
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
USENIX '04 Paper
[USENIX '04 Technical Program]
Migrating an MVS Mainframe Application to a PC
Glenn S. Fowler, Andrew G. Hume, David G. Korn and Kiem-Phong Vo
|
| Language | #Files | #LOCs |
| COBOL | 30 | 15K |
| JCL | 900 | 100K |
Table 1 summarizes the size of the application. COBOL is the main programming language used on mainframes. JCL is the Job Control Language used to write scripts to execute processes similarly to the shell language [13] on a Unix system. We note that the chosen application is just a small part of the entire biller which is more than 1.5M COBOL LOCs.
|
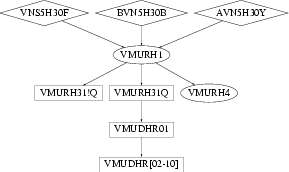
Figure 1 shows the data processing for this application. The names of the components are as defined by the overall biller. The workflow among the components is as follows:
The internal working of the above software components are opaque to us. However, understanding them is not necessary in a tool approach to migration. We only need to ensure that the processes can be compiled and executed or interpreted on the PC's to produce the same data as on the mainframe.
Our AST Toolkit consists of an extensive collection of tools portable across nearly all flavors of Unix. In fact, these tools run transparently on both the PC and the UNIX System Services [1] part of MVS. However, there are major differences between mainframe MVS and PC UNIX that necessitate a number of new tools and techniques:
There are number of issues in moving data between MVS and PC. We discuss each below:
COBOL source files, however, are not stored in a partitioned data sets. Instead, they were stored in a sequential data set in a format understood by an MVS tool named ca-librarian [3]. As the interface to ca-librarian is interactive and menu-based, it is difficult to extract and copy multiple files in bulk. We reengineered this data format and built it into our AST pax command. This allows us to simply copy the ca-librarian sequential data set and read it on the PC using pax.
With about 15 KLOCs of COBOL to be migrated, even if we were proficient in COBOL (and we were not), it would have taken a significant amount of time to rewrite the application in C. Thus, we looked into obtaining a COBOL compiler for PCs. After failing to get proper licensing terms for a commercial COBOL compiler, we started experimenting with openCOBOL, an Open Source COBOL compiler written by Keisuke Nishida [16]. Although this compiler did provide most needed features, there were a number of changes needed to support a large application like ours. We discuss these next:
The IBM compiler allowed specifications such as ASSIGN TO DA-S-VMUR102B without quoting whereas the openCOBOL one required that the dataset name be quoted. We modified the compiler to accept this syntax and to skip over the DA-S- prefix and then use the VMUR102B as the name of an environment variable to search for to find the actual file name.
With JCL, multiple files can be specified for each dataset. In that case, the files are virtually concatenated into a single input data stream. We modified the openCOBOL compiler to accept a space separated list of file names as the value of an environment variable and open them sequentially as if they formed a single concatenated file.
The generation of the main program was modified so that a USING clause would get the data from the first argument passed to the program.
We were able to work with Nishida to add all of the needed language features as well as other modifications into the openCOBOL compiler. In this way, future projects migrating COBOL programs can build on our work.
Finally, the compiler converts each COBOL module to C and then invokes the GNU C compiler, gcc, to build an object file. The object files are then linked with a runtime library supporting various COBOL features to make an executable program. We wrote nmake makefiles [8] to automate this process. However, given the large number of makefiles that must be written in a large application, we are investigating automatically generating them.
The MVS sort program has a number of features beyond normal sorting. For example as records are read, files can be created by selecting certain subset of the fields to create new records. Records comparing equal by keys may also be merged by summing certain field values. The description of what keys to sort on, how to do merging, and what additional files to create is defined in a separate specification called sort control cards. These features of MVS sort were used extensively in our chosen application.
The AST sort program is a superset of the UNIX sort utility defined in the POSIX standard. A feature of the AST sort not apparent at the command level is that it is just a driver on top of a sorting library designed in the Disciplines and Methods paradigm [20]. This paradigm provides a standard API via the discipline mechanism to extend library functionality. We were able to duplicate the required functionality of MVS sort by writing a few disciplines that make use of MVS sort control cards to process a record when it is read or to merge records compared equal in the same way that MVS sort does it. The sort disciplines are implemented as shared library plugins. This means that discipline-specific overhead is only incurred after the plugin is loaded at runtime.
For full MVS compatibility, we extended AST sort to deal with fixed length records and binary coded decimal fields. Similar to modifications to the COBOL compiler, the sort program could also handle concatenation of files and data compression with the .qz suffix.
On MVS, our sort runs about 5% faster than MVS sort. However, the two sort programs occasionally produces records in different order since ours is stable while MVS sort is not. That is, our sort preserves file order for records that compare equal by keys while MVS sort does not provide this guarantee.
JCL, the job control language for MVS, plays much the same role as the UNIX shell does in that it invokes programs or scripts in some order and takes actions based on the results. The chosen application executes over 100 thousand lines of JCL about 90% of which are generated and the remaining 10% are fixed. A JCL script is generated for each customer by accessing the DB2 database. These scripts merely call MVS sort with various control card decks generated from within the scripts. To eliminate these JCL scripts would require access to the database from UNIX. To avoid this complexity, we kept the generation of these scripts on MVS and then processed them on UNIX.
We wrote jcl, a JCL interpreter, that allows the use of the hierarchical Unix file system instead of the flat MVS file names via file name prefix mapping. For example, a partitioned data set for control cards, say SYS1.CTLCDLIB, would be mapped to the directory ${BILLROOT}/cntlcard so that its control cards would be stored in separate files in this directory. jcl first parses JCL scripts into a linked list of program step structures. This list is traversed to either generate ksh shell scripts or to execute. jcl also provides debugging support that can be used to determine the overall structure and relationships between a collection of JCL scripts. For example, the -noexec option interprets the JCL but does not execute external programs and the -list=item option lists the items referenced by each JCL step.
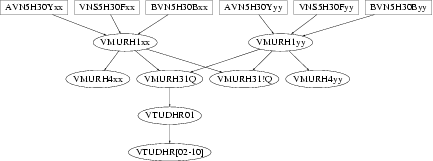
An application on MVS consists of a number of jobs some of which can run in parallel while others must wait until some other set of jobs finish before they can start. Let A and B be two jobs. We say that there is a directed edge A � B if there is a constraint that A must be completed before B can start. In this way, the set of jobs and constraints form a directed graph called the scheduling graph.
|
Figure 2 shows a slice of the scheduling graph for our application based on the processing of just two customers xx and yy. This essentially executes the workflow presented in Figure 1 except that all customers are now being considered together so there are more opportunities for parallelization. For example, as soon as the data produced by the external systems AVN5H30Y, VNS5H30F and BVN5H30B for a particular customer are available, the VMURH1 process for that customer can be started. As long as there are enough processing power, the scheduler starts many such processes in parallel. The results from these processes are further processed. In particular, the merged results by VMURH31Q are passed on to the VTUDHR processes.
By necessity, a scheduling graph must be acyclic so that the jobs can be scheduled. In general, jobs may have attributes associated with them such as completion time or memory and disk resource constraints. In that case, it is desirable to compute a schedule that optimizes some parameters based on these attributes. When only a single processor is available, any topological sort ordering of the jobs produces a valid optimal schedule. However, on a system with multiple processors, the scheduling problem is known to be NP-hard[11].
The MVS scheduler, New-Dimension, allows scheduling constraints to be specified by filling out form tables. Then, the scheduler controls resources of the system and sequences the jobs appropriately. For the PC's, we opted to write a simple scheduler, which reads lines from one or more queues specified as files, and runs a command for each line it reads. At startup, the scheduler is given a list of process resources and will run a single job at a time through each resource. If all resources are in use, the scheduler blocks until one becomes available. If all the file queues are empty, the scheduler will block until one of the file queues contains some input to process.
The simple scheduler is adequate for our prototype. However, in general, MVS scheduling has many facets that we did not account for. We are investigating writing a tool to read the MVS scheduling tables and perform the appropriate scheduling on the PC's.
We wanted to select a platform of hardware and software fast enough to do the processing, able to store the data, able to run all of the software, and at as low cost as possible. Based on price performance considerations, we built a cluster of two machines, each with a 2.8 MHz. Intel Pentium 4 processor, 1 gigabyte of 400 MHZ DDR RAM, and two 256 gigabyte SATA disk drives. The machines are networked with Gigabit Ethernet. Unit testing various CPU intensive programs showed that these machines were about 7 times as fast as the MVS systems. The SATA disk drives were able to tranfer about 100 megabytes a second. The entire cost for both machines was under $4,000.
Since most of the processing was per customer and could be done in parallel, we kept the machines loosely coupled with separate file systems instead of using a single shared file system. As data processing was intensive, avoiding the overhead of a shared file system such as NFS was a win overall. In data processing phases where files must be merged, they could be copied to wherever needed. Keeping a loosely coupled cluster of machines made it simple to disconnect a bad machine or to add new machines as needed. This increased fault-tolerance and scalability.
The choice of an operating system was constrained by the software to be run. The use of the AST Toolkit did not constrain this choice in any way. However, the openCOBOL compiler required the GNU-C compiler gcc and certain GNU libraries. We finally chose Redhat Linux 9.0 primarily because we felt it would be easier to integrate our solution into the billing application supported by IBM. Our concerns with Redhat Linux were primarily its erratic I/O performance. For example, the throughput was actually higher by running a single customer at a time on each system rather than running multiple customers in parallel. However, we were not locked into any operating system. We experimented running the software with FreeBSD Unix. In contrast to Linux, the throughput did increase when running two customers in parallel on FreeBSD Unix. Finally, a UNIX based solution was chosen rather than Windows mostly for reliability consideration. However, all the tools could be run on Windows using the UWIN software [14].
| Data | #Files | Raw | Comp. |
| From mainframe | 300 | 560GB | 22GB |
| Generated on PC | 1160 | 280GB | 17GB |
For testing, we processed data for the October 10, 2003 cycle. Table 2 summarizes the data that were transferred from the mainframe and generated on the PC's. Theoretically, the data could be compressed on the mainframe in about 12.5 hours and transferred to the PC's in about 6 hours for a total of 18.5 hours. However, it took us over 24 hours to move the data from the mainframe to the PC's, mostly due to long waiting time for mainframe tape drives. Once the data arrived on the PC's, processing completed in under 19 hours. Thus, even with the slow data transferring time, the output data was generated in about 43 hours. The same job took a total of 60 hour processing time on the mainframe. Note that, in this case, we waited until all files were copied to the PC's before processing. Our scheduler could be modified to allow overlapping of data transferring and data processing to reduce elapse time even further. In addition, our set up could be easily scaled up by adding more PC's. We estimated that with a 4 processor system, we could process this data in under 12 hours.
CPU cycles on the mainframe costs about $20/hour and network charge for data transmission to and from mainframe is around $5/Gbyte. Thus, if the above data is representative of the 10th cycle, it could be compressed and transferred between the mainframe and PC's for less than $1000. Generously doubling this to cover both the 10th and the end of the month cycles, the total cost for data transfer each month would be less than $2000. Assuming that the PC's cost $2000/month to own and operate, the total cost for migrating to the PC's would be under $4000/month. As the current cost to run the application on the MVS mainframe is estimated to be about $20000/month, the data processing cost can be reduced by more than a factor of 5 for this application using our approach.
We presented a methodology to migrate mainframe applications to PC's based on software tools. This approach minimized software and data reengineering and enabled smooth transition between the mainframe and the PC's. The work took place over a six month period and was carried out by a small team of software experts without prior MVS or COBOL skills. Much of the effort was spent in learning MVS, COBOL, and in writing reusable tools. Thus, the work could be easily duplicated on more ambitious problems with far bigger payoffs.
In an experiment using the developed tools to move a small but significant mainframe application to a system of two PC's costing less than $4000, we showed that over 80% of the monthly computing cost could be reduced, saving more than $16000 per month. This cost improvement was conservative. Most of the cost was driven by moving data from the mainframe to the PC's and that could be easily eliminated by getting the data directly to the PC's. The migration of the entire billing application to PC's might save up to 90% of the ongoing costs.
Beyond software migration, the work on compression and sorting were of a general nature. For example, the table compressor could be used to compress any database tables using fixed length records. It was shown elsewhere [19] that mainframe data of the type mentioned here could be compressed by factors anywhere between 50 to 100 to 1. Thus, the compression tool could be used to save disk space and tape usage on the mainframe. Our sort tool employs better sorting algorithms than MVS sort and the commercial Syncsort (http://www.syncsort.com/) software used in original project. Thus, it can be used to both improve processing and save the rather steep licensing fees being paid yearly.
Looking forward, there are a number of threads to be developed. For example, our test case does not involve database and report generation issues which are important in large applications. The questions of reliability, effective scheduling of processes, and optimal partitioning and placement of large data on a cluster of loosely coupled PC's are of independent interest. Such problems should be dealt with in conjunction with migrating a larger and more comprehensive application. We are looking into that.
1http://www.nytimes.com/2003/12/11/business/11irs.html
|
This paper was originally published in the
Proceedings of the 2004 USENIX Annual Technical Conference,
June 27-July 2, 2004, Boston, MA, USA Last changed: 10 June 2004 aw |
|
{kind=link}
{kind=link}