In the worst case, concurrent updates to a file from multiple nodes generate a byte-range token for each data block of a file. Because the size of a file is effectively unbounded, the size of the byte-range token state for a single file is also unbounded. One could conceivably partition byte-range token management for a single file among multiple nodes, but this would make the frequent case of a single node acquiring a token for a whole file prohibitively expensive. Instead, the token manager prevents unbounded growth of its token state by monitoring its memory usage and, if necessary, revoking tokens to reduce the size of the token state[4]. The most likely reason for a high load on the token manager node is lock conflicts that cause token revocation. When a node downgrades or relinquishes a token, dirty data or metadata covered by that token must be flushed to disk and/or discarded from the cache. As explained earlier (see Figure 3), the cost of disk I/O caused by token conflicts dominates the cost of token manager messages. Therefore, a much more effective way to reduce token manager load and improve overall performance is to avoid lock conflicts in the first place. The allocation manager hints described in Section 3.5 are an example of avoiding lock conflicts. Finally, GPFS uses a number of optimizations in the token protocol that significantly reduce the cost of token management and improve response time as well. When it is necessary to revoke a token, it is the responsibility of the revoking node to send revoke messages to all nodes that are holding the token in a conflicting mode, to collect replies from these nodes, and to forward these as a single message to the token manager. Acquiring a token will never require more than two messages to the token manager, regardless of how many nodes may be holding the token in a conflicting mode. The protocol also supports token prefetch and token request batching, which allow acquiring multiple tokens in a single message to the token manager. For example, when a file is accessed for the first time, the necessary inode token, metanode token, and byte-range token to read or write the file are acquired with a single token manager request. When a file is deleted on a node, the node does not immediately relinquish the tokens associated with that file. The next file created by the node can then re-use the old inode and will not need to acquire any new tokens. A workload where users on different nodes create and delete files under their respective home directories will generate little or no token traffic.
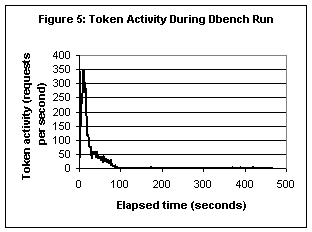
Figure 5 demonstrates the effectiveness of this optimization.
It shows token activity while running a multi-user file server workload on
multiple nodes. The workload was generated by the dbench program 4 Fault ToleranceAs a cluster is scaled up to large numbers of nodes and disks it becomes increasingly unlikely that all components are working correctly at all times. This implies the need to handle component failures gracefully and continue operating in the presence of failures. 4.1 Node FailuresWhen a node fails, GPFS must restore metadata being updated by the failed node to a consistent state, must release resources held by the failed node (lock tokens), and it must appoint replacements for any special roles played by the failed node (e.g., metanode, allocation manager, or token manager). Since GPFS stores recovery logs on shared disks, metadata inconsistencies due to a node failure are quickly repaired by running log recovery from the failed node’s log on one of the surviving nodes. After log recovery is complete, the token manager releases tokens held by the failed node. The distributed locking protocol ensures that the failed node must have held tokens for all metadata it had updated in its cache but had not yet written back to disk at the time of the failure. Since these tokens are only released after log recovery is complete, metadata modified by the failed node will not be accessible to other nodes until it is known to be in a consistent state. This observation is true even in cases where GPFS uses a more centralized approach to synchronizing metadata updates, for example, the file size and mtime updates that are collected by the metanode. Even though the write operations causing such updates are not synchronized via distributed locking, the updates to the metadata on disk are still protected by the distributed locking protocol — in this case, through the metanode token. After log recovery completes, other nodes can acquire any metanode tokens that had been held by the failed node and thus take over the role of metanode. If another node had sent metadata updates to the old metanode but, at the time of the failure, had not yet received an acknowledgement that the updates were committed to disk, it re-sends the updates to the new metanode. These updates are idempotent, so the new metanode can simply re-apply them. Should the token manager fail, another node will take over this responsibility and reconstruct the token manager state by querying all surviving nodes about the tokens they currently hold. Since the new token manager does not know what tokens were held by failed nodes, it will not grant any new tokens until log recovery is complete. Tokens currently held by the surviving nodes are not affected by this. Similarly, other special functions carried out by a failed node (e.g., allocation manager) are assigned to another node, which rebuilds the necessary state by reading information from disk and/or querying other nodes. 4.2 Communication FailuresTo detect node failures GPFS relies on a group services
layer that monitors nodes and communication links via periodic heartbeat
messages and implements a process group membership protocol A communication failure such as a bad network adapter or a loose cable may cause a node to become isolated from the others, or a failure in the switching fabric may cause a network partition. Such a partition is indistinguishable from a failure of the unreachable nodes. Nodes in different partitions may still have access to the shared disks and would corrupt the file system if they were allowed to continue operating independently of each other. For this reason, GPFS allows accessing a file system only by the group containing a majority of the nodes in the cluster; the nodes in the minority group will stop accessing any GPFS disk until they can re-join a majority group. Unfortunately, the membership protocol cannot guarantee how long it will take for each node to receive and process a failure notification. When a network partition occurs, it is not known when the nodes that are no longer members of the majority will be notified and stop accessing shared disks. Therefore, before starting log recovery in the majority group, GPFS fences nodes that are no longer members of the group from accessing the shared disks, i.e., it invokes primitives available in the disk subsystem to stop accepting I/O requests from the other nodes. To allow fault-tolerant two-node configurations, a communication partition in such a configuration is resolved exclusively through disk fencing instead of using a majority rule: upon notification of the failure of the other node, each node will attempt to fence all disks from the other node in a predetermined order. In case of a network partition, only one of the two nodes will be successful and can continue accessing GPFS file systems. 4.3 Disk FailuresSince GPFS stripes data and metadata across all disks that belong to a file system, the loss of a single disk will affect a disproportionately large fraction of the files. Therefore, typical GPFS configurations use dual-attached RAID controllers, which are able to mask the failure of a physical disk or the loss of an access path to a disk. Large GPFS file systems are striped across multiple RAID devices. In such configurations, it is important to match the file system block size and alignment with RAID stripes so that data block writes do not incur a write penalty for the parity update. As an alternative or a supplement to RAID, GPFS supports replication, which is implemented in the file system. When enabled, GPFS allocates space for two copies of each data or metadata block on two different disks and writes them to both locations. When a disk becomes unavailable, GPFS keeps track of which files had updates to a block with a replica on the unavailable disk. If and when the disk becomes available again, GPFS brings stale data on the disk up-to-date by copying the data from another replica. If a disk fails permanently, GPFS can instead allocate a new replica for all affected blocks on other disks. Replication can be enabled separately for data and metadata. In cases where part of a disk becomes unreadable (bad blocks), metadata replication in the file system ensures that only a few data blocks will be affected, rather than rendering a whole set of files inaccessible. 5 Scalable Online System UtilitiesScalability is important not only for normal file system operations, but also for file system utilities. These utilities manipulate significant fractions of the data and metadata in the file system, and therefore benefit from parallelism as much as parallel applications. For example, GPFS allows growing, shrinking, or
reorganizing a file system by adding, deleting, or replacing disks in an
existing file system. After adding new disks, GPFS allows rebalancing the file
system by moving some of the existing data to the new disks. To remove or
replace one or more disks in a file system, GPFS must move all data and metadata
off the affected disks. All of these operations require reading all inodes and
indirect blocks to find the data that must be moved. Other utilities that need
to read all inodes and indirect blocks include defragmentation, quota-check,
and fsck[5] Finishing such operations in any reasonable amount of time requires exploiting the parallelism available in the system. To this end, GPFS appoints one of the nodes as a file system manager for each file system, which is responsible for coordinating such administrative activity. The file system manager hands out a small range of inode numbers to each node in the cluster. Each node processes the files in its assigned range and then sends a message to the file system manager requesting more work. Thus, all nodes work on different subsets of files in parallel, until all files have been processed. During this process, additional messages may be exchanged between nodes to compile global file system state. While running fsck, for example, each node collects block references for a different section of the allocation map. This allows detecting inter-file inconsistencies, such as a single block being assigned to two different files. Even with maximum parallelism, these operations can take a significant amount of time on a large file system. For example, a complete rebalancing of a multi-terabyte file system may take several hours. Since it is unacceptable for a file system to be unavailable for such a long time, GPFS allows all of its file system utilities to run on-line, i.e., while the file system is mounted and accessible to applications. The only exception is a full file system check for diagnostic purposes (fsck), which requires the file system to be unmounted. File system utilities use normal distributed locking to synchronize with other file activity. Special synchronization is required only while reorganizing higher-level metadata (allocation maps and the inode file). For example, when it is necessary to move a block of inodes from one disk to another, the node doing so acquires a special range lock on the inode file, which is more efficient and less disruptive than acquiring individual locks on all inodes within the block. 6 ExperiencesGPFS is installed at several hundred customer sites, on clusters ranging from a few nodes with less than a terabyte of disk, up to the 512-node ASCI White system with its 140 terabytes of disk space in two file systems. Much has been learned that has affected the design of GPFS as it has evolved. These lessons would make a paper in themselves, but a few are of sufficient interest to warrant relating here. Several of our experiences pointed out the importance of intra-node as well as inter-node parallelism and for properly balancing load across nodes in a cluster. In the initial design of the system management commands, we assumed that distributing work by starting a thread on each node in the cluster would be sufficient to exploit all available disk bandwidth. When rebalancing a file system, for example, the strategy of handing out ranges of inodes to one thread per node, as described in Section 5, was able to generate enough I/O requests to keep all disks busy. We found, however, that we had greatly underestimated the amount of skew this strategy would encounter. Frequently, a node would be handed an inode range containing significantly more files or larger files than other ranges. Long after other nodes had finished their work, this node was still at work, running single-threaded, issuing one I/O at a time. The obvious lesson is that the granules of work handed out must be sufficiently small and of approximately equal size (ranges of blocks in a file rather than entire files). The other lesson, less obvious, is that even on a large cluster, intra-node parallelism is often a more efficient road to performance than inter-node parallelism. On modern systems, which are often high-degree SMPs with high I/O bandwidth, relatively few nodes can saturate the disk system[6]. Exploiting the available bandwidth by running multiple threads per node, for example, greatly reduces the effect of workload skew. Another important lesson is that even though the small amount of CPU consumed by GPFS centralized management functions (e.g., the token manager) normally does not affect application performance, it can have a significant impact on highly parallel applications. Such applications often run in phases with barrier synchronization points. As described in Section 5, centralized services are provided by the file system manager, which is dynamically chosen from the nodes in the cluster. If this node also runs part of the parallel application, the management overhead will cause it to take longer to reach its barrier, leaving the other nodes idle. If the overhead slows down the application by even one percent, the idle time incurred by other nodes will be equivalent to leaving five nodes unused on the 512-node ASCI White system! To avoid this problem, GPFS allows restricting management functions to a designated set of administrative nodes. A large cluster can dedicate one or two administrative nodes, avoid running load sensitive, parallel applications on them, and actually increase the available computing resource. Early versions of GPFS had serious performance problems with programs like “ls –l” and incremental backup, which call stat() for each file in a directory. The stat() call reads the file’s inode, which requires a read token. If another node holds this token, releasing it may require dirty data to be written back on that node, so obtaining the token can be expensive. We solved this problem by exploiting parallelism. When GPFS detects multiple accesses to inodes in the same directory, it uses multiple threads to prefetch inodes for other files in the same directory. Inode prefetch speeds up directory scans by almost a factor of ten. Another lesson we learned on large systems is that even the rarest failures, such as data loss in a RAID, will occur. One particularly large GPFS system experienced a microcode failure in a RAID controller caused by an intermittent problem during replacement of a disk. The failure rendered three sectors of an allocation map unusable. Unfortunately, an attempt to allocate out of one of these sectors generated an I/O error, which caused the file system to take itself off line. Running log recovery repeated the attempt to write the sector and the I/O error. Luckily no user data was lost, and the customer had enough free space in other file systems to allow the broken 14 TB file system to be mounted read-only and copied elsewhere. Nevertheless, many large file systems now use GPFS metadata replication in addition to RAID to provide an extra measure of security against dual failures. Even more insidious than rare, random failures are systematic ones. One customer was unfortunate enough to receive several hundred disk drives from a bad batch with an unexpectedly high failure rate. The customer wanted to replace the bad drives without taking the system down. One might think this could be done by successively replacing each drive and letting the RAID rebuild, but this would have greatly increased the possibility of a dual failure (i.e., a second drive failure in a rebuilding RAID parity group) and a consequent catastrophic loss of the file system. The customer chose as a solution to delete a small number of disks (here, RAID parity groups) from the file system, during which GPFS rebalances data from the deleted disks onto the remaining disks. Then new disks (parity groups) were created from the new drives and added back to the file system (again rebalancing). This tedious process was repeated until all disks were replaced, without taking the file system down and without compromising its reliability. Lessons include not assuming independent failures in a system design, and the importance of online system management and parallel rebalancing. 7 Related WorkOne class of file systems extends the traditional file
server architecture to a storage area network (SAN) environment by allowing the
file server clients to access data directly from disk through the SAN. Examples
of such SAN file systems are IBM/Tivoli SANergy SGI’s XFS file system Frangipani Another example of a shared-disk cluster file system is
the Global File System (GFS) 8 Summary and ConclusionsGPFS was built on many of the ideas that were developed in
the academic community over the last several years, particularly distributed
locking and recovery technology. To date it has been a matter of conjecture how
well these ideas scale. We have had the opportunity to test those limits in the
context of a product that runs on the largest systems in existence. One might question whether distributed locking scales, in
particular, whether lock contention for access to shared metadata might become
a bottleneck that limits parallelism and scalability. Somewhat to our surprise,
we found that distributed locking scales quite well. Nevertheless, several
significant changes to conventional file system data structures and locking
algorithms yielded big gains in performance, both for parallel access to a
single large file and for parallel access to large numbers of small files. We
describe a number of techniques that make distributed locking work in a large
cluster: byte-range token optimizations, dynamic selection of meta nodes for
managing file metadata, segmented allocation maps, and allocation hints. One might similarly question whether conventional
availability technology scales. Obviously there are more components to fail in
a large system. Compounding the problem, large clusters are so expensive that
their owners demand high availability. Add to this the fact that file systems
of tens of terabytes are simply too large to back up and restore. Again, we
found the basic technology to be sound. The surprises came in the measures that
were necessary to provide data integrity and availability. GPFS replication was
implemented because at the time RAID was more expensive than replicated
conventional disk. RAID has taken over as its price has come down, but even its
high level of integrity is not sufficient to guard against the loss of a hundred
terabyte file system. Existing GPFS installations show that our design is able to
scale up to the largest super computers in the world and to provide the
necessary fault tolerance and system management functions to manage such large
systems. Nevertheless, we expect the continued evolution of technology to
demand ever more scalability. The recent interest in Linux clusters with
inexpensive PC nodes drives the number of components up still further. The
price of storage has decreased to the point that customers are seriously
interested in petabyte file systems. This trend makes file system scalability
an area of interest for research that will continue for the foreseeable future. 9 AcknowledgementsA large number of people at several IBM locations have contributed to the design and implementation of GPFS over the years. Although space does not allow naming all of them here, the following people have significantly contributed to the work reported here: Jim Wyllie, Dan McNabb, Tom Engelsiepen, Marc Eshel, Carol Hartman, Mike Roberts, Wayne Sawdon, Dave Craft, Brian Dixon, Eugene Johnson, Scott Porter, Bob Curran, Radha Kandadai, Lyle Gayne, Mike Schouten, Dave Shapiro, Kuei-Yu Wang Knop, Irit Loy, Benny Mandler, John Marberg, Itai Nahshon, Sybille Schaller, Boaz Shmueli, Roman Talyanski, and Zvi Yehudai. [1] Since read-read sharing is very common, synchronizing atime across multiple nodes would be prohibitively expensive. Since there are few, if any, applications that require accurate atime, we chose to propagate atime updates only periodically. [2] The test machine had pre-release versions of the RS/6000 SP Switch2 adapters. In this early version of the adapter microcode, sending data from many nodes to a single I/O server node was not as efficient as sending from an I/O server node to many nodes. [3] Here, the older RS/6000 SP Switch, with nominal 150 MB/sec throughput. Software overhead reduces this to approximately 125 MB/sec. [4] Applications that do not require POSIX semantics can, of course, use data shipping to bypass byte-range locking and avoid token state issues. [5] For diagnostic purposes to verify file system consistency, not part of a normal mount. [6] Sixteen nodes drive the entire 12 GB/s I/O bandwidth of ASCI White.
|
|
This paper was originally published in the
Proceedings of the FAST '02 Conference on File and Storage Technologies, January 28-30, 2002, Doubletree Hotel, Monterey, California, USA.
Last changed: 27 Dec. 2001 ml |
|