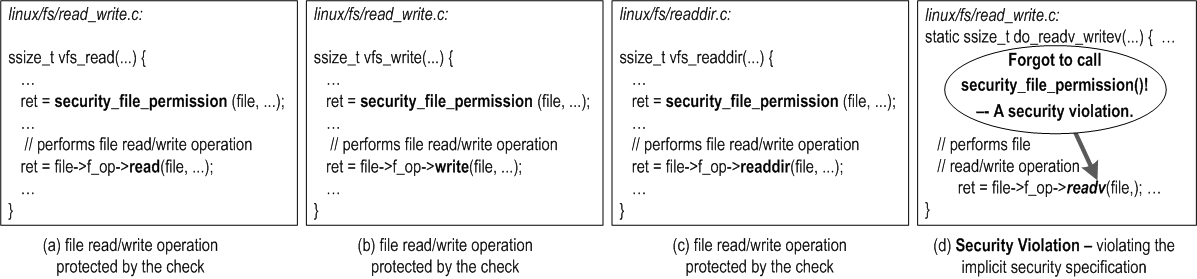
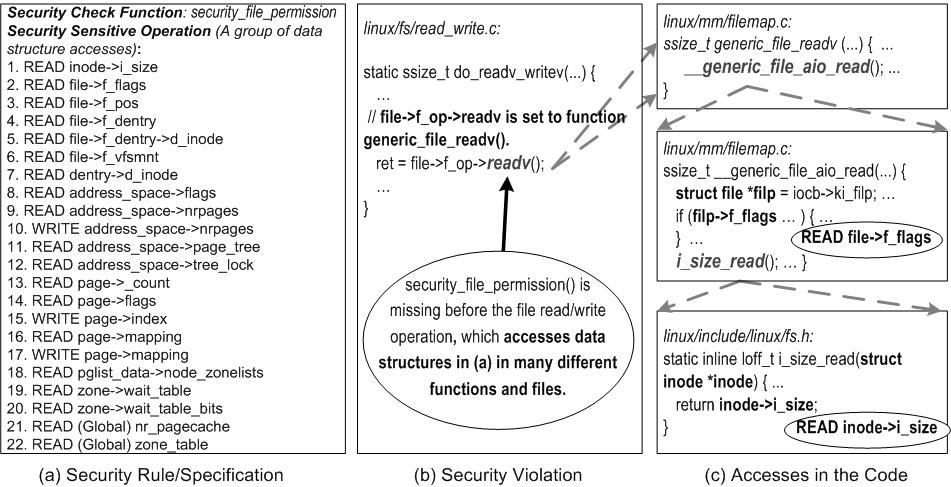
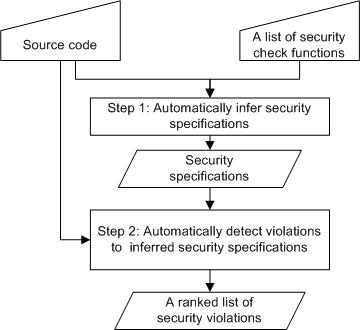
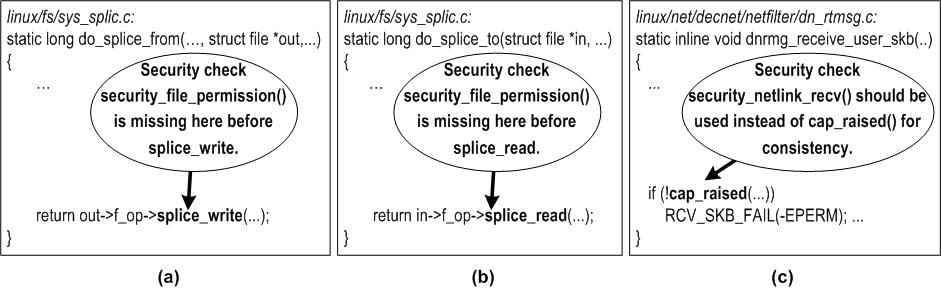
| Challenge | Our Solution | Sec. |
| How to represent a sensitive operation at the code level | Use Data structure accesses based on our key observation | 1.2 & 3.2 |
| High false positive rates as many sensitive operations can not be exposed to the untrusted space | Simple untrusted space exposability study to greatly reduce false positives | 3.1 |
| Root functions for analysis: Cannot simply start analysis from direct callers of a security check function | Automatic root function discovery: Automatically discover functions that actually use security check functions for authorization check | 4.2.1 |
| Insufficient invocation instances of security check functions | Leverage different implementations (e.g., from different file systems) of the same operation | 4.2.4 |
| Data structure accesses are spread in different functions. | Interprocedural analysis with function pointer analysis | 4.3 |