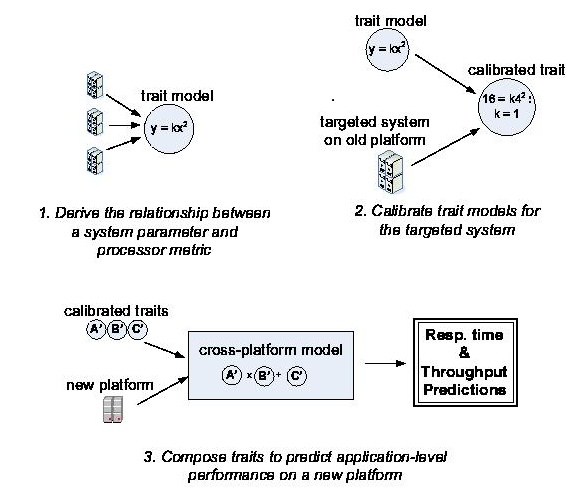
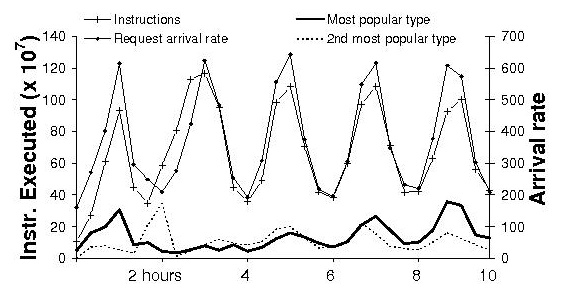
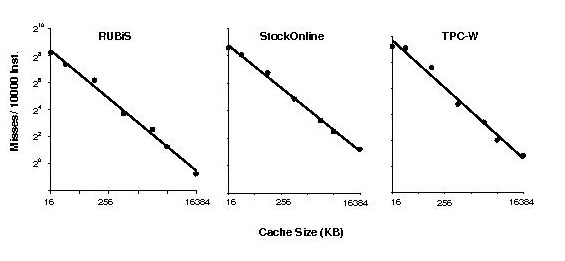
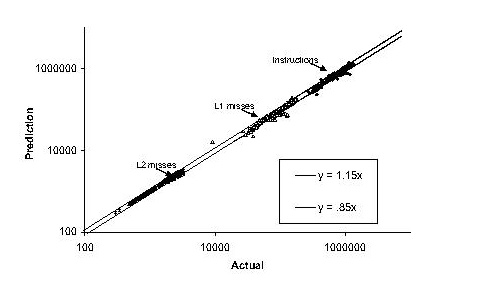
[9] P.
Barham, A. Donnelly, R. Isaacs, and R. Mortier. Using
magpie for
request extraction and workload modeling. In
OSDI,
Dec. 2004.
[10] G. Box
and N. Draper. Empirical model-building and re-
sponse
surfaces. Wiley, 1987.
[11] H.
Cain, R. Rajwar, M. Marden, and M. Liphasti. An ar-
chitectural
evaluation of java tpc-w. In HPCA, Dec. 2001.
[12] I.
Chihaia and T. Gross. Effectiveness of simple mem-
ory models
for performance prediction. In ISPASS, Mar.
2004.
[13] C.
Chow. On optimization of storage hiearchy. In IBM J.
Res. Dev.,
May 1974.
[14] R.
Doyle, J. Chase, O. Asad, W. Jin, and A. Vahdat.
Model-based
resource provisioning in a web service util-
ity. In USENIX
Symp. on Internet Tech. & Sys., Mar. 2003.
[15] P.
Ein-Dor and J. Feldmesser. Attributes of the perfor-
mance of
central processing units: A relative performance
prediction
model. CACM, 30(4):308–317, Apr. 1987.
[16] S.
Eyerman, L. Eeckhout, T. Karkhanis, and J. Smith. A
performance
counter architecture for computing accurate
CPI
components. In ASPLOS, Oct. 2006.
[17] X.
Fan, W. Weber, and L. Barroso. Power provisioning
for a
warehouse-sized computer. In ISCA, June 2007.
[18] G. D.
Fullerton. An evaluation of the gains achieved by
using
high-sped memory in support of the system pro-
cessing
unit. CACM, 32(9):1121–1129, 1989.
[19] M.
Goldstein, S. Morris, and G. Yen. Problems with fit-
ting to the
power-law distribution. In The European Phys-
ical
Journal B - Condensed Matter and Complex Systems,
June 2004.
[20] A.
Hartstein, V. Srinivasan, T. Puzak, and P. Emma.
Cache miss
behavior: is it sqrt(2)? In Conference on
Computing
Frontiers, May 2006.
[21] T.
Heath, A. Centeno, P. George, L. Ramos, Y. Jaluria,
and R.
Bianchini. Mercury and freon: Temerature emu-
lation and
management for server systems. In ASPLOS,
Oct. 2006.
[22] J.
Hennessey and D. Patterson. Computer architecture:
A
quantitative approach, fourth edition. In The Morgan
Kaufmann
Series, 2007.
[23] K.
Hoste, A. Phansalkar, L. Eeckhout, A. Georges,
L. John,
and K. Bosschere. Performance prediction based
on inherent
program similarity. In Int’l Conf. on Parallel
Architectures
& Compilation Techniques, Sept. 2006.
[24] W.
Huang, J. Liu, Z. Zhang, and M. Chang. Performance
characterization
of Java applications on SMT processors.
In ISPASS,
Mar. 2005.
[25] E.
Ipek, S. McKee, B. Supinski, M. Schultz, and R. Caru-
ana.
Efficiently exploring archtectural design spaces via
predictive
modeling. In ASPLOS, Oct. 2006.
[26] R.
Isaacs and P. Barham. Performance analysis in loosely-
coupled
distributed systems. In Cabernet Radicals Work-
shop,
Feb. 2002.
[27] R.
Jain. The art of computer systems performance analy-
sis. In Wiley,
1991.
[28] T.
Karkhanis and J. Smith. A first-order superscalar pro-
cessor
model. In ISCA, June 2004.
[29] M.
Karlsson, K. Moore, E. Hagersten, and D. Wood.
Memory
system behavior of java-based middleware. In
HPCA,
Feb. 2003.
[30] B. Lee
and D. Brooks. Accurate and efficient regression
modeling
for microarchitectural performance and power
prediction.
In ASPLOS, Oct. 2006.
[31] X. Li,
Z. Li, P. Zhou, Y. Zhou, S. Adve, and S. Ku-
mar.
Performance-directed energy management for main
memory and
disks. In ASPLOS, Oct. 2004.
[32] G.
Marin and J. Mellor-Crummey. Cross-architecture per-
formance
predictions for scientific applications using pa-
rameterized
models. In SIGMETRICS, June 2004.
[33] M.
Newman. Power laws pareto distributions and zipf’s
law. In Contemporary
Physics, 2005.
[34] S. B.
P. Shivam and J. Chase. Active and accelerated
learning of
cost models for optimizing scientific applica-
tions. In VLDB,
Sept. 2006.
[35] R. H.
Saavedra and A. J. Smith. Analysis of bench-
mark
characteristics and benchmark performance predic-
tion. ACM
Trans. Comp. Sys., 14(4):344–384, Nov. 1996.
[36] M.
Seltzer, D. Krinsky, K. Smith, and X. Zhang. The case
for
application-specific benchmarking. June 1999.
[37] P.
Shivam, A. Iamnitchi, A. Yumerefendi, and J. Chase.
Model-driven
placement of compute tasks in a networked
utility. In
ACM International Conference on Autonomic
Computing,
June 2005.
[38] A.
Smith. Cache memories. In ACM Computing Surveys.
[39] R.
Stets, L. Barroso, and K. Gharachorloo.
A de-
tailed
comparison of two transaction processing work-
loads. In IEEE
Workshop on Workload Characterization,
Nov. 2002.
[40] C.
Stewart, T. Kelly, and A. Zhang. Exploiting nonsta-
tionarity
for performance prediction. In EuroSys, Mar.
2007.
[41] C.
Stewart and K. Shen. Performance modeling and sys-
tem
management for multi-component online services. In
NSDI,
May 2005.
[42] E.
Thereska and G. Ganger. Ironmodel: Robust perfor-
mance
models in the wild. In SIGMETRICS, June 2008.
[43] D.
Thiebaut. On the fractal dimension of computer pro-
grams. In IEEE
Trans. Comput., July 1989.
[44] B.
Urgoankar, G. Pacifici, P. Shenoy, M. Spreitzer, and
A. Tantawi.
An analytical model for multi-tier inter-
net
services and its applications. In SIGMETRICS, June
2005.