


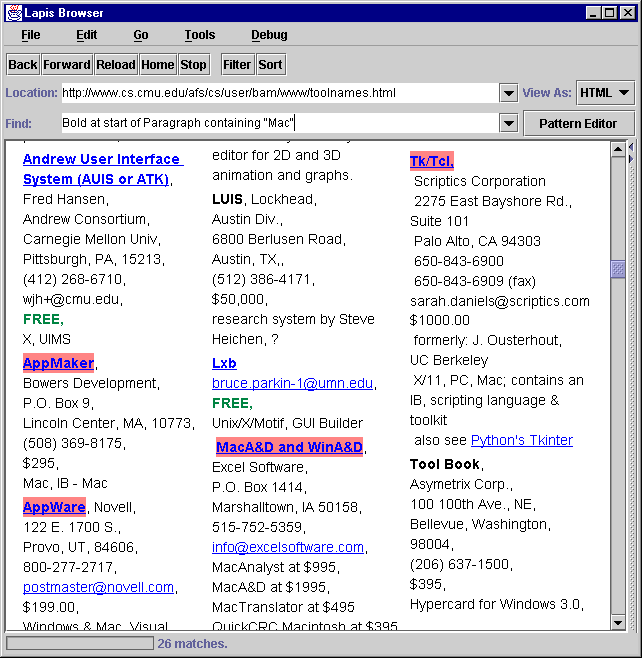
Our prototype lightweight structured text processing system is LAPIS, a web browser that has been extended with a pattern language (text constraints) and several generic text-processing tools. LAPIS is built on top of Sun's Java Foundation Classes. A screenshot of the browser is shown in Figure 1.
|
|
Figure 1: The LAPIS web browser, showing a web page that describes
user interface toolkits. The user has entered the pattern Bold
at start of Paragraph containing "Mac" to highlight the names of
toolkits that support Macintosh development.
|
Several parsers are included in the browser, which run automatically when a page of a certain MIME type is loaded. A parser interprets a particular text format and labels its components in the document. The built-in parsers include:
New parsers can be defined in two ways: writing a Java class that implements our Parser interface, or by developing a system of text constraints. The HTML and Character parsers were written by hand in Java. The Java parser was automatically generated from an example grammar included with the JavaCC parser-generator [26], showing that LAPIS can take advantage of existing parsers without recoding the grammar in text constraint expressions. USEnglish was developed interactively in LAPIS as a system of text constraints.
In the browser, the user can enter a text constraint expression and see the matching regions highlighted (see Figure 1). Highlighting is simple to implement and familiar to users, but unfortunately it merges adjacent and overlapping regions together, without distinguishing their endpoints. Future research should identify better ways to display overlapping region sets in context. To view highlighted regions, the user can either scroll the document or use the Next Match menu command to jump from one highlighted region to the next.
In addition to patterns, the user can also highlight regions by manual selection. In the prototype, a selection made with the mouse is distinct from the highlighted region set showing matches to a pattern. The selection is a single, contiguous region (colored blue), whereas the highlighted region set may be multiple, noncontiguous regions (colored red). The current selection in the document is always available as a one-element region set named Selection. By referring to Selection in a text constraint, for example, the user can limit the pattern's scope to a manually selected region of the document. The user can also construct a named region set by adding or removing regions. The Label menu command adds the current selection to the region set with the given name. A corresponding Unlabel command removes the selection from a given named region set by deleting regions that lie inside the selection and trimming the ends of regions that overlap the selection. By applying Label and Unlabel repeatedly to a sequence of selections, the user can build up a named region set by hand, or modify a named region set created by a parser or a pattern.
Several tools are provided for manipulating the highlighted regions. Filter eliminates all unhighlighted text from the display. By default, Filter inserts linebreaks between the highlighted regions to keep the display readable. Documents are filtered at the source text level - even HTML documents. The result is sometimes illegal HTML (with orphaned start tags or end tags), but the web browser can render it passably.
Like Filter, Sort filters the display down to highlighted regions, and also reorders the regions. Regions can be sorted alphabetically or numerically. By default, the sort key is the entire content of a region, but the user can provide an additional text constraint expression describing the sort field.