
Figures 16, 17, and 18 show the accuracy impact of relaxed measurement intervals for load, network transmit bandwidth, and inter-node latency. For each of several update intervals longer than 5 minutes, we show the fraction of nodes (or, in the case of latency, node pairs) that incur various average absolute value errors over the course of the trace, compared to updates every 5 minutes (15 minutes for latency).
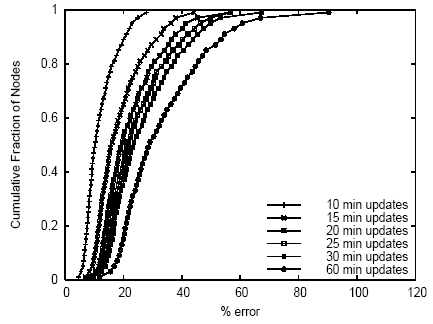
Figure 16: Mean error in 5-minute load average compared to 5-minute updates.
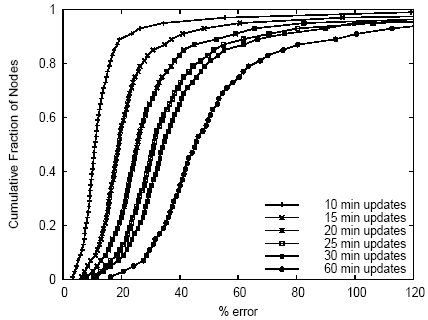
Figure 17: Mean error in 15-minute average network transmit bandwidth compared to 5-minute updates. Similar results were found for receive bandwidth.
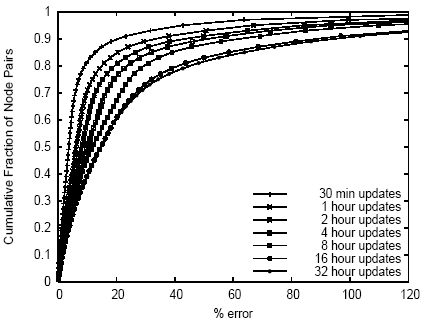
Figure 18: Mean error in inter-node latency compared to 15-minute updates.
We observe several trends from these graphs. First, latency is more stable than load or network transmit bandwidth. For example, if a maximum error of 20% is tolerable, then moving from 15-minute measurements to hourly measurements for latency will push about 12% of node pairs out of the 20% accuracy range, but moving from 15-minute measurements to hourly measurements for load and network bandwidth usage will push about 50% and 55% of nodes, respectively, out of the 20% accuracy range. Second, network latency, and to a larger extent network bandwidth usage, show longer tails than does load. For example, with a 30-minute update interval, only 3% of nodes show more than 50% error in load, but over 20% of nodes show more than 50% error in network bandwidth usage. This suggests that bursty network behavior is more common than bursty CPU load.
From these observations, we conclude that for most nodes, load, network traffic, and latency data can be collected at relaxed update intervals, e.g., every 30 minutes, without incurring significant error. Of course, the exact amount of tolerable error depends on how the measurement data is being used. Further, we see that a small number of nodes show significant burstiness with respect to network behavior, suggesting that a service placement infrastructure could maximize accuracy while minimizing overhead by separating nodes based on variability of those attributes, and using a relaxed update rate for most nodes but a more aggressive one for nodes with high variance.