
Tarem Ahmed, Boris Oreshkin and Mark Coates
Department of Electrical and Computer Engineering
McGill University
Montreal, QC, Canada
A network anomaly is a sudden and short-lived deviation from the normal operation of the network. Some anomalies are deliberately caused by intruders with malicious intent such as a denial-of-service attack in an IP network, while others may be purely an accident such as an overpass falling in a busy road network. Quick detection is needed to initiate a timely response, such as deploying an ambulance after a road accident, or raising an alarm if a surveillance network detects an intruder.
Network monitoring devices collect data at high rates. Designing an effective anomaly detection system consequently involves extracting relevant information from a voluminous amount of noisy, high-dimensional data. It is also important to design distributed algorithms as networks operate under bandwidth and power constraints and communication costs must be minimised.
Different anomalies exhibit themselves in network statistics in different manners, so developing general models of normal network behaviour and of anomalies is difficult. Model-based algorithms are also not portable across applications, and even subtle changes in the nature of network traffic or the monitored physical phenomena can render the model inappropriate. Non-parametric, learning algorithms based on machine learning principles are therefore desirable as they can learn the nature of normal measurements and autonomously adapt to variations in the structure of ``normality''.
Most methods of network anomaly detection are based on network traffic models. Brutlag uses as an extension of the Holt-Winters forecasting algorithm, which supports incremental model updating via exponential smoothing [1]. Hajji uses a Gaussian mixture model, and develops an algorithm based on a stochastic approximation of the Expectation-Maximization (EM) algorithm to obtain estimates of the model parameters [2]. Yamanishi et al. also assume a hierarchical structure of Gaussian mixtures in developing the ``SmartSifter'' tool, but uses different algorithms for updating the model parameters [3]. They use a variant of the Laplace law in the discrete domain, and a modified version of the incremental EM algorithm in the continuous domain. They test their algorithm to detect network intrusion on the standard ACM KDD Cup 1999 dataset. Lakhina et al. apply Principal Component Analysis (PCA) to separate IP network data into disjoint ``normal'' and ``anomalous'' subspaces, and signal an anomaly when the magnitude of the projection onto the anomalous subspace exceeds a threshold [4,5,6]. Huang et al. build on Lakhina's centralised PCA method of anomaly detection from [6], and develop a framework where local PCA analysis and stochastic matrix perturbation theory is used to develop an adaptive, distributed protocol [7].
Researchers have recently begun to use machine learning techniques to detect outliers in datasets from a variety of fields. Gardener et al. use a One-Class Support Vector Machine (OCSVM) to detect anomalies in EEG data from epilepsy patients [8]. Barbará et al. have proposed an algorithm to detect outliers in noisy datasets where no information is available regarding ground truth, based on a Transductive Confidence Machine (TCM) [9]. Transduction is an alternative to induction, in that instead of using all the data points to induce a model, one is able to use a small subset of them to estimate unknown properties of test points. Ma and Perkins present an algorithm using support vector regression to perform online anomaly detection on timeseries data in [10]. Ihler et al. present an adaptive anomaly detection algorithm that is based on a Markov-modulated Poisson process model, and use Markov Chain Monte Carlo methods in a Bayesian approach to learn the model parameters [11].
An example of a machine learning approach to network anomaly detection is the time-based inductive learning machine (TIM) of Teng et al. [12]. Their algorithm constructs a set of rules based upon usage patterns. An anomaly is signalled when the premise of a rule occurs but the conclusion does not follow. Singliar and Hauskrecht use a support vector machine to detect anomalies in road traffic [13]. They use statistics collected by a sophisticated network of sensors including microwave loops and lasers, and design a detector for road traffic incidents.
Our objective in this paper is to show the applicability and need for learning algorithms in detecting anomalous behaviour in a distributed set of network measurements. From the wide variety of machine learning techniques available, we choose the One Class Neighbor Machine (OCNM) proposed by Muñoz and Moguerza in [14], and the recursive Kernel-based Online Anomaly Detection (KOAD) algorithm that we developed in [15]. We present our case via two examples: sequences of images from Transports Quebec's camera network, and IP timeseries data from the Abilene backbone network. We demonstrate that both algorithms are effective in detecting anomalies and motivate the development of more advanced, fully adaptive and fully distributed, learning algorithms.
The rest of this paper is organized as follows. Section II defines the problem we address. Section III describes the Transports Quebec and Abilene datasets and Section IV reviews the OCNM and KOAD algorithms. Section V presents our results and Section VI summarises our conclusions and discusses the need for distributed, learning algorithms for network anomaly detection.
The anomaly detection problem can be formulated as follows. A
continuous stream of data points
![]() constitutes
a collection of measurements
constitutes
a collection of measurements
![]() governed by a
probability distribution
governed by a
probability distribution ![]() . Although measurements correspond to
certain physical events in the event space
. Although measurements correspond to
certain physical events in the event space
![]() , the
mapping
, the
mapping
![]() between them
may not be known. We assume that
between them
may not be known. We assume that
![]() can be divided
into two subspaces corresponding to normal and anomalous physical
conditions. In many practical situations it is of interest to infer
the membership of an event in a particular subspace using the
corresponding measurement. As the probability distribution
can be divided
into two subspaces corresponding to normal and anomalous physical
conditions. In many practical situations it is of interest to infer
the membership of an event in a particular subspace using the
corresponding measurement. As the probability distribution ![]() governing measurements is unknown, some mechanism should facilitate
learning its volumetric representation from the collection
governing measurements is unknown, some mechanism should facilitate
learning its volumetric representation from the collection
![]() . A general approach to the aforementioned
problem of learning such a representation consists of constructing a
Minimum Volume Set (MVS) with probability mass
. A general approach to the aforementioned
problem of learning such a representation consists of constructing a
Minimum Volume Set (MVS) with probability mass
![]() with respect to distribution
with respect to distribution ![]() for a volume measure
for a volume measure ![]() [16]:
[16]:
Real multidimensional data exhibit distributions which are highly
sparse. Moreover, distributions of raw data may lack invariance with
respect to generating events. That is, physical events pertaining
to the same region in
![]() may generate measurements in
completely different regions of
may generate measurements in
completely different regions of
![]() . Therefore, it is
often desirable to reduce the dimensionality of raw data via some
feature extraction mechanism
. Therefore, it is
often desirable to reduce the dimensionality of raw data via some
feature extraction mechanism
![]() where
where ![]() , that is robust to sparsity and
variance induced by the transition
, that is robust to sparsity and
variance induced by the transition
![]() . We then construct a minimum volume set from the
features and not from the raw data.
. We then construct a minimum volume set from the
features and not from the raw data.
We use two different datasets to advocate the applicability of machine learning algorithms to network anomaly detection.
Transports Quebec maintains a set of webcams over its major roads
[18]. These cameras record still images every five minutes.
We collected images recorded by ![]() cameras over a period of four
days (Sep. 30 to Oct. 03, 2006) on Quebec's Autoroute 20. Each
5-minute interval constitutes a timestep.
cameras over a period of four
days (Sep. 30 to Oct. 03, 2006) on Quebec's Autoroute 20. Each
5-minute interval constitutes a timestep.
Anomaly detection in a sequence of images relies mainly on the extraction of appropriate information from the sequence. There are two fundamental reasons for this. First, the large dimensionality inherent to image processing leads to dramatic increase in implementation costs. Second, large variation in operating conditions such as brightness and contrast (which are subject to the time of day and weather conditions) and colour content in the images (which is subject to season), can cause abrupt and undesirable changes in the raw data.
We decided to use the discrete wavelet transform (DWT) to process the images. The DWT is known for its ability to extract spatially localised frequency information. We perform the two-dimensional DWT on every image and average the energy of transformation coefficients within each subband to achieve approximate shift invariance of the feature extractor. We expect that the appearance of a novel image in the sequence will manifest itself as a sudden change in the power in the frequency content of the vector of subband intensities. At each timestep, we construct a wavelet feature vector from each image obtained by each camera node.
The Abilene backbone network in the US contains ![]() core routers. A
backbone flow consists of packets entering the Abilene
network at one particular core router and exiting at another. The
data constitute a timeseries of the entropies of the
core routers. A
backbone flow consists of packets entering the Abilene
network at one particular core router and exiting at another. The
data constitute a timeseries of the entropies of the ![]() main
packet header fields (source IP address, destination IP address,
source port number and destination port number) in each of
main
packet header fields (source IP address, destination IP address,
source port number and destination port number) in each of
![]() backbone flows pertaining to each timestep. The
entropy for each backbone flow, at each timestep, for each header
field, is computed after constructing an empirical histogram of the
relevant header field distribution for that backbone flow during
that timestep. The four component entropies are finally
concatenated to obtain an entropy timeseries of the
backbone flows pertaining to each timestep. The
entropy for each backbone flow, at each timestep, for each header
field, is computed after constructing an empirical histogram of the
relevant header field distribution for that backbone flow during
that timestep. The four component entropies are finally
concatenated to obtain an entropy timeseries of the ![]() backbone
flows. Physical anomalous phenomena cause changes in the
distributions of packets belonging to the responsible backbone flow,
and Lakhina et al. showed in [6] that these changes are
best captured by changes in the entropies. The duration of a
timestep is again five minutes, and the length of the Abilene
timeseries is
backbone
flows. Physical anomalous phenomena cause changes in the
distributions of packets belonging to the responsible backbone flow,
and Lakhina et al. showed in [6] that these changes are
best captured by changes in the entropies. The duration of a
timestep is again five minutes, and the length of the Abilene
timeseries is ![]() timesteps pertaining to one week (Dec. 15 to
21, 2003).
timesteps pertaining to one week (Dec. 15 to
21, 2003).
The OCNM algorithm proposed by Muñoz and Moguerza provides an
elegant means for estimating minimum volume sets [14]. It
assumes a sample set
![]() comprising
comprising ![]() ,
, ![]() -dimensional
data points,
-dimensional
data points,
![]() . The algorithm requires the choice
of a sparsity measure, denoted by
. The algorithm requires the choice
of a sparsity measure, denoted by ![]() . Example choices of a
sparsity measure are the
. Example choices of a
sparsity measure are the ![]() -th nearest neighbour Euclidean distance
and the average of the first
-th nearest neighbour Euclidean distance
and the average of the first ![]() nearest-neighbour distances. The
OCNM algorithm sorts the values of the
nearest-neighbour distances. The
OCNM algorithm sorts the values of the ![]() measure for the set of
points
measure for the set of
points
![]() , and subsequently identifies those points that
lie inside the minimum volume set (MVS) with the smallest sparsity
measure
, and subsequently identifies those points that
lie inside the minimum volume set (MVS) with the smallest sparsity
measure ![]() , up to a specified fraction
, up to a specified fraction ![]() of the number of
points in
of the number of
points in
![]() .
.
If the ![]() -th nearest neighbour distance function is used as the
sparsity measure, the OCNM algorithm involves calculating the
distance from every point
-th nearest neighbour distance function is used as the
sparsity measure, the OCNM algorithm involves calculating the
distance from every point
![]() to every other point in
the sample set. As each point is
to every other point in
the sample set. As each point is ![]() -dimensional and there are
-dimensional and there are ![]() timesteps, the complexity is
timesteps, the complexity is ![]() .
.
![\includegraphics[width = 2in]{Figs/1_time_368.eps}](img38.png) [Camera 2]
[Camera 2]
![\includegraphics[width = 2in]{Figs/2_time_368.eps}](img39.png) [Camera 3]
[Camera 3]
![\includegraphics[width = 2in]{Figs/3_time_368.eps}](img40.png) [Camera 4]
[Camera 4]
![\includegraphics[width = 2in]{Figs/4_time_368.eps}](img41.png) [Camera 5]
[Camera 5]
![\includegraphics[width = 2in]{Figs/5_time_368.eps}](img42.png) [Camera 6]
[Camera 6]
![\includegraphics[width = 2in]{Figs/6_time_368.eps}](img43.png) |
Consider a set of multivariate measurements
![]() . In an appropriately chosen feature space
. In an appropriately chosen feature space
![]() with an associated kernel function
with an associated kernel function
![]() , the
features corresponding to the normal traffic measurements should
cluster. Then it should be possible to describe the region
of normality using a relatively small dictionary of
approximately linearly independent elements
, the
features corresponding to the normal traffic measurements should
cluster. Then it should be possible to describe the region
of normality using a relatively small dictionary of
approximately linearly independent elements
![]() [19]. Here
[19]. Here
![]() represent those
represent those
![]() that are entered into the dictionary and
we expect the size of the dictionary (
that are entered into the dictionary and
we expect the size of the dictionary (![]() ) to be much less than
) to be much less than ![]() ,
leading to computational and storage savings. Feature vector
,
leading to computational and storage savings. Feature vector
![]() is said to be approximately linearly
dependent on
is said to be approximately linearly
dependent on
![]() with
approximation threshold
with
approximation threshold ![]() , if the projection error
, if the projection error ![]() satisfies the following criterion:
satisfies the following criterion:
The Kernel-based Online Anomaly Detection (KOAD) algorithm operates
at each timestep ![]() on a measurement vector
on a measurement vector
![]() . It begins by
evaluating the error
. It begins by
evaluating the error ![]() in projecting the arriving
in projecting the arriving
![]() onto the current dictionary (in the feature domain). This error
measure
onto the current dictionary (in the feature domain). This error
measure ![]() is then compared with two thresholds
is then compared with two thresholds ![]() and
and ![]() , where
, where
![]() . If
. If
![]() ,
we infer that
,
we infer that
![]() is sufficiently linearly dependent on the
dictionary, and represents normal traffic. If
is sufficiently linearly dependent on the
dictionary, and represents normal traffic. If
![]() ,
we conclude that
,
we conclude that
![]() is far away from the realm of normal
behaviour, and immediately raise a ``Red1'' alarm to signal an
anomaly.
is far away from the realm of normal
behaviour, and immediately raise a ``Red1'' alarm to signal an
anomaly.
If
![]() , we infer that
, we infer that
![]() is sufficiently
linearly independent from the dictionary to be considered an unusual
event. It may indeed be an anomaly, or it may represent an
expansion or migration of the space of normality. In this case, we
do the following: raise an ``Orange'' alarm, keep track of the
contribution of the relevant input vector
is sufficiently
linearly independent from the dictionary to be considered an unusual
event. It may indeed be an anomaly, or it may represent an
expansion or migration of the space of normality. In this case, we
do the following: raise an ``Orange'' alarm, keep track of the
contribution of the relevant input vector
![]() in explaining
subsequent arrivals for
in explaining
subsequent arrivals for ![]() timesteps, and then make a firm
decision on it.
timesteps, and then make a firm
decision on it.
At timestep ![]() , we re-evaluate the error
, we re-evaluate the error ![]() in
projecting
in
projecting
![]() onto dictionary
onto dictionary
![]() corresponding to timestep
corresponding to timestep ![]() . Note that the dictionary may
have changed between timesteps
. Note that the dictionary may
have changed between timesteps ![]() and
and ![]() , and the value of
, and the value of
![]() at this re-evaluation may consequently be different from
the
at this re-evaluation may consequently be different from
the ![]() at timestep
at timestep ![]() . If the value of
. If the value of ![]() after the
re-evaluation is found to be less than
after the
re-evaluation is found to be less than ![]() , we lower the
orange alarm and keep the dictionary unchanged.
, we lower the
orange alarm and keep the dictionary unchanged.
If the value of ![]() is found instead to be greater than
is found instead to be greater than
![]() after the re-evaluation at timestep
after the re-evaluation at timestep ![]() , we perform a
secondary ``usefulness'' test to resolve the orange alarm. The
usefulness of
, we perform a
secondary ``usefulness'' test to resolve the orange alarm. The
usefulness of
![]() is assessed by observing the kernel values of
is assessed by observing the kernel values of
![]() with
with
![]() ,
,
![]() . If a kernel value is
high (greater than a threshold
. If a kernel value is
high (greater than a threshold ![]() ), then
), then
![]() is deemed
close to
is deemed
close to
![]() . If a significant number of the kernel
values are high, then
. If a significant number of the kernel
values are high, then
![]() cannot be considered anomalous; normal
traffic has just migrated into a new portion of the feature space
and
cannot be considered anomalous; normal
traffic has just migrated into a new portion of the feature space
and
![]() should be entered into the dictionary. Contrarily if
almost all kernel values are small, then
should be entered into the dictionary. Contrarily if
almost all kernel values are small, then
![]() is a reasonably
isolated event, and should be heralded as an anomaly. We evaluate:
is a reasonably
isolated event, and should be heralded as an anomaly. We evaluate:
The KOAD algorithm also deletes obsolete elements from the dictionary as the region of normality expands or migrates, thereby maintaining a small dictionary. In addition, it incorporates exponential forgetting so that the impact of past observations is gradually reduced.
Assuming a dictionary containing ![]() elements, the computational
complexity of the KOAD algorithm is
elements, the computational
complexity of the KOAD algorithm is
![]() for every
standard timestep, and
for every
standard timestep, and
![]() on the rare occasions when
an element removal occurs. The KOAD complexity is thus independent
of time, making the algorithm naturally suited to online
applications. Our experiments have shown that high sparsity levels
are achieved in practice, and the dictionary size does not grow
indefinitely. See [15] for details regarding the KOAD
algorithm.
on the rare occasions when
an element removal occurs. The KOAD complexity is thus independent
of time, making the algorithm naturally suited to online
applications. Our experiments have shown that high sparsity levels
are achieved in practice, and the dictionary size does not grow
indefinitely. See [15] for details regarding the KOAD
algorithm.
We propose two monitoring architectures: a distributed approach and
a centralised approach. In the distributed architecture, the
detection algorithms are locally run at each node. After each
timestep, each node makes a local decision regarding the presence or
absence of an anomaly at that timestep, and transmits a
binary result to the Central Monitoring Unit (CMU). The
CMU then makes a decision on the location of an anomaly in time and
space, if at least ![]() of the
of the ![]() nodes individually signalled an
anomaly. The idea behind this
nodes individually signalled an
anomaly. The idea behind this ![]() -out-of-
-out-of-![]() detection scheme is
that in many applications, such as in a road network, bona
fide anomalies such as an untimely traffic congestion are
simultaneously evident to multiple nodes. Individual flags are
likely to be caused by comparably less important and independent
events such as a single camera malfunctioning.
detection scheme is
that in many applications, such as in a road network, bona
fide anomalies such as an untimely traffic congestion are
simultaneously evident to multiple nodes. Individual flags are
likely to be caused by comparably less important and independent
events such as a single camera malfunctioning.
In the centralised architecture, all measurements are communicated to the Central Monitoring Unit. The CMU then runs the detection algorithm. The centralised approach is often desirable and necessary to detect anomalies that exhibit themselves through distributed changes in the global measurement vector. The works of Lakhina et al. have shown that traffic volume distributions in large backbone IP networks exhibit a covariance structure, and detecting a break in this structure enables one to unearth a wide range of anomalies [4,5,6].
In this section, we study the effectiveness of OCNM and KOAD in
detecting unusual events in Quebec's road network. We apply OCNM
and KOAD to image sequences from Transports Quebec webcam network.
This is an example application of the distributed monitoring
architecture described in Section IV-C. Our data consists
of a series of ![]() timesteps corresponding to daylight hours
during the Sep. 30 to Oct. 03, 2006 period. We use the averaged
energy of DWT coefficients (see Section III-.1) from
timesteps corresponding to daylight hours
during the Sep. 30 to Oct. 03, 2006 period. We use the averaged
energy of DWT coefficients (see Section III-.1) from
![]() subbands from each of the
subbands from each of the ![]() cameras (nodes). In our
application with
cameras (nodes). In our
application with ![]() cameras, we used
cameras, we used ![]() as the central
decision rule.
as the central
decision rule.
We present illustrative images from the ![]() -camera network
corresponding to a traffic congestion in Fig. 1.
Given the normal flow of traffic during the length of our dataset,
short periods of congestion constitute an example of a road network
anomaly. This timestep was flagged in all
-camera network
corresponding to a traffic congestion in Fig. 1.
Given the normal flow of traffic during the length of our dataset,
short periods of congestion constitute an example of a road network
anomaly. This timestep was flagged in all ![]() nodes by both OCNM
and KOAD as anomalous, for most representative algorithm parameter
settings.
nodes by both OCNM
and KOAD as anomalous, for most representative algorithm parameter
settings.
Fig. 2(top panel) shows the results of
wavelet analysis of the image sequence from one camera. We selected
one of the six cameras for preliminary assessment of feature
extraction quality. It can be seen that the high-frequency
components of the feature vector show the expected variation in the
vicinity of traffic jams. Abrupt changes to the position of a
camera generate sudden spikes in the feature vector components. Fig.
2 (middle panel) shows the distance
measures obtained using the OCNM algorithm with ![]() set to
set to ![]() and
using
and
using ![]() to signal the
to signal the ![]() outliers. Fig.
2(bottom panel) shows the variations in
KOAD projection error
outliers. Fig.
2(bottom panel) shows the variations in
KOAD projection error
![]() . We ran the KOAD algorithm here
with the thresholds
. We ran the KOAD algorithm here
with the thresholds
![]() and
and
![]() , a Gaussian
kernel having standard deviation
, a Gaussian
kernel having standard deviation ![]() , and default settings for
all other parameters (see [15]) which includes the orange
alarm being resolved after
, and default settings for
all other parameters (see [15]) which includes the orange
alarm being resolved after ![]() timesteps (i.e.
timesteps (i.e. ![]() ). We
begin our analysis of Fig. 2 at
). We
begin our analysis of Fig. 2 at ![]() with the previous timesteps constituting the training period in this
application.
with the previous timesteps constituting the training period in this
application.
![\includegraphics[width=\columnwidth]{Figs/Fig2a1.eps}](img90.png) |
Fig. 3 presents the receiver operating
characteristics (ROC) curves showing the variation in the
probability of detection (![]() ) with the probability of false
alarms (
) with the probability of false
alarms (![]() ), for the OCNM and KOAD algorithms applied to the
Transports Quebec dataset. In our experiments, we used OCNM with
the nearest-neighbour parameter
), for the OCNM and KOAD algorithms applied to the
Transports Quebec dataset. In our experiments, we used OCNM with
the nearest-neighbour parameter ![]() set to
set to ![]() , and varying
, and varying ![]() from
from ![]() to
to ![]() to signal between
to signal between ![]() and
and ![]() outliers.
We ran KOAD with the thresholds set to
outliers.
We ran KOAD with the thresholds set to
![]() , and using a Gaussian kernel where the standard
deviation of the kernel function is varied between
, and using a Gaussian kernel where the standard
deviation of the kernel function is varied between ![]() and
and
![]() . The other KOAD parameters are retained at their default
values (see [15]), with an orange alarm resolved after
. The other KOAD parameters are retained at their default
values (see [15]), with an orange alarm resolved after
![]() timesteps (i.e.
timesteps (i.e. ![]() ).
).
Although our experiments were performed on a limited data set, this result provides a preliminary assessment of the anomaly detection algorithms based on wavelet feature extraction mechanism and machine learning data clustering approaches. It can be clearly seen from Fig. 3 that the KOAD detector outperforms the OCNM detector.
![\includegraphics[width=0.95\columnwidth]{Figs/Fig3.eps}](img98.png) |
In this subsection we present the results of applying OCNM and KOAD to the Abilene dataset. Here we want to also detect those anomalies that cause sudden changes in the overall distribution of traffic over the network, as opposed to affecting a single link, during a particular timestep. Thus in this application we implement the centralised architecture proposed in Section IV-C. For discussions on the wide range of anomalies seen in IP networks, refer to the works of Lakhina et al. [4,5,6]. Here we also compare our results with those obtained by Lakhina et al. using the PCA subspace method of anomaly detection.
Fig. 4(a) shows the variations in
![]() obtained using the KOAD algorithm with
obtained using the KOAD algorithm with
![]() , a Gaussian kernel of standard deviation
, a Gaussian kernel of standard deviation ![]() , and
default settings for all other parameters (see [15]). We
start our analysis at
, and
default settings for all other parameters (see [15]). We
start our analysis at ![]() , with the previous timesteps
disregarded as constitute the training period in this application.
Fig. 4(b) shows the magnitude of the energy
in the residual components using the PCA subspace method of anomaly
detection [6]. We used
, with the previous timesteps
disregarded as constitute the training period in this application.
Fig. 4(b) shows the magnitude of the energy
in the residual components using the PCA subspace method of anomaly
detection [6]. We used ![]() principle components for the
normal subspace, in accordance with [6]. Fig.
4(c) shows the distance measures obtained
using OCNM with
principle components for the
normal subspace, in accordance with [6]. Fig.
4(c) shows the distance measures obtained
using OCNM with ![]() , together with the threshold indicating the
, together with the threshold indicating the
![]() minimum volume set. The spike positions in Figs.
4(a-c) indicate the anomalies signalled by
KOAD, PCA and OCNM, respectively. Fig. 4(d)
isolates for comparison the positions of the anomalies detected by
each individual algorithm.
minimum volume set. The spike positions in Figs.
4(a-c) indicate the anomalies signalled by
KOAD, PCA and OCNM, respectively. Fig. 4(d)
isolates for comparison the positions of the anomalies detected by
each individual algorithm.
It is evident from Fig. 4(c) that the OCNM
![]() -th nearest neighbour distance metric experiences an upward trend
during the one-week period. This phenomenon was observed for values
of
-th nearest neighbour distance metric experiences an upward trend
during the one-week period. This phenomenon was observed for values
of ![]() that ranged from
that ranged from ![]() to
to ![]() . Although the positions of
the spikes (with respect to the immediate surrounding timesteps) in
Fig. 4(c) largely correspond with those in
Fig. 4(a-b), we see that most of the outliers
signalled by OCNM lie in the latter part of the plot.
. Although the positions of
the spikes (with respect to the immediate surrounding timesteps) in
Fig. 4(c) largely correspond with those in
Fig. 4(a-b), we see that most of the outliers
signalled by OCNM lie in the latter part of the plot.
The increasing distance metric suggests that the space of normal traffic expands over the recorded time period. The KOAD algorithm is best able to detect anomalies in such a situation, as the dictionary in this algorithm is dynamic, with obsolete elements being removed and new, more relevant elements added as necessary. Indeed, we noticed in our experiments with this particular dataset that the dictionary members change significantly over the reported period.
Fig. 4(c) also argues the need for a
sequential or block-based version of OCNM where outliers may be
incrementally reported after every timestep or block of timesteps.
When we ran OCNM on the first ![]() data points only, it flagged
the same anomalies as KOAD.
data points only, it flagged
the same anomalies as KOAD.
![\includegraphics[width=\columnwidth]{Figs/Fig4.eps}](img106.png) |
Our preliminary results of the application of machine learning techniques to network anomaly detection indicate their potential and highlight the areas where improvement is required. The non-stationary nature of the network measurements, be they network traffic metrics or recordings of physical phenomena, makes it imperative that the algorithms be able to adapt over time. To make the algorithms portable to different applications and robust to diverse operating environments, all parameters must be learned and autonomously set from arriving data. The algorithms must be capable of running in real-time despite being presented with large volumes of high-dimensional, noisy, distributed data. This means that the methods must perform sequential (recursive) calculations with the complexity at each timestep being independent of time. The computations must be distributed amongst the nodes in the network, and communication, which consumes network resources and introduces undesirable latency in detection, must be minimised.
The KOAD algorithm satisfies some of these requirements, being recursive in nature and adapting to changing data streams. However, in its current form it does not learn appropriate parameter settings, exhibits sensitivity to threshold choices, and has no natural distributed form. The distributed architecture we have described in this paper is a sub-optimal system. Our current and future research focuses on rectifying these deficiencies in the KOAD approach and exploring other promising learning-based alternatives to the network anomaly detection challenge.
The authors thank Sergio Restrepo for processing the Transports Quebec data and Anukool Lakhina for providing the Abilene dataset. This research was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) and industrial and government partners, through the Agile All-Photonic Networks (AAPN) research network. The research was also supported by Mathematics of Information Technology and Complex Systems (MITACS) under the NSERC Network of Centres of Excellence (NCE) program.
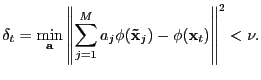
![$\displaystyle \left[\sum_{i=t+1}^{t+\ell}
\mathbb{I}(\mathop{k}({\mathbf x}_t,{\mathbf x}_i)>d)\right] > \epsilon \ell,$](img69.png)