Towards Fingerpointing in the Emulab Dynamic Distributed System 1
Michael P. Kasick, Priya Narasimhan |
Abstract: In the large-scale Emulab distributed system, the many failure reports make skilled operator time a scarce and costly resource, as shown by statistics on failure frequency and root cause. We describe the lessons learned with error reporting in Emulab, along with the design, initial implementation, and results of a new local error-analysis approach that is running in production. Through structured error reporting, association of context with each error-type, and propagation of both error-type and context, our new local analysis locates the most prominent failure at the procedure, script, or session level. Evaluation of this local analysis for a targeted set of common Emulab failures suggests that this approach is generally accurate and will facilitate global fingerpointing, which will aim for reliable suggestions as to the root-cause of the failure at the system level.
As Emulab grew in size and gained popularity, the number of automatic failure emails became a significant cost in skilled operator time. Table 1 shows the statistics for a sample month, broken down semi-manually, although imperfectly. Note how large numbers of certain errors are temporally clustered, a key clue for both human and automated analysis. These statistics show that 82 automated emails, but only 27 clusters, were generated per day on average.
Category Clusters Messages
DB Software 13 2% 1485 60% Hardware Error 19 2% 19 1% Audit 41 5% 42 2% Unix System Software 49 6% 60 2% Informational 77 9% 82 3% Emulab Software 189 23% 303 12% Resource Shortage 205 25% 220 9% User Error 221 27% 248 10%
Table 1: Breakdown of automated messages sent to testbed operators in a representative month, April 2006. A cluster is a group of messages in which each message is issued within 60 seconds of the previous.
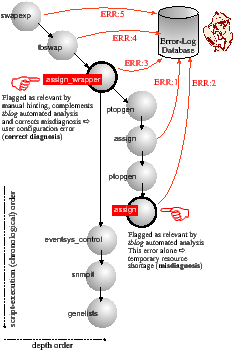
The context written to the error-log database allows for the post-processing and analysis of swap-* failures. During the post-failure cleanup phase, tblog tries to determine which of all of the errors generated in the current session are the most relevant to operators in diagnosing the failure's cause. tblog reconstructs the script call-chain for each reported error. Analogous to a call-stack backtrace, the script call-chain describes script-execution in both chronological and depth orders (see Figure 1 for a real example). tblog ascertains which script (assign in Figure 1), of those in the call-chain, recorded errors most recently at the greatest depth; this script and its associated errors are flagged as relevant. This approach works well in many cases because errors reported earlier chronologically (ERR:1) are often inconsequential to later errors (ERR:2) at a given depth. Errors reported at shallower depths (ERR:4–5) than the flagged scripts (ERR:3) are assumed to provide only summary or redundant information.
In addition, two-thirds of all unique-per-session errors consist of only three error types (see Table 2).
Occurrences Error Type
31 26.3% assign_violation/feasible 24 20.3% assign_type_precheck/feasible 22 18.6% node_boot_failed 10 8.5% ns_parse_failed 7 5.9% assign_fixed_node/feasible 6 5.1% node_load_failed 5 4.2% over_disk_quota 4 3.4% invalid_os 3 2.5% cancel_flag 2 1.7% assign_mapping_precheck/infeasible 2 1.7% assign_type_precheck/infeasible 1 0.8% invalid_variable 1 0.8% snmp_get_fatal
Table 2: Unique-per-session errors grouped by error type. A feasible error refers to experiment requests that could be realized given enough free resources, and an infeasible error refers to experiment requests that could never be realized with the current testbed resources.
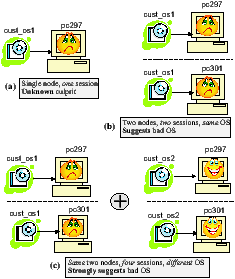
As an example, contrast a single node-boot failure within a single session to one across two or more sessions (see Figure 2). In the first case, if one node fails to boot one OS image, it is not discernible whether either or both are faulty. However, if two different nodes in two different sessions fail to boot the same OS image, we can suggest that the OS image, rather than the nodes, is likely to be faulty. In addition, if the nodes that failed to boot a specific OS image succeed in booting other OS images, then we can reliably infer that the specific OS image is faulty and that the nodes are not. Similar arguments can be used to fingerpoint a faulty node rather than the OS images.
This document was translated from LATEX by HEVEA.