


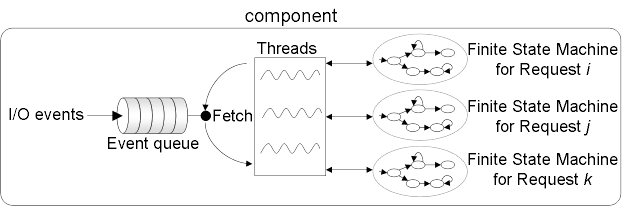
 |
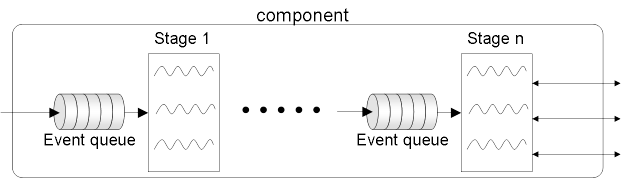 |
 |
 |
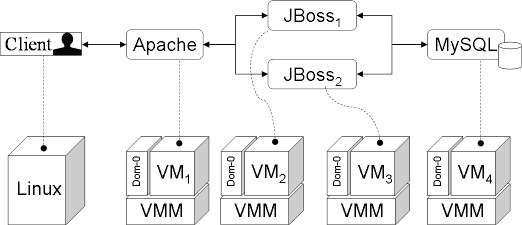 |

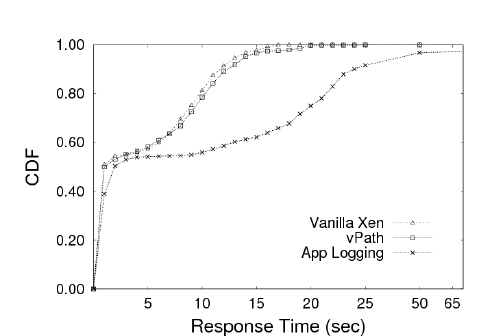
| Response time in seconds | Throughput(req/sec) | ||
| Configuration | (Degradation in %) | (Degradation in %) | |
| Average | 90th percentile | Average | |
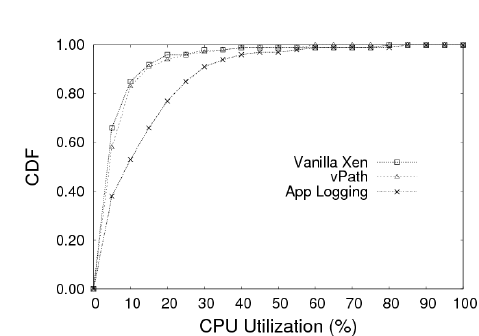
| Vanilla Xen | 4.45 | 11.58 | 4.88 |
| vPath | 4.72 (6%) | 12.28 (6%) | 4.59 (6%) |
| App Logging | 10.31 (132%) | 23.95 (107%) | 4.10 (16%) |
| Response Time in millisec | Throughput in req/sec | |
| (Degradation in %) | (Degradation in %) | |
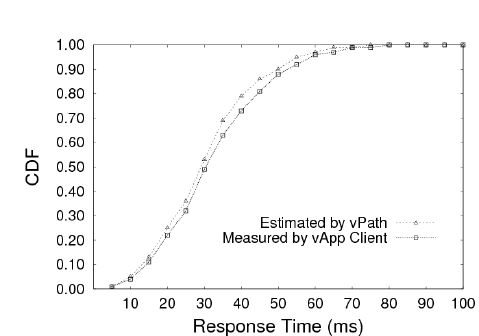
| Vanilla Xen | 597.2 | 628.6 |
| vPath | 681.8 (14.13%) | 593.4 (5.60%) |
| Response time (in sec) | Throughput (req/sec) | |||
| Configuration | Avg(Std.) | Overhead | Avg(Std.) | Overhead |
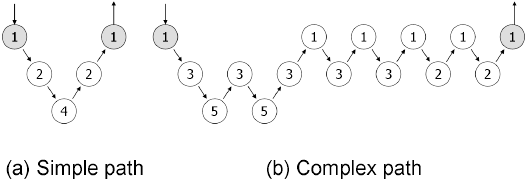
| Vanilla Xen | 1.69(.053) | 2915.1(88.9) | ||
| (1) Intercept Syscall | 1.70(.063) | .7% | 2866.6(116.5) | 1.7% |
| (2) Hypercall | 1.75(.050) | 3.3% | 2785.2(104.6) | 4.5% |
| (3) Transfer Log | 2.02(.056) | 19.3% | 2432.0(58.9) | 16.6% |
| (4) Disk Write | 2.10(.060) | 23.9% | 2345.4(62.3) | 19.1% |
 |
 |
 |