|
USENIX '05 Paper
[USENIX '05 Technical Program]


A Hierarchical Semantic Overlay Approach to P2P Similarity Search
Duc A. Tran
Computer Science Department
University of Dayton
Dayton, OH 45469
duc.tran@notes.udayton.edu
One of the most important problems in information retrieval is similarity search. Informally, the problem is: given a similarity query, which can be a point query or a range query, we need to return a set of contents that are most relevant to the search criteria according to some semantic distance function. We propose EZSearch, a decentralized solution to this problem in the context of Peer-to-Peer (P2P) networks. EZSearch features the following for a network of 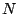 users. First, queries can be answered with users. First, queries can be answered with 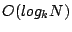 worst-case search time and low search overhead. Second, to maintain the hierarchy, a node keeps track of only worst-case search time and low search overhead. Second, to maintain the hierarchy, a node keeps track of only 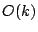 other nodes and failure recovery requires no more than reconnections; these overheads are independent of the network size. Last but not least, the number of objects whose indices are stored at remote nodes is small and, therefore, so are the costs of index migration, storage, and validity. other nodes and failure recovery requires no more than reconnections; these overheads are independent of the network size. Last but not least, the number of objects whose indices are stored at remote nodes is small and, therefore, so are the costs of index migration, storage, and validity.
We consider a P2P network where each node has a set of data objects to share with other nodes in the network. These data objects are described based on the vector space model used in information retrieval theory [1]. Each data object 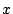 is represented as a is represented as a 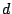 -term semantic vector -term semantic vector 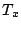 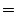 ( (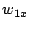 , , 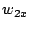 , .., , .., 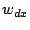 ), where each dimension ), where each dimension 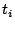 reflects the keyword, concept, or term associated with and reflects the keyword, concept, or term associated with and 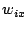 the weight to reflect the significance of in representing the semantic of . Without loss of generality, we assume that all the weight values belong to the interval [0, 1]. the weight to reflect the significance of in representing the semantic of . Without loss of generality, we assume that all the weight values belong to the interval [0, 1].
We employ the commonly used Cosine distance function to measure the semantic similarity between two objects and 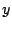 : :
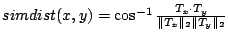 where where 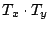 is the dot product between vectors and is the dot product between vectors and 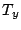 and and 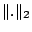 is the Euclidean vector norm. The smaller is the Euclidean vector norm. The smaller 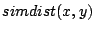 is, the more semantically similar are is, the more semantically similar are 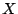 and and 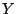 to each other. to each other.
We consider two types of queries: point queries and range queries. A point query is described by a term vector 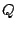 ( (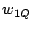 , , 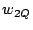 , .., , .., 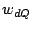 ). We expect to return those data objects such that ). We expect to return those data objects such that 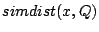 is minimum. In some applications, the user may also specify a small constant is minimum. In some applications, the user may also specify a small constant 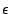 to find those objects such that to find those objects such that
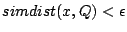 .
There are two types of range query, namely simple and composite. A simple range query is described by a hyperrectangular region [ .
There are two types of range query, namely simple and composite. A simple range query is described by a hyperrectangular region [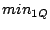 , , 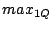 ] ]  [ [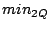 , , 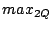 ] .. [ ] .. [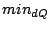 , , 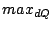 ]. A composite range query is a set of simple range queries. For a range query , we expect to return those data objects that belong to the region . While the system is aimed to be fully decentralized, we assume that a new user knows at least one existing user before the former can join the network. ]. A composite range query is a set of simple range queries. For a range query , we expect to return those data objects that belong to the region . While the system is aimed to be fully decentralized, we assume that a new user knows at least one existing user before the former can join the network.
The basic idea behind EZSearch is as follows. Peers (i.e., user nodes) are partitioned into clusters. Each cluster contains nodes having similar contents and manages a subspace of indices (peer_location 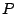 , term_vector ), or an index zone. For a search, the simplest solution is to scan all the clusters, which, however, would incur a linear search time. Alternatively, similar to using search trees for logarithmic runtime search, we can build a decision hierarchical overlay on top of these clusters such that the search scope will be reduced by some factor if the query is forwarded from a layer of the hierarchy to a lower layer. , term_vector ), or an index zone. For a search, the simplest solution is to scan all the clusters, which, however, would incur a linear search time. Alternatively, similar to using search trees for logarithmic runtime search, we can build a decision hierarchical overlay on top of these clusters such that the search scope will be reduced by some factor if the query is forwarded from a layer of the hierarchy to a lower layer.
For building the cluster overlay, we propose to use the Zigzag hierarchy, which we originally devised for streaming multimedia [2,3]. The main advantage of Zigzag is its capability to handle the dynamics of P2P networks. We first present Zigzag and then propose how similarity search can be fulfilled efficiently using this hierarchy.
Definition 1
[Zigzag hierarchy]
A Zigzag-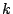 hierarchy of nodes is a multi-layer hierarchy of clusters recursively defined below: ( hierarchy of nodes is a multi-layer hierarchy of clusters recursively defined below: ( 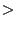 3 is a constant): 3 is a constant):
- Layer 0 contains all peers.
- If the number of peers at layer
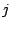 is greater than is greater than 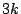 , they are partitioned into clusters whose size is in [, ]. Otherwise, we reach the highest layer, where peers form only a single cluster. The size of this highest-layer cluster is in [2, ]. , they are partitioned into clusters whose size is in [, ]. Otherwise, we reach the highest layer, where peers form only a single cluster. The size of this highest-layer cluster is in [2, ].
- A layer- cluster designates two member peers as its head and associate-head. The head automatically appears at layer (
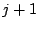 ). The cluster partition at layer () is the same as at layer . An exception applies to the highest-layer cluster in which only the head role is needed but the associate-head role is not necessary. ). The cluster partition at layer () is the same as at layer . An exception applies to the highest-layer cluster in which only the head role is needed but the associate-head role is not necessary.
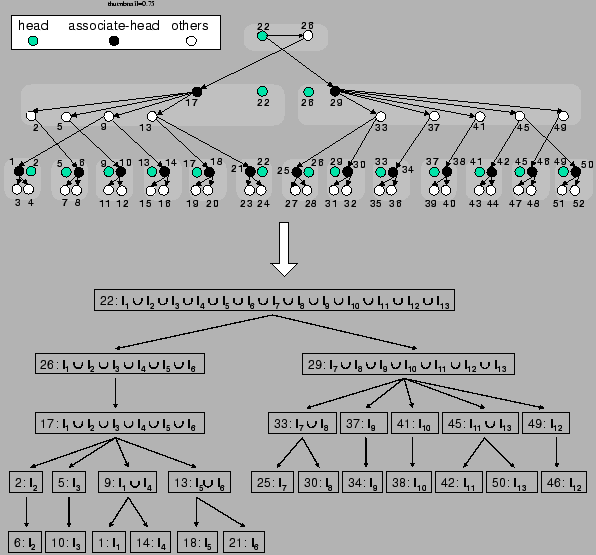
An illustration is given in the top diagram of Figure 1, where 52 nodes are organized into a Zigzag-4 hierarchy. Hereafter, we denote by 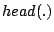 and and 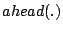 the head and associate-head, respectively, of a cluster or a peer. Since a peer may have different associate-heads at different layers, we use the notation the head and associate-head, respectively, of a cluster or a peer. Since a peer may have different associate-heads at different layers, we use the notation 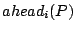 to refer to the associate-head of at layer to refer to the associate-head of at layer 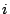 . For instance, in Figure 1, . For instance, in Figure 1, 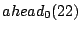 = 21, = 21, 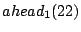 = 17. Below are the terms we use for the rest of the paper: = 17. Below are the terms we use for the rest of the paper:
- Foreign head: A non-head non-associate-head clustermate of a peer at layer
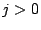 is called a ``foreign head" of layer-( is called a ``foreign head" of layer-(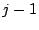 ) clustermates of . ) clustermates of .
- Super cluster: A layer- () cluster is the super cluster of any layer-
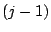 cluster whose head appears in the layer- cluster. cluster whose head appears in the layer- cluster.
Figure 1:
Top diagram: Connectivity in a zigzag-4 hierarchy of 52 nodes; Bottom diagram: Corresponding index zone assignments
 |
Definition 2
[Connectivity in Zigzag hierarchy]
(illustrated by the top diagram of Figure 1)
- Intra-cluster connectivity: In a cluster, the associate-head has a link to every other non-head peer. E.g., in Figure 1 (top diagram), associate-head 17 of its layer-1 cluster has a link to all of its layer-1 non-head clustermates (peers 2, 5, 9, 13). An exception applies to the highest-layer cluster in which all peers have a link from its head (because there is no associate-head for this layer).
- Inter-cluster connectivity: The associate-head of a cluster has a link from one of its foreign heads. E.g., in Figure 1 (top diagram), associate-head 18 at layer 0 has a link from peer 13, which is one of peer 18's foreign heads. There is an exception: for a second-highest-layer cluster, if its associate-head does not have a foreign head, the associate-head has a link from the head of the highest-layer cluster. For instance, associate-head 17 at layer 1 has a link from peer 26 which is the head of the highest-layer cluster.
The above rules guarantee a tree structure including all the peers; we call this tree the Zigzag tree. A Zigzag- hierarchy of peers provides the following desirable properties: (see [3] for complete proofs):
(1) The maximum nodal degree in the Zigzag tree is 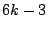 ,
(2) The maximum height of the Zigzag tree is 2 ,
(2) The maximum height of the Zigzag tree is 2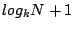 ,
(3) Recovery of a peer failure requires at most ,
(3) Recovery of a peer failure requires at most 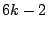 peer reconnections, and
(4) As peers join and leave, a cluster may be split or merged with another cluster to satisfy the [, ] cluster size constraint. The worst-case number of peer reconnections due to a split or merger is . peer reconnections, and
(4) As peers join and leave, a cluster may be split or merged with another cluster to satisfy the [, ] cluster size constraint. The worst-case number of peer reconnections due to a split or merger is .
We propose to organize peers into a Zigzag hierarchy. Each cluster of this hierarchy is assigned a zone of the entire index space. Zone assignment is important to searching and follows the policy described below.
Definition 3
[Zone Assignment Policy]
- At layer 0: Each layer-0 cluster owns a non-overlapped index zone, which is a set of hyperrectangles
![$\{[\alpha_1, \beta_1] \times [\alpha_2, \beta_2] \times ... \times [\alpha_d, \beta_d]\}$](img54.png) , such that the union of all the zones of layer-0 clusters is , such that the union of all the zones of layer-0 clusters is ![$I=[0,1]^d$](img55.png) . This zone is known to both the head and associate-head of the cluster, and also said to be ``covered by", or ``owned by", the associate-head. The head will store the indices of those objects that belong to peers outside this cluster but lie inside its index zone. . This zone is known to both the head and associate-head of the cluster, and also said to be ``covered by", or ``owned by", the associate-head. The head will store the indices of those objects that belong to peers outside this cluster but lie inside its index zone.
- At layer : Each peer keeps a list of pairs
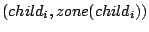 where where 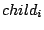 is a child node of in the Zigzag tree and is a child node of in the Zigzag tree and 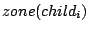 the index zone covered by . The index zone covered by peer , denoted by the index zone covered by . The index zone covered by peer , denoted by 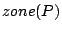 , is the union of these child zones. The index zone owned by a cluster is that covered by the associate-head of this cluster. , is the union of these child zones. The index zone owned by a cluster is that covered by the associate-head of this cluster.
As an example, we consider the hierarchy in Figure 1 and suppose that the index zones owned by the 13 layer-0 clusters are 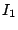 , , 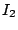 , .., , .., 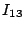 (respectively, from left to right). Thus, (respectively, from left to right). Thus, 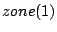 , , 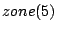 , , 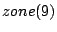 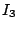 , etc. Because peer 9 has two children (peer 1 and peer 14), peer 9 keeps the value {(1, , etc. Because peer 9 has two children (peer 1 and peer 14), peer 9 keeps the value {(1, 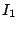 ), (14, ), (14, 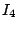 )} and )} and
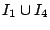 . The index zone assignments are similar for other peers and shown in Figure 1 (bottom diagram). Since peers other than the heads and associate-heads at layer 0 do not own any index zone, they are not present in this index zone tree. . The index zone assignments are similar for other peers and shown in Figure 1 (bottom diagram). Since peers other than the heads and associate-heads at layer 0 do not own any index zone, they are not present in this index zone tree.
The advantage of the zone assignment policy is its support for efficient search. A search query just follows the links in the Zigzag tree to branches that lead to the smallest index zone(s) containing the query. The next subsection details the search algorithm.
3.3 Search Algorithms
We assume that peers are already organized into a Zigzag hierarchy and index zones are assigned to peers and clusters according to the zone assignment policy. We present here only the algorithm for range-query search. Algorithms for point queries can be generalized from this algorithm and can be found in [4]. Supposing that a peer submits a range query , there are two scenarios:
Case 1: is a leaf in the Zigzag tree (e.g., peers 15, 36, 40 in Figure 1) and needs to process query . Since does not have any index zone information, it sends the query to its associate-head 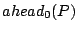 . computes . computes 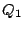
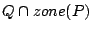 . If . If
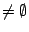 , some results of , that correspond to , can be found locally. Indeed, just needs to broadcast query to all layer-0 clustermates asking them to return to peer the objects inside . Furthermore, when , some results of , that correspond to , can be found locally. Indeed, just needs to broadcast query to all layer-0 clustermates asking them to return to peer the objects inside . Furthermore, when 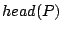 receives , if it stores any index (peer_location receives , if it stores any index (peer_location 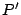 , term_vector ) such that , term_vector ) such that 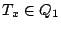 , asks peer to send object to peer . We must also return the results that correspond to query , asks peer to send object to peer . We must also return the results that correspond to query 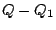 if if
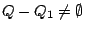 because these results are not in the local cluster. In this case, creates a new query because these results are not in the local cluster. In this case, creates a new query 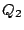 . How processes query is similar to the case below. . How processes query is similar to the case below.
Case 2: is a non-leaf node in the Z-tree (e.g., peers 22, 37, 42 in Figure 1) and needs to process query . In this case, must own a zone . Query is broken into two subqueries
and , which will be handled in parallel as follows.
- Query : If
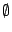 , nothing needs to be done. Else, the results of can be found in a layer-0 cluster reachable from peer . By looking at the list
for every child, breaks further into subqueries , nothing needs to be done. Else, the results of can be found in a layer-0 cluster reachable from peer . By looking at the list
for every child, breaks further into subqueries 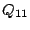 , , 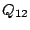 , ... where , ... where
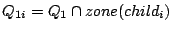 . (It is easy to prove that . (It is easy to prove that
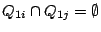 for every for every 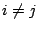 .) The results for .) The results for 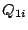 can be found in a layer-0 cluster reachable from . Hence, peer just needs to forward these subqueries to the corresponding child peers. The handling of such a subquery at the corresponding child resembles that at peer . can be found in a layer-0 cluster reachable from . Hence, peer just needs to forward these subqueries to the corresponding child peers. The handling of such a subquery at the corresponding child resembles that at peer .
- Query : If , nothing needs to be done. Else, the results satisfying cannot be found in any cluster reachable from . In this case, just needs to forwards to the parent of in the Zigzag tree. The handling of query at this parent resembles the way handles the original query .
Eventually, all the subqueries, created when necessary as above, will reach layer-0 clusters where the corresponding results can be found locally (like in Case 1). The collection of all these results is the final result for the original query initiated by peer .
The search path length is at most the maximum distance in hops between two peers in the Zigzag tree, or 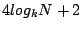 . The search overhead is proportional to the total number of peers contacted for all the subqueries, which depends on the range of the original query. In our performance study, we found that this overhead is indeed very small. . The search overhead is proportional to the total number of peers contacted for all the subqueries, which depends on the range of the original query. In our performance study, we found that this overhead is indeed very small.
3.4 Hierarchy Construction
Initially, there is only one peer in the network. It is the head of its self-formed cluster 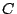 , which grows larger as subsequent peers join. The index zone owned by this cluster is , which grows larger as subsequent peers join. The index zone owned by this cluster is  ![$[0, 1]^d$](img90.png) and the ID of this zone is kept at the head node. When the cluster size exceeds , we need to partition into two smaller clusters, and the ID of this zone is kept at the head node. When the cluster size exceeds , we need to partition into two smaller clusters, 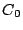 and and 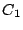 , whose sizes are in the interval [, ]. We propose to partition along a selected dimension , whose sizes are in the interval [, ]. We propose to partition along a selected dimension 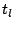 into two halves into two halves 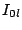 ![$[0, 1]^{l-1}$](img95.png) [0, 1/2) [0, 1/2) ![$[0, 1]^{d-l}$](img96.png) and and 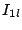 [1/2, 1] , each to be owned by and . It is possible that a peer in cluster has an object in (similarly, a peer in cluster may have an object in ). In this case, we store the index of this object in the other cluster. The number of such objects is called the index migration overhead. We want to minimize this overhead so that (1) the communication overhead due to index relocation is low, and (2) peers in the same cluster have highly similar objects. This is equivalent to minimizing [1/2, 1] , each to be owned by and . It is possible that a peer in cluster has an object in (similarly, a peer in cluster may have an object in ). In this case, we store the index of this object in the other cluster. The number of such objects is called the index migration overhead. We want to minimize this overhead so that (1) the communication overhead due to index relocation is low, and (2) peers in the same cluster have highly similar objects. This is equivalent to minimizing
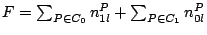 where where
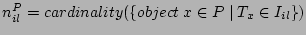 . The algorithm for this purpose is run by . The algorithm for this purpose is run by  - the head of cluster . Upon a request sent by , each peer in submits to a set of tuples ( - the head of cluster . Upon a request sent by , each peer in submits to a set of tuples (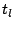 , , 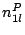 , , 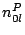 ), for all ), for all 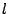 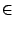 [1, ]. Upon receipt of those sets from all the member peers, we can devise a simple greedy but optimal algorithm for to find the best , , and dimension . The complexity of this algorithm is [1, ]. Upon receipt of those sets from all the member peers, we can devise a simple greedy but optimal algorithm for to find the best , , and dimension . The complexity of this algorithm is 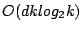 . .
Each cluster 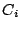 randomly selects two nodes as its head randomly selects two nodes as its head 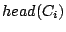 and associate-head and associate-head 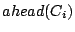 (the old head of cluster , however, is preferred to remain head of the newly created cluster it belongs to). The heads will automatically belong to layer 1 and form a new cluster. Since layer 1 now is the highest layer, only the head needs to be designated; this head is randomly chosen between the two member peers. The index zone owned by this cluster is the union of the zones owned by its child clusters; in this case, it is (the old head of cluster , however, is preferred to remain head of the newly created cluster it belongs to). The heads will automatically belong to layer 1 and form a new cluster. Since layer 1 now is the highest layer, only the head needs to be designated; this head is randomly chosen between the two member peers. The index zone owned by this cluster is the union of the zones owned by its child clusters; in this case, it is 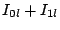 . .
Having the Zigzag hierarchy initially constructed, we need maintain it under network dynamics such as when a peer publishes or removes objects, and joins or quits the network. The detailed solutions to these sub-problems are presented in [4], which shows that removal of a peer requires peer reconnections, addition of a peer requires peer contacts, and addition or removal of an object also requires peer contacts.
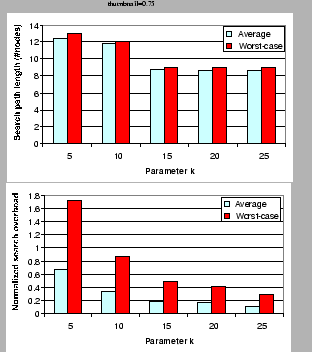
We conducted simulation for EZSearch. Peers arrived at rate 2 peers per second and might quit the network randomly at anytime. Thus the contents and indices stored in the network changed dynamically. The results were promising. For instance, Figure 2 shows the effect of the constant used in the Zigzag- hierarchy. In all scenarios, the query and any of its subqueries do not travel more than 12 nodes (among 10,003 nodes) before knowing the locations of the answers. Normalized search overhead is computed as
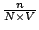 , where , where 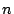 is the number of nodes a query and its subqueries visit during the search, the number of nodes currently in the system, and is the number of nodes a query and its subqueries visit during the search, the number of nodes currently in the system, and 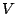 the volume of the query. For a query of volume 0.2, the broadcast-based search would incur a normalized search overhead of the volume of the query. For a query of volume 0.2, the broadcast-based search would incur a normalized search overhead of
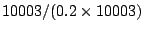 5. EZSearch has a normalized search overhead always less than 0.6 (on average) and 1.8 (worst-case), and much smaller when is larger. EZSearch therefore is fast and highly efficient. Our future work includes (1) refining the current algorithms for stronger index locality preservation within each cluster, and (2) considering various distributions of objects over peers. 5. EZSearch has a normalized search overhead always less than 0.6 (on average) and 1.8 (worst-case), and much smaller when is larger. EZSearch therefore is fast and highly efficient. Our future work includes (1) refining the current algorithms for stronger index locality preservation within each cluster, and (2) considering various distributions of objects over peers.
Figure 2:
After the system runs for 5000 seconds, 10003 nodes are active. Each node has up to 10 2-d objects. 2000 queries are generated with ranges following a Zipf distribution in which about 80% of the queries have a volume of approximately 20% of the unit hypercube
 |
- 1
-
M. Berry, Z. Drmac, and E. Jessup.
Matrices, vector spaces, and information retrieval.
SIAM Review, 41(2):335-362, 1999.
- 2
-
D. A. Tran, K. A. Hua, and T. T. Do.
Zigzag: An efficient peer-to-peer scheme for media streaming.
In IEEE INFOCOM, San Francisco, CA, March-April 2003.
- 3
-
D. A. Tran, K. A. Hua, and T. T. Do.
A peer-to-peer architecture for media streaming.
IEEE Journal on Selected Areas in Communications, 22(1),
January 2004.
- 4
-
D. A. Tran and H. Nguyen.
EZSearch: Fast and scalable similarity search in peer-to-peer
networks.
Unpublished, January 2005.
A Hierarchical Semantic Overlay Approach to P2P Similarity Search
This document was generated using the
LaTeX2HTML translator Version 2002-2-1 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons main.tex
The translation was initiated by on 2005-02-14
2005-02-14
|


