Tip and Palsberg [32] proposed a set of propagation-based
call graph construction algorithms for Java with different
granularities ranging from RTA to 0-CFA. XTA uses separate sets
for methods and fields. A type reaching a caller can reach a callee if
it is a subclass of the callee's parameter types. Types can be passed
between methods by field accesses as well. To approximate the targets
of a virtual call, XTA uses the reachable types of the caller to perform
method lookups statically. When new targets are discovered, new edges
are added into the graph. The analysis performs propagation until
reaching the fixed point. XTA has the same complexity as subset-based
points-to analysis, ![]() , but with fewer nodes in the graph.
, but with fewer nodes in the graph.
XTA analysis is a good candidate as a dynamic IPA: it requires reasonably small resources to represent the graph since it ignores the dataflow inside a method. The results might be less precise than an analysis using a full dataflow approach [23,31]. On the other hand, rich runtime type information may improve the precision of dynamic XTA. The results of the analysis can be used for method inlining and the elimination of type checks.
Like other static IPAs for Java, static XTA assumes the whole programs are available at analysis time. Dynamically-loaded classes must be supplied to the analysis manually. The burden on static XTA is to approximate targets of polymorphic calls while propagating types along the call graph. However, dynamic XTA does not have this difficulty because it uses the call graph constructed at runtime. The call graph used by dynamic XTA is significantly smaller than the one constructed by static XTA. However, a new challenge for dynamic XTA comes from lazy class loading. In a Java class file, a call instruction has only the name and descriptor of a callee as well as a symbolic reference to a class where the callee can be found. Similarly, field access instructions have symbolic references only. At runtime, a type reference is resolved to a class type and a method/field reference is resolved to a method/field before any use. 4
(a) Java source
(b) compiled bytecode
|
Figure 2 shows a simple example to help understand
the problem caused by symbolic references. Class B extends class
A, which declares a field ![]() . Field accesses of a.f and b.f
were compiled to putfield and getfield instructions with
different symbolic field references A.f and B.f.
At runtime, before the getfield
instruction gets executed, the reference B.f is resolved to
field f of class A. However, a dynamic analysis or
compiler cannot determine that B.f will be resolved
to f of A without loading both classes B and A.
. Field accesses of a.f and b.f
were compiled to putfield and getfield instructions with
different symbolic field references A.f and B.f.
At runtime, before the getfield
instruction gets executed, the reference B.f is resolved to
field f of class A. However, a dynamic analysis or
compiler cannot determine that B.f will be resolved
to f of A without loading both classes B and A.
Resolution of method/field references requires the classes to be loaded and resolved first. However, a JVM may choose to delay such resolution as late as possible to reduce resource usage and improve responsiveness [21]. To port a static IPA for Java to a dynamic IPA, the analysis must be modified to handle unresolved references. In this section, we demonstrate a solution for the problem for dynamic XTA; our solution is also applicable to general IPAs for Java.
Our dynamic XTA analysis constructs a directed XTA graph
![]() :
:
The XTA graph combines call graphs and field/array accesses. A call from a method A to a method B is modelled by an edge from node A to node B. The filter set includes parameter types of method B. If B's return type is a reference type, it is added in the filter set of the edge from B to A. Field reads and writes are modelled by edges between methods and fields, with the fields' declaring classes in the filter. Each node has a set of reachable (resolved) types.
Basic graph operations include adding new edges, new reachable types, and propagations:
Since the call graph is constructed at runtime using code stubs, there are no new edges created during propagation. The complexity of the propagation operation is linear.
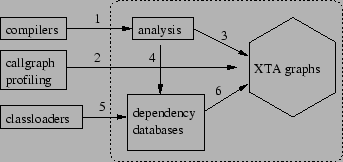
Dynamic XTA analysis is driven by events from JIT compilers and class loaders. Figure 3 shows the flow of events. In the dotted box are the three modules of dynamic XTA analysis: XTA graphs, the analysis, and dependency databases. The JIT compilers notify the analysis by channel 1 that a method is about to be compiled. The analysis scans the bytecode of the method body and, for each new instruction with a resolved type, the analysis adds the type into the reachable type set of the method via channel 3; otherwise it registers a dependency on the unresolved type reference for the method via channel 4. Similarly for field accesses, if the field reference can be resolved without triggering class loading, the analysis adds a directed edge into the graph via channel 3; otherwise, it registers a dependency on unresolved field reference for the method. Since we use call graph profiling code stubs to discover new call edges, the code stubs can add new edges to the graph by channel 2. Whenever a type reference or field reference gets resolved, the dependency databases are notified (by channel 5), and registered dependencies on resolved references are resolved to new reachable types or new edges of the graph. Whenever the graph is changed (either an edge is changed, or a new reachable type is added), a propagator propagates type sets of related nodes until no further change occurs.
Compared to static IPAs such as points-to analysis, the problem set of dynamic XTA analysis is much smaller because the graph contains only compiled methods and resolved fields at runtime. Although optimizations such as off-line variable substitution [24] and online cycle elimination [11] can help reduce the graph size further, the complexity and runtime overhead of the algorithms may prevent them from being useful in a dynamic analysis. Efficient representations for sets and graphs, such as hybrid integer sets [20,14] and BDDs[7], are more important since the dynamic analysis has bounded resources. In our implementation, graphs, sets, and dependency databases were implemented using hybrid integer sets and integer hash maps.
Graph changes are driven by runtime events such as newly compiled methods, newly discovered call edges, or dynamically loaded classes. Similar to the DOIT framework [23], clients using XTA analysis for optimizations should register properties to be verified when the graph changes. Since the analysis can notify the client when a change occurs, the clients can perform an invalidation of compiled code or recover execution states to a safe point. The exact design and implementation details for verifying properties and performing invalidations are beyond the scope of this paper. Readers can find more about dependency management and invalidation techniques in [16,12,18].
Feng Qian 2004-02-16