| ||||||||||||||||||||||||||||||||||||||||||||||||||||
2000 USENIX Annual Technical Conference
[Technical Index]
Pandora: A Flexible Network Monitoring PlatformSimon Patarin and Mesaac Makpangou
Abstract
This paper presents Pandora, a network monitoring platform that captures packets using purely passive techniques. Pandora addresses current needs for improving Internet middleware and infrastructure by providing both in-depth understanding of network usage and metrics to compare existing protocols. Pandora is flexible and easy to use and deploy. The elementary monitoring tasks are encapsulated as independent entities we call monitoring components. The actual packet analysis is performed by stacking the appropriate components. Pandora also preserves user privacy by allowing control of the "anonymization" policy. Finally, the evaluation we conducted shows that overheads due to Pandora's flexibility do not significantly affect performance. Pandora is fully functional and has already been used to collect Web traffic traces at INRIA Rocquencourt. 1 IntroductionNetwork monitoring is essential for the improvement of Internet performance. It serves to capture usage profiles, to evaluate the impact of Internet services (e.g. replication and cooperative caching), to compare the overheads of different implementations, and to help debug complex distributed applications. In recent years, several network monitoring tools have been proposed. These include naturally tcpdump [11], and specialized software like BLT [2] and HttpFilt [21] for HTTP extraction, and mmdump [1] for multimedia monitoring. One must also mention more generic platforms like IPSE [6] and Windmill [12]. As the Internet grows, the demand for a flexible monitoring system increases. Such a system can be used to ensure good performance while keeping pace with the rapid evolution of Internet protocols and services by enabling rapid implementation of dedicated monitoring tools. Unfortunately, existing network monitoring tools remain too specific. They are designed to collect information required for some particular analysis. They often depend on a particular version of a protocol, or a particular configuration of the underlying infrastructure. For instance, HttpFilt only works for HTTP/1.0. IPSE assumes the existence of a gateway where one observes the entire traffic within the monitored organization. Such dependencies make most existing tools redundant if the targeted protocol evolves or the assumed configuration changes. Also, it makes them difficult to adapt and cope with new problems. This paper presents Pandora,1 a flexible and extensible network monitoring platform that can be easily adapted to monitor new Internet protocols or application-specific ones, while still offering good performance. Pandora uses passive network monitoring to reconstruct high level protocols while keeping track of lower level events. It provides basic building blocks implementing the commonly used analysis. The rest of the paper is organized as follows: Section 2 presents our design goals for Pandora. Section 3 describes the architecture of the system, while Section 4 describes how it is realized. Then, Section 5 focuses on the implementation. Next, we consider two examples of use of Pandora in Section 6; then we discuss the performance of the system in Section 7. Finally, we compare Pandora to related work in Section 8 and present some concluding remarks in Section 9.
2 Design GoalsOur design has four main goals: monitoring a system should not affect the system's behavior; the tool should be fast enough to monitor high-bandwidth links; user privacy must be preserved; and the tool must be flexible and simple enough to allow reuse in diverse applications.
2.1 Preserving the Quality of ServiceA monitoring tool should perform its work without being noticed by the system or its users. In particular, it should not introduce artificial perturbations into the environment. It should also not degrade the quality of service provided to the users of the system. Although easier to realize, we decided not to implement the tool as an active element of the system: a proxy, for example, could be used to intercept the traffic and to log information. However, such an active tool necessarily has an impact on the system's performance; in the case of a failure, for example, the monitored service could be interrupted. Therefore, we decided to use passive network monitoring. Such a tool captures the packets on the network and treats them without interfering with the actual traffic. This choice implies in particular that we must be able to deal with packet losses, without the opportunity to request the sender for packet re-transmission.
2.2 Performance IssuesA monitoring tool can be used to trigger a fast reaction to certain events. For example, one could decide to modify a Web cache's configuration because of a decrease in the observed quality of service. Therefore, the monitoring tool must be able to process all packets in real-time; this means that it cannot be designed only to store packets and process them off-line. Our system must be able to monitor medium-speed links, such as a 100 Mb/s Ethernet and a T3 wide-area link. Therefore, the design of the tool must be light enough to accommodate such a traffic. Moreover, it should be able to deal with load peaks which can occur frequently in networking systems.
2.3 Preserving User PrivacyA serious concern when monitoring a system is to preserve user privacy. Therefore, we should not output personal information such as which Web pages a particular user has accessed. Yet, to have enough insight into the system's behavior to provide interesting results, we often need precise information about user behavior. We consider that there must be a tradeoff between user privacy and the level of details that are provided by the monitoring tool. Depending on the planned use of the collected information, different levels of trace "anonymization" must be used. Therefore we consider that privacy should be treated as a policy (hence flexible) and that the system should only enforce a level of privacy compatible with the study to be done.
2.4 Ease of Use and DeploymentWe anticipate that the monitoring system will be used for various purposes: gathering traffic traces for several Internet protocols (e.g. HTTP, DNS or ICP), comparing network overheads for different protocols stacks, or debugging distributed applications. This list of possible uses of the system is of course not exhaustive. An administrator should be able to use the same monitoring tool for numerous different purposes easily. Therefore, the system must provide useful default options while being easily customizable. Moreover, it should not require specific hardware, and it should be portable across several, widely used, platforms. Finally, new protocols arise every day that people might want to analyze. Also, it should be easy to add new protocol-specific elements to the system.
3 ArchitecturePandora is designed as a stack of monitoring components. Each component encapsulates an elementary monitoring task (e.g. IP layer reassembly, TCP layer resequencing, etc.). We first illustrate the problem and its solution with the example of HTTP monitoring; then, we describe the general design of the platform.
3.1 Example of HTTP ExtractionThis example consists of gathering the Web traffic generated by a given user community. Such traces can lead to a better understanding of traffic patterns, and hence to the design of better protocols and tools. The protocol we need to monitor here is HTTP/1.1 [5]. HTTP follows a request/response model. Meta-data carried by headers are line-oriented and use textual attributes and values. Version 1.1 of the protocol introduces the possibility of making persistent connections between clients and servers and of pipelining requests and responses (not waiting for the other endpoint to reply before sending additional data on the same connection). The libpcap [10] library is used to capture any packet which passes through the network. It provides raw network packets, i.e. arrays of bytes. To extract the useful information from such packets, we need to reconstruct the HTTP sessions. First, we remove the link layer headers (the Ethernet headers, for example). This provides an IP packet. IP packets can be fragmented when traveling through the networks. Therefore, we need to reassemble the fragments (based on the IP headers). Once the reassembling is done, we can extract a TCP packet. Based on the TCP headers, we can determine which TCP stream it is part of, its proper place in the stream, etc. After demultiplexing and ordering TCP packets, we obtain the HTTP stream. We finally have to parse the HTTP header fields in order to obtain the HTTP meta-data. Finally, the request meta-data must be matched with the corresponding response meta-data before being output.
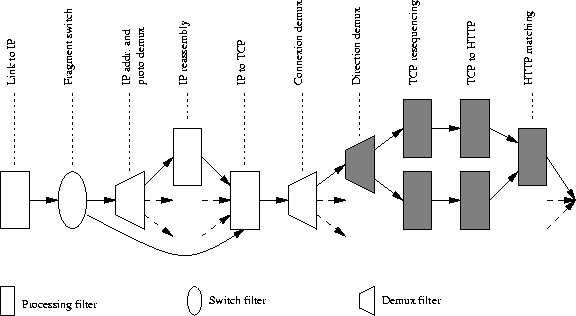
3.2 Basic ComponentsAs one may notice from the above example, a few elementary tasks appear, namely: IP reassembly, TCP resequencing and HTTP request/response matching. The only dependence between those tasks is the order in which they are performed. These tasks operate on packet flows rather than on individual packets. A packet flow is a sequence of packets related to the same higher-level entity (an IP packet for IP fragments, or a connection for TCP packets for example) exhibiting temporal locality. The notion of temporal locality depends on the nature of the flow itself, and can be seen as a threshold beyond which the flow is considered to be closed (a similar but more restrictive definition is given in [4]). In our example, a packet flow could be the set of all fragments -- including duplicated ones -- forming a single IP packet, or the set of all TCP packets sent from a browser to a Web server, containing HTTP requests. To capture the separate tasks that must be performed to produce the trace, and the order in which they must be proceeded, we define two basic notions: monitoring components and component stacks. A monitoring component (or simply, component) is responsible for a specific elementary task, while the stack is the structure where these components are chained together. A component may be considered as an operator on packet flows: it takes some flow as input, performs its work on it and then produces a flow of a different nature as output. Thus a component designed to perform IP reassembly transforms a flow of IP fragments into a flow of IP packets. A component relies only on the properties of its input. In particular, it does not have to know about the other components in its stack. This lets us replace a component by an equivalent one, or to introduce new components into the stack with no effect on the rest of the stack. For example, imagine that we want to encrypt the data collected (a perfectly legitimate issue); we have only to add a component that will encrypt IP addresses and URLs, after the HTTP protocol has been parsed. Many different monitoring experiments can be conducted without effort, if all the required components exist, or at minimal cost concerning only the development of the missing ones. Using components makes it easier to debug the monitoring path; effort can be concentrated on the optimization of components that constitute bottlenecks. The stack determines how components are chained. It represents an ordered set of components through which packets flow from one end to the other. It is important to notice that, in such a structure, each component has exactly one input and one output; in other words, there is a single, linear data flow for the entire stack. Such a simple stack model has two drawbacks. First, packets that belong to distinct connections are merged into an unique flow. This implies that every components that operates on separate packet flows will have to perform the demultiplexing on its own, since having only a single output is equivalent to re-multiplexing everything before passing packets to the next component. With respect to our example, packets coming from all HTTP connections are captured and delivered to the system interleaved, and demultiplexing must occur at IP, TCP and HTTP level. Second, this simple stack model (with a unique data flow) makes it impossible to shortcut some of the processing components, even if we know a priori that this will not be necessary: all packets must pass through each component. For example, we stated that IP packets could be fragmented, yet rather few are. Given that this property can be determined early (by simply looking at IP flags), why should we make them all pass through the reassembly components (demultiplexing and effective reassembly)? These may look like straight-forward, standard problems, but it requires some careful thought to fit them easily into the component framework.
3.3 Generalized StacksThe two limitations of the simple stack model we mentioned above have led us to extend this model by introducing control components. They allow several data flows to coexist in a single stack. This approach permits us to save resources and avoids unnecessary component traversals. Furthermore, taking flow control mechanisms out of processing components permits component developers to concentrate their efforts on the precise functionality they want to implement. The control components are the following:
Figure 1 shows one solution for the Web trace collection example that uses switch and demux components. The "connection demux" receives TCP packets from the IP to TCP extraction component. It identifies which flow each packet belongs to. For each flow, it dynamically creates a "direction demux" which in turn identifies in which direction of the flow each packet is going (from the client to the server, or the other way round). TCP packets are then passed to components performing TCP resequencing and HTTP reconstruction. Finally, the two opposite HTTP streams (i.e. a stream of requests and the corresponding stream of responses) are given to the HTTP matching component, which determines which request corresponds to which response.
3.4 Benefits of the Stacking Approach
3.5 Configuration
Figure 2 presents a sample configuration file for an application that logs packets in distinct log files according to their transport layer protocol (TCP, UDP or ICMP). In details: packets first flow through the ipfragswitch switch component. This component makes IP fragments go into the IP reassembly sub-stack and let the other not-fragmented packets skip this part. Inside the IP reassembly sub-stack, packets are demultiplexed according to their IP addresses, protocol number and identifier in the ipfragdemux demux component. Then the ipreass component reassembles demultiplexed IP fragments. The timeout specified in the corresponding option section tells the filter to flush any incomplete packet after a 60 seconds inactivity period. At this point, all IP packets reaching the ipproto component are complete IP packets. This switch component forwards them to distinct sub-stacks according to their transport protocol. The options it is given tells it what are the actual branch indexes used. TCP packets go to the first one where they are parsed and written to a log file. As are UDP and ICMP packets to the second and the third sub-stack, respectively. Finally, all packets with a different protocol skip this and are discarded.
The configuration file is made of several sections.
The stack section (beginning with a [stack] tag) describes the components used and how they are chained.
We designed a small language to specify this. Its grammar is presented
in Figure 3.
A stack is composed of a number of components. The simple components are identified only with their name.2 The switch and demux components are described by their name as well as the definition of their sub-stacks: the demux is given the definition of the sub-stack to instantiate when identifying a new session; the switch is given the list of sub-stacks to which it can forward packets.
Other sections of the configuration file allow us to set up options
for any component mentioned in the stack section. Such option sections
start with the name of the component enclosed in square brackets: for
example, [ipfragdemux]. In addition, components of the same type
are numbered from left to right, starting at 0, in order of
appearance. This is needed in cases where several instances of the
same component are used, and one wants to set different options for each
instance. That is, one creates an option section identified by this
component name followed by its rank (e.g. [output(0)]).
Unnumbered option sections apply to all components of the specified type.
Inside an option section, each line describes the setting of an option
according to the following
syntax:
4 Stack InstantiationOnce the stack and component options have been parsed, one has to instantiate the stack. This involves dynamically building the sequence of components and linking them appropriately. The difficulty stems from the fact that none of the components know the topology of the processing graph. To address this problem we need an independent entity which holds this graph and the configuration parameters to be passed to different instances of components. We call this entity the dispatcher.
The dispatcher is responsible for creating components -- which includes
properly setting any dynamic options it might need, and building
the ordered sequence of components specified in the stack description.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
[stack] ipfragswitch ( ipfragdemux < ipreass > ) ipcnxdemux < scanudp - scanicp - icpdemux < matchicp > > output |
The first part of the stack (up to ipcnxdemux) is dedicated to IP reassembly and has the same structure we discussed in Section 3. The ipcnxdemux component demultiplexes packet according to their source and destination IP addresses, but no discrimination is made on the direction of the connection (i.e. we make no distinction between packets coming from the requesting host or from the responding host). The scanudp component extracts UDP packets from IP ones and passes them to scanicp component. The latter in turn produces ICP packets. These are demultiplexed according to their request identifier in the icpdemux component. Then, given our demultiplexing steps, only the two matching ICP messages are finally passed to the matchicp component, whose only work is to associate them in a single ICP transaction packet.
Figure 5 shows the configuration file of the Web traffic collection system.
|
[stack]
tcpscan - tcpcnxdemux < tcpdirdemux < tcpreseq - httpscan > anonymize - httpmatch > output |
The tcpcnxdemux component demultiplexes packets according to their connection identifier (the 4-tuple IP address and port for the source and the destination) independent of the direction of the flow. The separation of both flows is made by the tcpdirdemux component. Once TCP packets are resequenced, the httpscan components extract HTTP messages (requests and responses) from each flow. Then, these messages are multiplexed, so that requests and their corresponding responses belong to the same flow. After being anonymized, requests and responses are matched to each other (without any interference from messages of other connections).
Performance is a major issue that we set out to address. Indeed, packets are buffered by the system in a kernel queue which is emptied by the monitoring process. When the queue is filled up,5 packets are discarded by the system. It is a common belief that flexibility has a price: this could jeopardize our performance goal. After having described our experimental environment, we will show the results of several tests meant to measure respectively the overheads due to our flexible design, those related to demultiplexing and Web traffic collection. Finally we will quantify the effective throughput of Pandora when used to collect Web traffic in more realistic conditions.
The workstation used to run these tests was a DEC Personal Workstation using a 21164A processor at 500 MHz, with 684 MB of RAM. We chose relatively small trace files (500000 packets) so that their entire content can remain in main memory between successive runs.
All times measured are the sum of system and user execution time (in seconds) as given by getrusage on this workstation (still used for light office tasks at the same time).
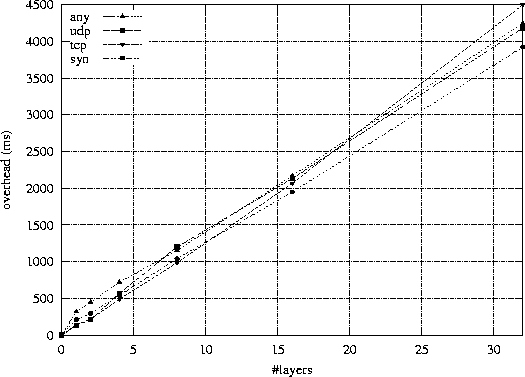
To measure the cost of layering we ran Pandora against four traces (whose characteristics are presented in Table 2) with a variable number of identical components that are only passing packets to their successor component as soon as they receive them. After traversing these identity components, packets are silently discarded. This gives us the minimal processing time per packet per component. We also ran a test with no identity component; this acts as a reference: its execution time represents the amount of time spent in reading the trace file, and in the creation and the destruction of packets.
Figure 6 plots the measured overhead (compared to our reference) for each of the traces. This shows approximatively 130 ms6 per component overhead for 500,000 packets (i.e. 260 ns per packet, per component). As one might expect, this value does not depend on the size of packets. This overhead is relatively small, compared to the cost of effective computation time. We can safely say that the layering structure of Pandora has little impact on performance.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
We want to quantify the cost of demultiplexing packets according to their connection identifier. The test consists of extracting TCP packets from traces with various characteristics (presented in Table 3), demultiplexing them, passing them through the identity component and finally discarding them, while timing out (with different timeout values) inactive demultiplexed branches. Our reference is the time taken to extract TCP packets from the traces.
The results are shown in Table 4. It appears that,
though the demultiplexing problem is very simple, its cost is rather
high. It ranges from 2.1 ![]() s to more than 20
s to more than 20 ![]() s per packet,
and has an average around 8
s per packet,
and has an average around 8 ![]() s for the two "realistic" traces:
TCP and WWW. First, this confirms that the "layering only" overhead
is small (only 0.26
s for the two "realistic" traces:
TCP and WWW. First, this confirms that the "layering only" overhead
is small (only 0.26 ![]() s per packet) and highlights the importance
of the algorithm and the data structures used for demultiplexing.
Second, it shows that it is very difficult to predict what the cost of
demultiplexing will be: it depends on the size of the demultiplexing
table and the ratio of packets inserting new entries in the map, and
the quantities are very hard to estimate a priori.
s per packet) and highlights the importance
of the algorithm and the data structures used for demultiplexing.
Second, it shows that it is very difficult to predict what the cost of
demultiplexing will be: it depends on the size of the demultiplexing
table and the ratio of packets inserting new entries in the map, and
the quantities are very hard to estimate a priori.
As a final evaluation we use our HTTP reconstruction example. The tasks performed are only a subset of those we previously described: we did not perform IP reassembly (we filtered out fragmented packets), nor the on-line anonymization. As for the previous test, we timeout idle connections (with a timeout value of 255 seconds). To compute the overhead, we take for reference the time needed to reorder TCP packets.
Results are shown in Table 6. It presents the cost of
some realistic processing. On average, we require about 50 ![]() s per
packet. We see then that the layering cost (i.e. splitting into two
steps what could be done in one) now represents only 0.52 % of the
average time to process a packet. Differences between execution time
mainly comes from the different average length of requests.
s per
packet. We see then that the layering cost (i.e. splitting into two
steps what could be done in one) now represents only 0.52 % of the
average time to process a packet. Differences between execution time
mainly comes from the different average length of requests.
Table 7 shows the results of these tests. This leads us to think that Pandora can cope with most medium bandwidth links (100 Mb/s), without suffering from too many packet losses. Indeed, except for the WWW-PP trace (where we spent nearly 35 % of our time in writing records), the throughput achieved represents three quarters of the maximum bandwidth. Yet, these results show that Pandora is not fast enough to monitor high bandwidth network, dedicated to HTTP (like ISP backbones).
Some intrusion detection systems (IDS) have addressed similar issues. In particular, Network Flight Recorder [16] and Bro [14]. Such tools are used to detect network attacks in real-time, and allow fast response. They both split their processing of incoming packets into distinct stages, each being the responsibility of a specific component. This approach gives such tools the flexibility and the extensibility they require (one cannot know what kind of attack will have to be monitored in the future). They also provide an advanced configuration language to specialize the behavior of the engine. Compared to them, Pandora, uses finer-grained components, and its configuration relies more on the chaining of specialized components. IDS have a fixed-size stack because packet processing to be performed is well-known and is not likely to change. This allows better performance (we saw Section 7.2 that layering has still a cost), but prevents from using the tool for a different goal.
Among existing monitoring tools, tcpdump [11] was the first to be widely used. Its output (a line per packet received) is invaluable for simple network monitoring purpose. For complex cases, the software offers the possibility of dumping a trace of complete packet contents for off-line analysis. Yet, this approach may not be acceptable in situations where the volume of data is too big -- on busy, high-speed links, it is not uncommon to collect more than 1 Gigabyte of data within 15 minutes.
Ian Goldberg's IPSE [6] is another recent approach to network monitoring: built as Linux kernel modules, it promises good performance. Yet, such construction does not allow portability and complicates the development of the tool itself. Unfortunately, this software has not been sufficiently documented, preventing us from further investigation.
Windmill [12] is the closest tool to Pandora and looks very similar in spirit to it. Windmill is a platform designed to evaluate protocol performance, via a set of dynamically loaded experiments. Its authors focused on large set of such experiments, each using possibly overlapping components to match their input packets. This lead them to develop their own packet filter (WPF) and to design their protocol modules to avoid redundancy among experiments (e.g. not reassembling twice IP fragments needed by two distinct experiments). Windmill implements protocol extraction through a set of modules statically chained to each other: the inner-most module -- i.e. the higher protocol level -- recursively calls lower layers, first to let them update their internal state, and then to ask for information they need. For example, the BGP module first lets the TCP module process the packet, and only then asks TCP whether the packet is carrying a FIN flag. In contrast to Pandora, Windmill does not use a "pure" stacking approach and thus perfectly illustrates benefits and drawbacks of both techniques. For example, with Pandora, adding or removing data encryption support, or changing of encryption algorithm is a simple matter of configuration that can be done at run time. Also, implementing an IPv6 module in Windmill can be tricky. On one hand, if we use different interfaces from the IPv4 module, all transport-layer modules have to be updated. On the other hand, if the interface is the same, this prevents from using both IPv4 and IPv6 layers in the same program. However, Windmill should outperform Pandora when executing similar tasks.
With respect to Web traffic monitoring, which motivated the development of Pandora in the first place, several tools have been proposed in the recent past.
HttpFilt and HttpDump [21] were one of the first attempts to construct such specialized tools. No other tool have achieved such complete on-line processing of packets. Unfortunately, their limited performance have lead the authors to give up their development, restricting them to only HTTP/1.0 transactions.
BLT [2,3] is the more promising one. It is meant to provide on-line HTTP traces, related with lower-layers events (TCP aborted connections, packet loss rate or duplicated, etc.) at a high performance level. With a machine comparable to ours (a 500-MHz Alpha workstation), BLT was able to capture a 12 day trace on an FDDI ring, handling more than 150 millions packets a day (an average of about 1750 packets per second) with a packet loss rate of less than 0.3%. Compared to Pandora, BLT claims better performance. However, unlike Pandora, BLT performs HTTP request/response matching (which is an essential stage in Web logging) off-line.
We regret that none of these recent monitoring tools (namely IPSE, Windmill and BLT) have been publicly released so far, which prevented us from further comparing them with our tool and design choices. This is also partly why we decided to develop Pandora from scratch.
Nevertheless, Pandora still needs improvements at various levels. First the stack configuration process should benefit from a more user-friendly interface. We also plan to implement a tool that can check stack description validity, in order to avoid run-time errors when feeding a component with packets it does not expect. Last but not least, we must continue developing monitoring components and improving the existing ones.
Pandora has already been used to retrieve HTTP traces during a one month period (representing a total amount of more than six million requests). These traces were then used in Saperlipopette! [15], a tool designed to help dimension proxy cache infrastructure.
More generally, Pandora is meant to facilitate the development of access infrastructure in the ever-growing Internet. It can also be used as a way to compare the various solutions offered to address specific problems. The number and the diversity of tools developed by the research community in the recent past that are related to these issues prove that it corresponds to a real need, and highlight as well the lack of a flexible monitoring tool that could satisfy these.
|
This paper was originally published in the
Proceedings of the 2000 USENIX Annual Technical Conference,
June 18-23, 2000, San Diego, California, USA
Last changed: 7 Feb 2002 ml |
|