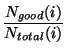| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX '04 Paper
[USENIX '04 Technical Program]
Email Prioritization: reducing delays on legitimate
mail
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| type | server1 | server2 | ||
| number | % | number | % | |
| rbl | 256,700 | 19 | 207,144 | 18 |
| open relay | 119,161 | 9 | 95,536 | 8 |
| other checks | 112,555 | 8 | 81,170 | 7 |
| total blocked | 488,416 | 36 | 383,850 | 34 |
| total accepted | 855,228 | 64 | 755,565 | 66 |
| total attempts | 1,344,960 | 100 | 1,139,415 | 100 |
| type | server1 | server2 | ||
| number | % | number | % | |
| good | 260,348 | 30 | 262,941 | 35 |
| spam | 497,554 | 58 | 414,234 | 55 |
| virus | 2,749 | 0.3 | 2,371 | 0.3 |
| undeliverable | 364,487 | 43 | 298,169 | 39 |
| total accepted good | 260,348 | 30 | 262,941 | 35 |
| total accepted junk | 594,880 | 70 | 492,624 | 65 |
Both servers subscribed to real-time blacklists, and performed other checks on the sender's address before accepting messages. These mechanisms rejected around 34-36% of incoming messages (see Table 2). However this is only partially effective at reducing spam, as around 65-70% of the accepted mail is junk, as shown in Table 3.
Table 3 shows a breakdown of accepted messages. The values for spam and virus reflect messages that were flagged as such in the logs. A message was deemed undeliverable if on the first delivery attempt more than half of the recipients failed. The good messages are those that are left: not virus, spam or undeliverable. The table shows the enormous volume of mail that is junk (65-70% of all accepted mail). This is consistent with other measures of the prevalence of spam (15). What is also surprising is the number of undeliverable messages. These appear to be mostly spam--of the 364,487 undeliverable messages for server1, only 94,735 (26%) were not classed as spam or virus. A likely cause is ``trolling'' (12,1), where spammers send messages to automatically-generated usernames at known domains, hoping that these correspond to genuine email addresses. This figure is far too high to be explained by mistyped addresses, corrupted mailing lists or servers that are offline. Assuming that nearly all of the undeliverable messages are spam suggests that a significant proportion are not being classified correctly by the spam filter. This in turn suggests that the measure for ``good'' in the table is optimistic: it includes some spam messages. Overall these figures are alarming, as they show how many resources are wasted in passing junk emails through the email system.
Table 4 shows the number of servers that send (only) good mail, (only) junk mail, and a mixture, together with the number of messages sent. A small proportion of servers (11%) send only good mail, and these are responsible for a similar proportion of the messages (11%). By contrast, the overwhelming majority of servers send only junk mail (79%) but generate a relatively small proportion of the messages (48%), implying that each server sends few messages. The mixed class contains data for servers that sent at least one good and one junk mail. This includes those that send mostly good with the occasional junk (e.g. a mistyped address, a false positive spam detection), or those that send mostly junk with the occasional good (e.g. a spammer whose spam occasionally evades spam detection), or a more even mixture that might be obtained from an aggregating mail server (e.g. an ISP). This class is a small proportion of the servers, but generates a large proportion of the messages.
| type | servers | messages | ||
| number | % | number | % | |
| server1 | ||||
| good | 24,407 | 11 | 97,553 | 11 |
| junk | 178,762 | 79 | 413,725 | 48 |
| mixture | 23,416 | 10 | 343,950 | 40 |
| server2 | ||||
| good | 20,508 | 10 | 80,082 | 11 |
| junk | 157,467 | 80 | 344,669 | 46 |
| mixture | 18,390 | 9 | 330,814 | 44 |
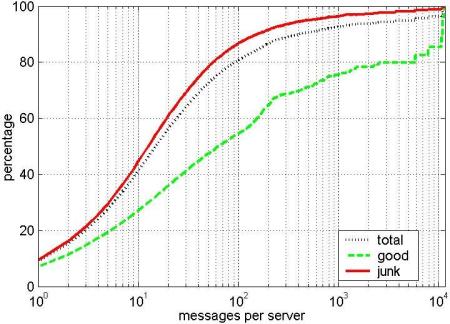
Figure 1 shows the same effect, but broken down by how many messages each server has sent. The figure was constructed by counting how many messages of each type (good/junk) each server sent, and plotting the cumulative percentage of total messages against the number of messages per server. There are three lines, for good, junk and the total.
|
The line for junk mail shows that most of the junk mail comes from servers that send fewer than 100 messages. In fact 45% of junk mail comes from servers that send fewer than 10 messages. On the other hand, good mail is more likely to come from servers that send many messages. The ``total'' line is a combination of these two effects, and is more influenced by the junk mail as that makes up the bulk of the messages.
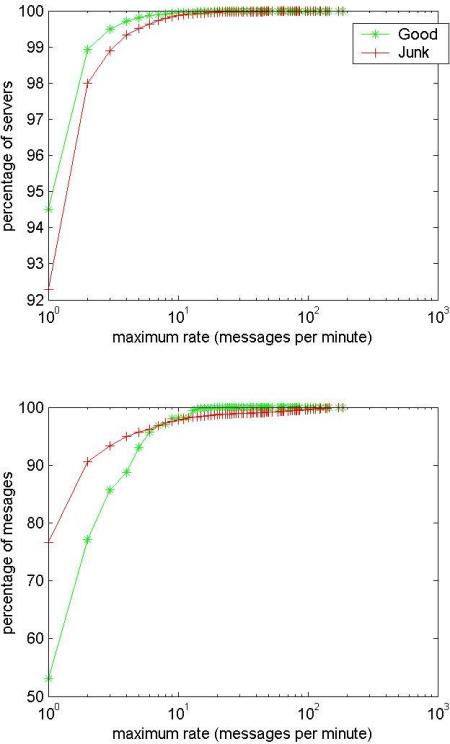
These results suggest that the rate of incoming junk messages from each server is low (it has to be low if they send few messages--10% of junk mail comes from servers that send only one message, for which a rate limit is meaningless). Measurements of local frequency (number of mails per minute) show that some junk mail is sent at high rates, but this is a tiny proportion of the total mail (see Figure 2). There is very little difference between the rates of good and junk senders for the bulk of messages.
|
This result is perhaps surprising and counter-intuitive, particularly as many of the delaying responses are geared toward reducing rates. This data suggests that, with the possible exception of dictionary attacks (which we did not notice in our data), rate-limiting mechanisms are not particularly effective against junk mail.
The explanation for the shapes of Figures 1 and 2 is a combination of two factors. Firstly, spammers are forced to change their server addresses frequently as addresses are placed on blacklists, so the volume of mail from each spamming server is limited. Secondly, each mail server only sees a sample of the total spam mail sent by any spammer, corresponding to the number of messages on the spammer's mailing list that are handled by the server. This further reduces the number of messages that are received from each server, and reduces the rate. For servers that handle mail for large domains (e.g. Yahoo) this second factor will be less significant.
Even for good mail, a significant proportion comes from servers that send few messages. This has a bearing on the effectiveness of Greylisting (12), a technique that keeps a record of the triple {sender IP address, sender email address, recipient email address} and only allows mail through without delay if that triple has been observed before. Table 5 shows an evaluation of Greylisting. These results are for 36 days' worth of data, the standard lifetime of a triple. The maximum number of triples is enormous, but the actual number required to be stored is likely to be a lot lower--Greylisting only keeps a triple for 36 days if a mail with that triple is accepted. Greylisting is very effective against junk mail, with 98% being delayed. On the other hand, the percentage of good mail that is delayed is rather large (40-51%).
| type | number | % |
| server1 | ||
| triples | 619,536 | |
| good delayed | 84,748 | 51% of good |
| junk delayed | 444,829 | 98% of junk |
| server2 | ||
| triples | 557,314 | |
| good delayed | 69,227 | 40% of good |
| junk delayed | 376,532 | 98% of junk |
However, the fundamental idea behind Greylisting--that unusual mail is likely to be junk--is a good one, and we explore this further in the following section.
This section develops the idea of using the past history of types of mail sent (good/junk) in order to predict the type of the next message from a server before that mail is accepted. This enables new and interesting responses both pre- and post-acceptance.
The data in the previous section (particularly Table 4) shows that mail servers can be classified based on the mail that they have sent, into those that send junk mails, good mails, and a mixture. This suggests that looking at history might be a good way to predict behavior.
One simple way to represent history is to calculate the proportion of good messages received by the server, where a good message is one that is not classed as spam or virus, and one where more than half of the recipients are delivered on the first delivery attempt. The proportion of good mail Pi can be calculated as
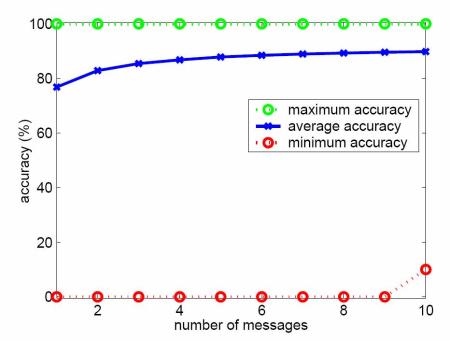
where i is the server indexed by IP address, and Ngood and Ntotal are the number of good and total messages received from server i. When the first message is received there is no data to calculate Pi, so it is initialized to zero. As messages are scanned and delivery attempts are made, the values of Ngood and Ntotal are updated. Pi can be used to predict whether a server is likely to send good or junk mail using a simple threshold r, i.e. if Pi > r the message is predicted to be good and vice versa. As more messages are received, this prediction becomes more accurate (see Figure 3).
|
Table 6 shows the overall accuracy of this method when r = 0.5. It shows that it is important to include all forms of junk mail in order to get an accurate classification; just basing the calculation on spam alone does not give such accurate results. This is most likely due to the fact that combining spam detection and undeliverable mail combines two noisy indicators of spam to give greater accuracy: a proportion of spam evades the spam filter, and many of the addresses on spam mailing lists are incorrect.
Table 6 shows that this measure is remarkably accurate at detecting junk mail (93-95% accuracy), and also good at detecting good mail (74-80%). Some of the errors are unavoidable, as the first mail from every sending server will be predicted to be junk. Although most of the mail sent by new servers is indeed junk, this results in a small number of good messages being misclassified. Out of 855,228 messages on server1, 226,585 (26%) were the first message from a new server, and of those 33,021 (15%) were good. The other cases where good messages are classed as junk appear from a cursory look to mostly be spam that has evaded the content scanner (for example they have implausible sender email addresses). Thus the errors may be fewer than measured.
The other type of error, where junk messages are classed as good, occurs for an even smaller group. It is probably caused by mistyped addresses, cases where the spam detector over-zealously marks a legitimate mail as spam, or where a sender that has previously sent good mail gets infected by a virus.
| good | junk | |||
| number | % | number | % | |
| server1 | ||||
| spam | 242,163 | 68 | 462,516 | 93 |
| virus | 239,990 | 67 | 464,709 | 93 |
| undeliverable | 192,428 | 74 | 565,922 | 95 |
| server2 | ||||
| spam | 250,496 | 73 | 377,212 | 91 |
| virus | 248,516 | 73 | 379,112 | 91 |
| undeliverable | 209,309 | 80 | 459,432 | 93 |
Figure 4 shows that the prediction accuracy is insensitive to the value of the threshold r. Varying r in the range 0.1-0.8 gives around 10% variation in the individual accuracies, and virtually no variation in overall accuracy.
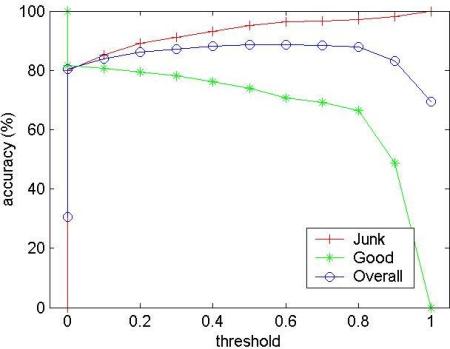
|
The results in Table 6 used the entire 69-day dataset to calculate Pi, however the probability is still remarkably accurate even if only a small part of the history is maintained. Figure 3 shows how even with a very short history of a few messages, the probability measure performs well. This is important as it will allow the quick capture of changes in server behavior, for example if a previously good server starts sending mail infected by a virus.
In addition, good performance can be achieved without maintaining a record for every sending server. Figure 5 shows the effect on accuracy of maintaining a fixed number of IP records, using a first-in-first-out replacement policy. The total number of unique senders observed is indicated by the vertical line. It is only when the number of addresses stored is around a quarter of the total that the performance starts to fall off.
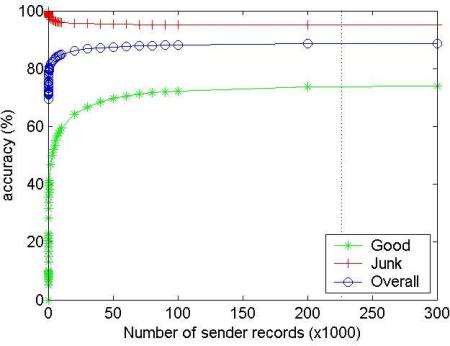
|
To summarize, this prediction method is practical to calculate on a real mail server. It requires some state ( Ngood, Ntotal) to be maintained for each server, but that state is either a pair of numbers, or a short (< 10) history of message types. In addition, state can be maintained for a relatively small proportion of the sending servers without sacrificing performance. The amount of state required is far smaller than that required for techniques like Greylisting. The state can also be updated asynchronously as it becomes available. In a real implementation this information will be delayed, however this is unlikely to affect the accuracy of the results significantly (it will only affect updates during overloading).
This method of predicting good and junk mail is particularly powerful because it can be calculated before the message is received. It thus enables both pre- and post-acceptance responses.
The rate of false positives is too high to use Pi for blocking mail (in fact if it were used no mail would ever be delivered, because the first mail from every server would be rejected!). It can, however, be used with tempfailing. As mentioned above, the advantage of tempfailing is that it effectively blocks mail if spammers do not retry, and increases the efficiency of blacklists if they do. An example of an appropriate use of tempfailing with the sending history measure is to not accept any mail from a new server for a short period of time (e.g. 4 hours), and from predicted junk-sending servers for a longer period (e.g. 12 hours). This technique would help combat email storms caused by mass mailing viruses: when a previously good machine starts sending the virus, its value of Pi will decrease and eventually its traffic will be tempfailed, so reducing the load on the server. There are, however, other more direct mechanisms to deal with email storms, e.g. (36). Finally, tempfailing could also be used when the server is heavily loaded, preferentially tempfailing junk mail.
The history measure also enables an exciting post-acceptance response, that of prioritizing good mail through the bottlenecks in the server (often the virus/spam scanner). Instead of all mail being treated equally, good mail can be placed in a high priority queue for the scanner and SMTP processes. The good mail is still scanned, but will travel through the server with minimal delay, even when the server is very heavily loaded by spam or virus attack (both of which are increasingly common).
This section provides some evidence for how much effect the responses described above would have on reducing the amount of spam processed, and on reducing the effect of the volume of junk mail on the flow of good mail through a mail server.
Firstly, we consider the effect of tempfailing new servers and servers predicted to send junk. Unfortunately it is very difficult to test this just using log data, as the response is to request the remote sending server to retry later, and it is difficult to predict the behavior of the sending server.
A best-case estimate would be to assume that spammers and virus-infected machines do not retry, but that good senders do. Thus out of 855,228 messages accepted by server 1, if a 4 hour delay was used for new senders and a 12 hour delay for predicted junk mail, the effect would be as in Table 7. Only 26% of good mail would be delayed, and as discussed above, a significant proportion of this mail is likely to be misclassified junk. If this sort of system were widely deployed, it is likely that spammers would implement retries. This would cause the amount of junk mail rejected to decline considerably.
It is much easier to predict the effect of post-acceptance responses. We do this by constructing a model of a mail server that allows us to calculate the time taken to process a mail message, under different amounts of loading. We can then alter that model to incorporate prioritization schemes and predict the final performance of the system.
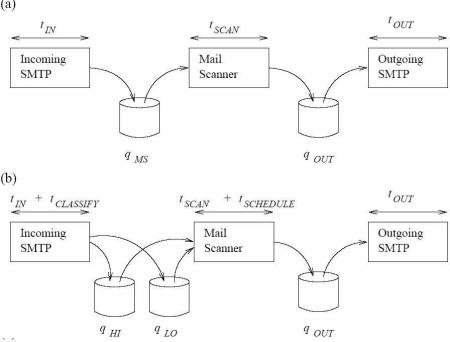
The initial model of the system is shown in Figure 6 (a). This is a generic model of a mail server that includes a mail scanner or filter. The incoming mail is handled by an SMTP process that writes the mail to a local disk or spool qMS, taking time tIN. The mail is then loaded, scanned and placed in a second spool qOUT by the mail scanner, marking the mail accordingly (normally by writing a header), and taking on average tSCAN. The mail is then taken from this second spool and delivered by the outgoing SMTP process, taking tOUT. The overall time will be tIN + tSCAN + tOUT plus the time that mails spend on the queues waiting to be processed. As each of the spools is effectively a queue, this system can be analyzed using Queueing Theory (10).
|
Prioritization can be implemented by having two queues for the mail scanner, one for high priority or good mail (qHI) and the other for low priority or junk mail (qLO). When a mail arrives it is classified into good or junk (this extra processing taking tCLASSIFY), and placed into one of these queues. The mail scanner then uses a simple scheduling algorithm to select which message to process next. The simplest algorithm is ``absolute priority'', where the scanner always takes from the high priority queue unless it is empty, when it services the low priority queue (19). The scheduling operation is modelled as taking tSCHEDULE. As before, the total time is the sum of the individual times plus the time spent queuing.
We simulated both models using the DEMOS system performance modelling tool (4). This allows synthetic traffic to be ``played'' through the model and the system performance evaluated. The parameters of the model (the various service times tIN, tSCAN, tOUT) were estimated from the log data. These parameters are difficult to estimate, because the times in the logs include messages being queued as well as processed. To deal with this we took a lower bound on the actual measurements, assuming that the fastest times corresponded to small or no queues. In addition, we used a facility within DEMOS to specify a probability distribution of parameters rather than a fixed value. The most important parameter is the time to scan a message. This turned out (somewhat surprisingly) not to be particularly sensitive to message size, and was modelled as an exponential distribution. All the other aspects of the model were taken from the log data: the rate and ratio of good/junk were taken from incoming message rates with different rates for day and night; and the traffic was assigned to different priority queues using the probabilities in Table 6, i.e. a good message had an 74% chance of being placed in the high priority queue.
It is important with any model to calibrate it accurately, so that it is possible to believe its predictions. Figure 7 shows the distribution of delays for server1 together with the delays predicted by the model, with parameters as given in the caption. The figure shows that the model fits the data reasonably well.
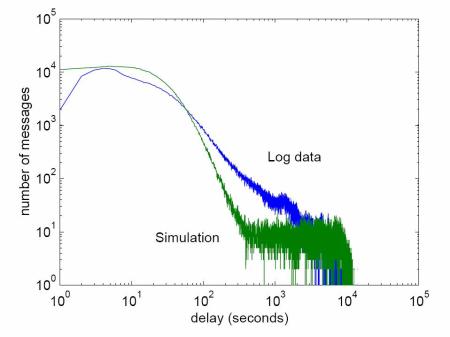
|
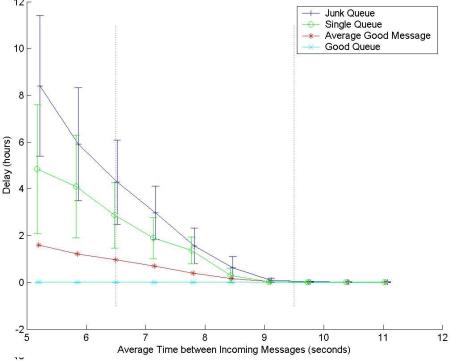
Having calibrated the model, the effect of the prioritization can be tested. Figure 8 shows the effect of the same parameters applied to the model in Figure 6. The extra processing times tCLASSIFY and tSCHEDULE were assumed to be small compared to the scan time tSCAN, and were neglected. The plot shows the average delay against the rate of incoming traffic. For low traffic loads the delays are small, because the server is lightly loaded. As the load increases, the delays increase sharply if no prioritization is used. If prioritization is used, the good mail continues to be processed with small delays, but the junk mail is heavily delayed. These traffic loads are common in practice: marked on the diagram are normal loads and loads sampled during the SoBig.F virus attack (31). For example, during the virus attack, using a conventional arrangement, the mail was delayed by 2.7 hours. With the prioritization scheme, good mail placed in the high priority queue is delayed by only 22 seconds on average, with junk mail delayed by over 4 hours.
|
|
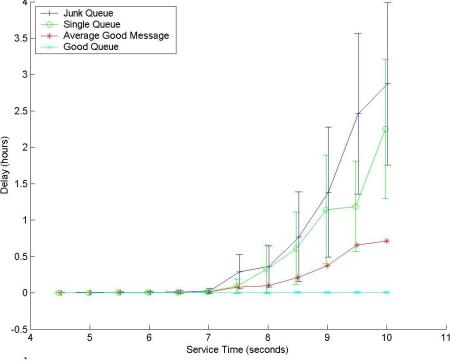
Different mail servers have different performance capabilities (different hardware/software configurations), which affect their ability to process mail. Figure 9 shows the behavior of the system with a constant traffic load but varying server performance. When the server is over-provisioned the delays are small, but for an under-powered server good mail is still passed with very small delays. This means that mail servers can be sized based on expected normal mail loading, and that their performance will be less sensitive to the amount of junk mail processed. This is a great benefit given the volumes of spam and virus mail that is processed now, let alone the volumes being predicted (18).
Of course, some good mail is wrongly classified as junk, and will have delays similar to the junk mail. However, this delay is only slightly worse than that experienced in the original system for all mail, only a small proportion of mail is affected, and some of that mail should have been classified as spam anyway. In any case it should only be the first legitimate mail from any server that will be heavily delayed.
There are different scheduling schemes that can be used, for example absolute priority, fair share or weighted fair share (7). We modelled several, but found that the choice of scheduling scheme has little effect on the delivery of good mail: the main effect is on the length of delays to junk mail, with absolute priority giving the longest delays.
To summarize, adding prioritization is extremely effective at ensuring that the bulk of good email is delivered promptly, even when the mail server is very heavily burdened by junk mail.
|
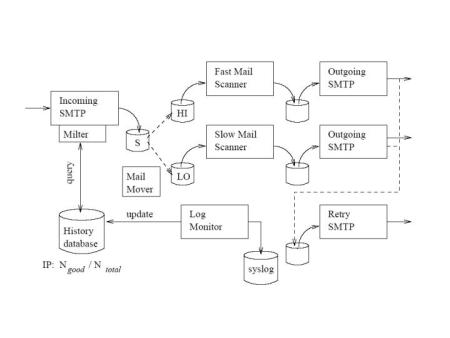
Figure 10 shows a sketch of how these schemes could be implemented on an industrial strength mail server. Sendmail (23,24) and MailScanner (33) are used as examples, but the approach can be generalized to other products.
The basic idea is to mark messages as good or junk in the incoming sendmail process, and dump them in the usual spool directory. The messages are then moved into two queues, which are serviced by two copies of the mail scanner.
When mail is received by the incoming sendmail process, it can be intercepted using the Milter interface (39). This interface allows access to the mail message and header information, and also allows certain actions like tempfailing or blocking, as well as writing headers and changing the message body. The specific milter code for this system would grab the IP address of the sending server, and query the history database to determine the probability that the message was good or junk. The milter would then implement the action required: either to tempfail the request (writing to the database the time when messages from that server would next be accepted), or marking the message as good or junk, for example by writing an extra header into the mail message. If the message is accepted, it is written into the usual mail spool S.
The ``MailMover'' component runs regularly, scanning messages in the spool to determine whether they are good or junk, and moving them into the two queues HI and LO respectively. Sendmail simply writes the messages into the spool, so it is safe to move the files. (Other servers, e.g. postfix (35) and qmail (3), rely on more complex file information; for these a more sophisticated system would be needed.) Two copies of the MailScanner then process the two queues. These programs would be configured so that the one servicing the high priority queue ran faster than the other.
MailScanner automatically triggers the outgoing SMTP process when it has processed a (configurable) number of messages. Any that are undeliverable are saved in a separate queue, and another sendmail process handles retries. It would be possible to implement prioritization for this process too, using another MailMover and two retry sendmail processes.
Once the scanner has processed the message, information about the message is available to update the history of the sending server. In addition, once the outgoing sendmail process has attempted to deliver the message, information about undeliverable messages is also available. Since this information is written into the normal syslog, a process that monitors the logs (``LogMonitor'' in Figure 10) can recover this information and update the history in the database. It does this by keeping track of message identifiers, and matching the results of the scan/attempted delivery with the IP address of the original sending server.
The database is shown here on a single system; however there is no reason why the information stored should not be shared by many servers. Sharing information is likely to further improve the accuracy of the classification.
The system described above was implemented on a linux machine (1.6GHz RedHat 9.1, Sendmail 8.12.11, MailScanner 4.26.28, MySQL 3.23.58). The Milter, MailMover and LogMonitor were all implemented as separate perl processes.
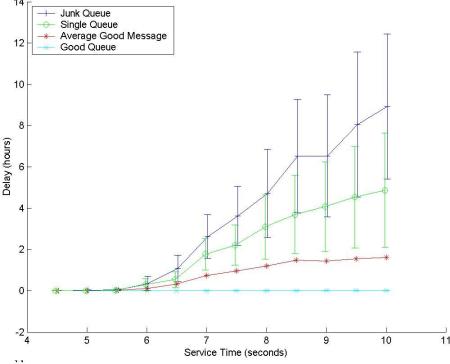
For testing purposes two otherwise identical machines were used, one configured to use the prioritization scheme, and another configured to use a single MailScanner. Figure 11 shows the results of sending the same high load of messages to both machines. The figure clearly shows low delays for good messages even when the load is large.
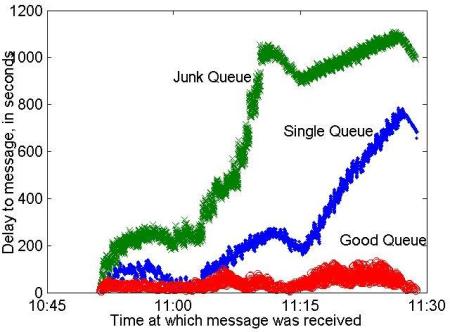
|
This paper has considered the problem of unacceptable delays in sending email due to servers clogged with unwanted email messages--viruses, spam and undeliverable mail. This is a problem that is significant now, and is likely to become more significant as the volumes of spam and virus-carrying email increase.
We have shown, with reference to empirical data, that existing mechanisms to deal with spam (blacklists, rate limiting, greylisting, content filtering) are only partially effective. So, we have developed a system to preserve performance while coping with large volumes of junk mail.
We have shown that a simple prediction of the type (good/junk) of the next message received by a server can be used to delay acceptance of junk mail, and to prioritize good mail through the bottlenecks of the server. The prioritization scheme ensures that most of the good mail is transmitted with small delays, at the expense of longer delays for junk mail. This scheme greatly improves on the performance of current non-prioritized schemes.
We have also argued that this approach is practical, and sketched an implementation on an industry standard mail server that requires no modifications to existing code. Initial tests of this implementation suggest that it works well in practice.
Not all spam classification occurs at the server, and the spam classification at the desktop is often more customizable and accurate. It would be useful to be able to feed this information back to the server. The challenge would be how to achieve this in a practical and secure way. One possible technique would be to write the originating server's IP address in the mail header and allow client software to ``update'' the mail server with more accurate spam classifications.
In conclusion, while this approach does not stop junk mail, it should increase the resilience of the mail system, making it better able to cope with overloading from spam and from virus attacks.
The authors would like to thank John Hawkes-Reed and Andris Kalnozols for help with data collection and developing the implementation.
This document was generated using the LaTeX2HTML translator Version 2002 (1.62)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -no_navigation -split 0 -no_math -html_version 3.2,math final
The translation was initiated by Matt Williamson on 2004-04-26
|
This paper was originally published in the
Proceedings of the 2004 USENIX Annual Technical Conference,
June 27-July 2, 2004, Boston, MA, USA Last changed: 10 June 2004 aw |
|