Our performance tests were done using QEMU/KVM on a 2-way AMD Quad-core Barcelona system with 8GB of RAM and a 13 disk fibre channel storage array. Venti was configured with a 10GB arena and a 512MB isect and bloom filter. Venti was configured with 32MB of memory cache, a 32MB bloom cache, and a 64MB isect cache.
For each of our benchmarks, we compared an image in an Ext3 file system using the QEMU raw block driver back end, an image exposed through ufs, a user space 9P file server, using the QEMU block-9P block driver back end, and then an image stored in Venti exposed through vdiskfs using the QEMU block-9P block driver back end.
Each benchmark used a fresh Fedora 9 install for x86_64. For all benchmarks, we backed the block driver we were testing with a temporary QCOW2 image. The effect of this is that all writes were thrown away. This was necessary since vdiskfs does not currently support write operations.
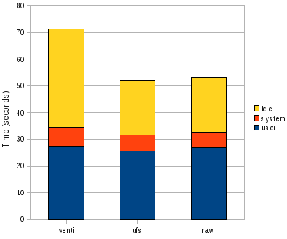
Our first benchmark was a simple operating system boot measured against wall clock time. The purposes of this benchmark was to determine if a casual user would be impacted by the use of a content addressable storage backed root disk. Our measurements showed that the when using the QEMU block-9P driver against a simple 9P block server, there was no statistically significant difference in boot time or CPU consumption compared to the QEMU raw block driver. When using the QEMU block-9P driver against vdiskfs, we observed a 25reduction in CPU consumption due to increased latency for I/O operations.
The second benchmark was a timed dd operation. The transfer size was 1MB and within the guest, direct I/O was used to eliminate any effects of the guest page cache. It demonstrates the performance of streaming read. All benchmarks were done with a warm cache so the data is being retrieved from the host page cache.
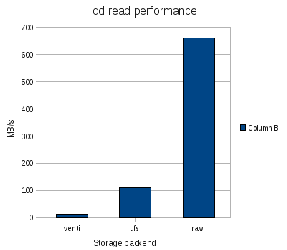
The ufs back end is able to obtain about 111MB/sec using block-9P. Since all accesses are being satisfied by the host page cache, the only limiting factor are additional copies within ufs and within the socket buffers.
The QEMU raw block driver is able to achieve over 650MB/sec when data is accessed through the host page cache. We believe it is possible to achieve performance similar to the QEMU raw block driver through ufs by utilizing splice in Linux.
vdiskfs is only able to obtain about 12MB/sec using block-9P. While this performance may seem disappointing, it is all we expected from the existing implementation of Venti and we talk about some approaches to improving it in Section 5.
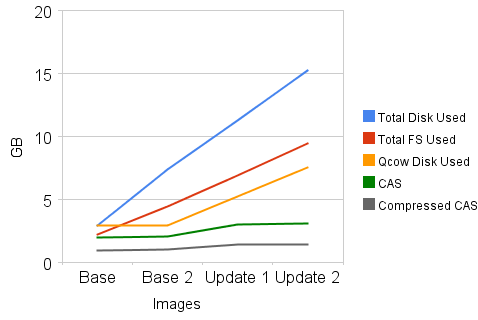
Finally, to validate whether or not content addressable storage schemes would improve storage efficiency in the face of software-updates we compared the disk overhead of two instances of a Linux installation before and after a software update. We compared raw disk utilization, file system reported space used, copy-on-write image disk utilization, content addressable storage, and compressed content addressable storage. To construct the copy-on-write images, we used the QEMU QCOW2 format and used the same base image for both Base and Base2. To evaluate the content addressable storage efficiency we used Venti to snapshot the raw disk images after installation and again after a manual software update was run. We used Venti's web interface to collect data about its storage utilization for compressed data as well as its projections for uncompressed data.
As can be seen in Figure 8 the various solutions all take approximately the same amount of storage for a single image. When adding a second instance of the same image, the raw storage use doubles while both the copy-on-write storage and content-addressable-storage essentially remain the same. The software update process on each image downloaded approximately 500MB of data. As the update applied, each QCOW2 image (as well as the raw disk images) increased in size proportionally.
We were surprised to find both the raw disk and copy-on-write overhead for the software update was over double what we expected. We surmise this is due to temporary files and other transient data written to the disk and therefore the copy-on-write layer. This same dirty-but-unused block data is also responsible for the divergence between the Total FS Used and the Total Disk Used lines in the reported storage utilization. This behavior paints a very bad efficiency picture for copy-on-write solutions in the long term. While copy-on-write provides some initial benefits, their storage utilization will steadily increase and start to converge with the amount of storage used by a raw-disk installation.
Utilizing the disk block scanning techniques we applied in Section 2, we found we could detect and de-duplicated these transient dirty blocks. Such an approach may work to improve overall performance once we work out the scalability and performance issues of the underlying CAS mechanism. Because Venti is partially aware of the underlying structure of the Ext2 file system it only snapshots active file blocks. As a result, its storage utilization grows slightly for the first software update, but the overhead of the second software update is completely eliminated.
Eric Van Hensbegren 2008-11-04