
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Security '05 Paper
[Security '05 Technical Program]
An Architecture for Generating Semantics-Aware Signatures
Vinod Yegneswaran,
Jonathon T. Giffin,
Paul Barford, and
Somesh Jha
AbstractIdentifying new intrusions and developing effective signatures that detect them is essential for protecting computer networks. We present Nemean, a system for automatic generation of intrusion signatures from honeynet packet traces. Our architecture is distinguished by its emphasis on a modular design framework that encourages independent development and modification of system components and protocol semantics awareness which allows for construction of signatures that greatly reduce false alarms. The building blocks of our architecture include transport and service normalization, intrusion profile clustering and automata learning that generates connection and session aware signatures. We demonstrate the potential of Nemean's semantics-aware, resilient signatures through a prototype implementation. We use two datasets to evaluate the system: (i) a production dataset for false-alarm evaluation and (ii) a honeynet dataset for measuring detection rates. Signatures generated by Nemean for NetBIOS exploits had a 0% false-positive rate and a 0.04% false-negative rate.
Computer network security is a multidimensional activity that continues to
grow in importance. The prevalence of attacks in the Internet
and the ability of self-propagating worms to infect millions of Internet
hosts has been well documented [30,34]. Developing
techniques and tools that
enable more precise and more rapid detection of such attacks presents
significant challenges for both the research and operational communities.
|
 |
We have implemented prototypes of each Nemean component. While the Nemean design provides flexibility to handle any protocol, we focus our discussion on two specific protocol implementations, HTTP (port 80) and NetBIOS/SMB (ports 139 and 445), since these two services exhibit great diversity in the number and types of exploits.
![]() Transport-Level Normalization:
Transport-level normalization resolves ambiguities introduced at
the network (IP) and transport (TCP) layers of the protocol stack.
We check message integrity, reorder
packets as needed, and discard invalid or duplicate packets. The
importance of transport layer normalizers has been addressed in the
literature [6,21]. Building a normalizer that
perfectly resolves all ambiguities is a complicated endeavor, especially
since many ambiguities are operating system dependent. We can constrain the
set of normalization functions for two reasons. First, we only consider
traffic sent to honeynets, so we have perfect
knowledge of the host environment. This environment remains relatively
constant. We do not need to worry about ambiguities introduced due to
DHCP or network address translation (NAT). Second,
Nemean's current implementation analyzes network traces off-line which
relaxes its state holding requirements and makes it less vulnerable to
resource-consumption attacks.
Transport-Level Normalization:
Transport-level normalization resolves ambiguities introduced at
the network (IP) and transport (TCP) layers of the protocol stack.
We check message integrity, reorder
packets as needed, and discard invalid or duplicate packets. The
importance of transport layer normalizers has been addressed in the
literature [6,21]. Building a normalizer that
perfectly resolves all ambiguities is a complicated endeavor, especially
since many ambiguities are operating system dependent. We can constrain the
set of normalization functions for two reasons. First, we only consider
traffic sent to honeynets, so we have perfect
knowledge of the host environment. This environment remains relatively
constant. We do not need to worry about ambiguities introduced due to
DHCP or network address translation (NAT). Second,
Nemean's current implementation analyzes network traces off-line which
relaxes its state holding requirements and makes it less vulnerable to
resource-consumption attacks.
Attacks that attempt to evade a NIDS by introducing ambiguities to IP packets are well known. Examples of such attacks include simple insertion attacks that would be dropped by real systems but are evaluated by NIDS, and evasion attacks that are the reverse [21]. Since Nemean obtains traffic promiscuously via a packet sniffer (just like real a NIDS), these ambiguities must be resolved. We focus on three common techniques used by attackers to elude detection.
First, an invalid field in a protocol header may cause a NIDS to handle the packet differently than the destination machine. Handling invalid protocol fields in IP packets involves two steps: recognizing the presence of the invalid fields and understanding how a particular operating system would handle them. Our implementation performs some of these validations. For example, we drop packets with an invalid IP checksum or length field.
Second, an attacker can use IP fragmentation to present different data to the NIDS than to the destination. Fragmentation introduces two problems: correctly reordering shuffled packets and resolving overlapping segments. Various operating systems address these problems in different ways. We adopt the always-favor-old-data method used by Microsoft Windows. A live deployment must either periodically perform active-mapping [26] or match rules with passive operating system fingerprinting. The same logic applies for fragmented or overlapping TCP segments.
Third, incorrect understanding of the TCP Control Block (TCB) tear-down timer can cause a NIDS to improperly maintain state. If it closes a connection too early it will lose state. Likewise, retaining connections too long can prevent detection of legitimate later connections. Our implementation maintains connection state for an hour after session has been closed. However, sessions that have been closed or reset are replaced earlier if a new connection setup is observed between the same host/port pairs.
![]() Service-Level Normalization:
We provide a brief discussion of the implementation of service
normalizers for two popular protocols: HTTP and NetBIOS/SMB.
Service-Level Normalization:
We provide a brief discussion of the implementation of service
normalizers for two popular protocols: HTTP and NetBIOS/SMB.
Ambiguities in HTTP sessions are primarily introduced due to invalid protocol parsing or invalid decoding of protocol fields. In particular, improper URL decoding is a point of vulnerability in many intrusion detection systems. Modern web servers allow substitution of encoded characters for ASCII characters in the URL and are often exploited as means for evasion of common NIDS signatures. Our DAC correctly decodes several observed encodings such as hex encoding and its variants, UTF-8 encoding, bare-byte encoding, and Microsoft Unicode encoding. Regardless of its encoding, the DAC presents a canonical URL in ASCII format to the clustering module. Currently, our implementation does not handle all obvious HTTP obfuscations. For example, we do not process pipelined HTTP/1.1 requests. Such requests need to be broken into multiple connections for analysis. We plan to incorporate this functionality into our system in the future.
NetBIOS is a session-layer service that enables machines to exchange messages using names rather than IP addresses and port numbers. SMB (Server Message Block) is a transport-independent protocol that provides file and directory services. Microsoft Windows machines use NetBIOS to exchange SMB file requests. NetBIOS/SMB signature evasion techniques have not been well studied, possibly due to the lack of good NIDS rules for their detection. A full treatment of possible NetBIOS/SMB ambiguities exceeds the scope of this paper.
We designed the Multi-level Signature Generalization (MSG) algorithm to automatically produce signatures for normalized session data. The signatures must balance specificity to the exploits observed in the data with generality, the ability to detect attack variants not previously observed. We use machine-learning algorithms, including clustering and finite state machine generalization, to produce signatures that are well-balanced.
Due to the hierarchical nature of the session data, we construct signatures for connections and sessions separately. First, we cluster all connections irrespective of the sessions that contain them and generalize each cluster to produce a signature for each connection cluster. Second, we cluster sessions based upon their constituent connections and then generalize the clusters. Finally, we combine the session and connection signatures to produce a hierarchical automaton signature, where each connection in a session signature must match the corresponding connection signature. Figure 3 presents a high-level overview of the algorithm.
Steps 1 and 2: Generating connection clusters. Let ![]() be the
multiset of normalized sessions produced by the data
abstraction component. Denote each session
be the
multiset of normalized sessions produced by the data
abstraction component. Denote each session ![]() as an ordered list of
connections:
as an ordered list of
connections:
![]() . Let
. Let
![]() be the multiset of connections in
be the multiset of connections in
![]() and
and
![]() be the multiset of all
connections in the normalized data, where
be the multiset of all
connections in the normalized data, where ![]() denotes
multiset union. Let
denotes
multiset union. Let
![]() be an exclusive clustering of
be an exclusive clustering of ![]() into
into ![]() clusters
clusters
![]() . Clustering inserts every element into a
partition, so
. Clustering inserts every element into a
partition, so
![]() . Exclusive clustering requires that no
partitions overlap, so
. Exclusive clustering requires that no
partitions overlap, so
![]() for
for ![]() . It immediately follows that there exists a well-defined
function
. It immediately follows that there exists a well-defined
function
![]() defined as
defined as
![]() if
if ![]() that returns the cluster containing
that returns the cluster containing ![]() .
Section 5.1 presents the implementation of the
clustering algorithm.
.
Section 5.1 presents the implementation of the
clustering algorithm.
Step 3: Building connection-level signatures. Learning algorithms
generalize the data in each cluster to produce
signatures that match previously unseen connections. Let ![]() be
the alphabet of network events comprising connection data. A learning
algorithm is a function
be
the alphabet of network events comprising connection data. A learning
algorithm is a function
![]() that takes a set of strings
that takes a set of strings
![]() and returns a regular
language
and returns a regular
language
![]() .
Section 5.2 presents the generalization
algorithms used in our work. We recognize
.
Section 5.2 presents the generalization
algorithms used in our work. We recognize ![]() with a regular
automaton that is the connection-level signature for cluster
with a regular
automaton that is the connection-level signature for cluster ![]() .
.
Steps 4 and 5: Generating session clusters.
Rewrite the existing
sessions to produce a new set ![]() .
.
![$\displaystyle S' = \biguplus_{s = c_1 . \cdots . c_{n_s} \in S} \big[ s' =
\Gamma(c_1) . \cdots . \Gamma(c_{n_s}) \big]
$](img31.png)
Steps 6 and 7: Building session-level signatures. As with
connection-level generalization, construct a regular language
![]() for each cluster
for each cluster
![]() that accepts the sessions in
that accepts the sessions in
![]() and variants of those sessions. Again, we recognize the
language with a finite automaton. The connection cluster identifiers
and variants of those sessions. Again, we recognize the
language with a finite automaton. The connection cluster identifiers
![]() label transitions in the session-level automata. The
resulting signature is thus hierarchical: traversing a transition in
the session signature requires connection data matching the signature
for the connection cluster.
label transitions in the session-level automata. The
resulting signature is thus hierarchical: traversing a transition in
the session signature requires connection data matching the signature
for the connection cluster.
We cluster connections and sessions using the same algorithm. We
implemented the on-line star clustering algorithm, which clusters
documents based upon a similarity metric [2]. This
algorithm has advantages over more commonly-known techniques, such as
the ![]() -means family of algorithms [14]. For example, star
clustering is robust to data ordering. Conversely,
-means family of algorithms [14]. For example, star
clustering is robust to data ordering. Conversely, ![]() -means produces
different clusters depending upon the order in which data is read.
Moreover, we need not know a priori how many clusters are
expected. Although it seems suitable, we make no claims that star is
the optimal clustering algorithm for our purposes, and we expect to
consider other algorithms in future work.
-means produces
different clusters depending upon the order in which data is read.
Moreover, we need not know a priori how many clusters are
expected. Although it seems suitable, we make no claims that star is
the optimal clustering algorithm for our purposes, and we expect to
consider other algorithms in future work.
Star clustering builds a star cover over a partially-connected graph. Nodes in the graph each represent one or more items with semantically equivalent data. We arbitrarily choose one item at each node to be the representative item. A link exists between two nodes if the similarity between the corresponding representative items is above a designated threshold. A star cluster is a collection of nodes in the graph such that each node connects to the cluster center node with an edge. A star cover is a collection of star clusters covering the graph so that no two cluster centers have a connecting edge. In the original algorithm, a non-center node may have edges to multiple center nodes and thus appear in multiple clusters. We implemented a modified algorithm that inserts a node only into the cluster with which it has strongest similarity to produce an exclusive clustering.
Item similarity determines how edges are placed in the graph. We implemented two different similarity metrics to test sensitivity: cosine similarity [2] and hierarchical edit distance. The cosine similarity metric has lower computational complexity than hierarchical edit distance and was used for our experiments in Section 7.
 |
 |
Cosine similarity computes the angle between two vectors representing
the two items under comparison. For each connection ![]() , we build a
vector
, we build a
vector ![]() giving the distribution of bytes, request types, and
response codes that appeared in the network data. For sessions, the
vector contains the distribution of connection cluster identifiers.
If
giving the distribution of bytes, request types, and
response codes that appeared in the network data. For sessions, the
vector contains the distribution of connection cluster identifiers.
If ![]() is the angle between vectors
is the angle between vectors ![]() and
and ![]() representing
items
representing
items ![]() and
and ![]() , then:
, then:
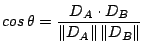
Hierarchical-edit distance is a variation on the traditional edit-distance metric [2] which measures the cost of transforming one string into another using insert, delete, and replace operations. In contrast to the traditional edit-distance metric, the hierarchical-edit distance metric preserves connection ordering information within each session and differentiates between the various data fields within each connection. We believed these properties of the hierarchical-edit distance metric would make it a better similarity metric for clustering than the cosine metric. Our experiments revealed that while both distance metrics work quite well, cosine is less sensitive to the threshold parameters used in partitioning clusters. Hence, we use cosine distance in this paper's experiments and describe the hierarchical edit distance metric in the expanded technical report [35].
Using a similarity metric, we construct the partially-connected similarity graph. An edge connects a pair of nodes if the similarity of the representative sessions is above a threshold, here 0.8. We then build a star cover over the similarity graph. Each star cluster is a group of similar sessions that presumably are variants of the same exploit. The cluster set is then passed to the generalization module to produce the automaton signature.
Signature generation devises a NIDS signature from a cluster of similar connections or sessions. We generalize variations observed in a cluster's data. Assuming effective clustering, these variations correspond to obfuscation attempts or differences among variants of the same attack. By generalizing the differences, we produce a resilient signature that accepts data not necessarily observed during the training period.
The signature is a finite state automaton. We first construct a probabilistic finite state automaton (PFSA) accepting exactly the event sequences contained in a cluster, with edge weights corresponding to the number of times an edge is traversed when accepting all cluster data exactly once. PFSA learning algorithms [24] then use stochastic measures to generalize the data variations observed in a cluster. In this work, we generalized HTTP connection-level signatures with the sk-strings method [24], an algorithm that merges states when they are probabilistically indistinguishable. Session-level clusters were generalized with beam search [17]. Our algorithm uses both sk-strings and simulated beam annealing [23] to generalize NetBIOS signatures. These generalizations add transitions into the state machine to accommodate such variations as data reordering and alteration of characters in an attack string. Likewise, repeated strings may be generalized to allow any number of repeats.
We further generalize signatures at points of high data variability.
Subsequence creation converts a signature that matches a sequence of
session data into a signature that matches a subsequence of that data
by inserting ``gaps'' that accept any sequence of arbitrary symbols. We
insert gaps whenever observing four or more
patterns with a common prefix, common suffix, and one dissimilar data
element. For example, let
![]() and
and
![]() . If the signature accepts
. If the signature accepts ![]() ,
,
![]() ,
, ![]() , and
, and ![]() , then we replace those four sequences with the
regular expression
, then we replace those four sequences with the
regular expression ![]() . Intuitively, we have identified a portion
of the signature exhibiting large variation and allow it vary
arbitrarily in our final signature.
Nemean's generalized signatures can thus detect variations of observed
attacks.
. Intuitively, we have identified a portion
of the signature exhibiting large variation and allow it vary
arbitrarily in our final signature.
Nemean's generalized signatures can thus detect variations of observed
attacks.
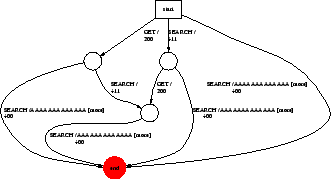
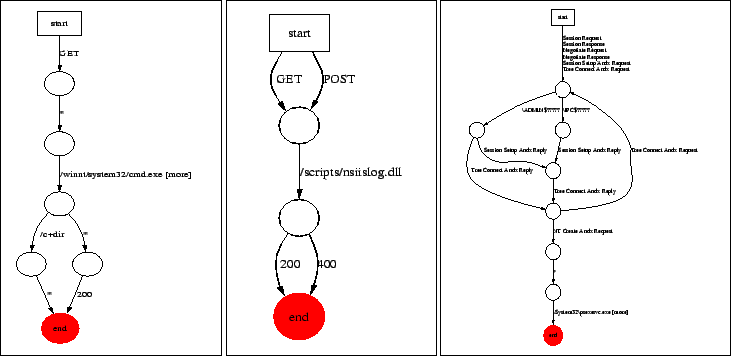
Figure 4 shows a session-level signature for Welchia, a worm that exploits a buffer overflow. Nemean's generalization produced a signature that matches a wide class of Welchia scans without losing the essential buffer overflow information characteristic to the worm. Figure 5 shows connection-level signatures for Nimda, a Windows Media Player exploit, and the Deloder NetBIOS worm. The connection-level Nimda signature is an example of a signature for an exploit with high diversity. In particular, note that the subsequence creation generalization allows this signature to match a wide class of Nimda attacks. The Windows Media Player exploit is representative of an HTTP exploit where the size of the exploit URL is small. Previous signature generation techniques, such as Honeycomb, fail for small URLs. The Deloder signature demonstrates the capability of Nemean to generate signatures for exploits using more complex protocols like NetBIOS/SMB.
The data used for our evaluation comes from two sources: (i) honeypot packet traces collected from unused address space that we used to build signatures and evaluate the detection capability of Nemean and (ii) packet traces collected from our departmental border router that we used to test the resilience of our signatures to false positives.
![]() Production Traffic: Obtaining packet traces for live network
traffic is a challenge due to privacy concerns. While network operators
are amenable to sharing flow level summaries, anonymizing payloads remains
an unsolvable problem and as such its hard to obtain packet traces with
application payloads.
Production Traffic: Obtaining packet traces for live network
traffic is a challenge due to privacy concerns. While network operators
are amenable to sharing flow level summaries, anonymizing payloads remains
an unsolvable problem and as such its hard to obtain packet traces with
application payloads.
We were able to obtain access to such data from our department's border router. The network is a sparsely allocated, well managed /16 network with approximately 24 web servers and around 400 clients. We were able to passively monitor all outgoing and incoming HTTP packets on this network for an 8 hour period. Table 1 provides a summary of this dataset.
![]() Honeypot Traffic:
Traffic from two unused /19 IP address blocks totaling 16K addresses
from address ranges allocated to our university was routed to our
honeynet monitoring environment. To normalize the traffic received by our
infrastructure a simple source-filtering rule was employed: one
destination IP address per source. Connections to additional
destination IP addresses were dropped by the filter.
Honeypot Traffic:
Traffic from two unused /19 IP address blocks totaling 16K addresses
from address ranges allocated to our university was routed to our
honeynet monitoring environment. To normalize the traffic received by our
infrastructure a simple source-filtering rule was employed: one
destination IP address per source. Connections to additional
destination IP addresses were dropped by the filter.
These filtered packets were subsequently routed to one of two systems based upon type-of-service. HTTP requests were forwarded to a fully patched Windows 2000 Server running on VMware. The NetBIOS/SMB traffic was routed to a virtual honeypot system similar to Honeyd. We routed NetBIOS/SMB packets to an active responder masquerading as an end host offering NetBIOS services rather than to the Windows 2000 Server for two reasons [33]. First, the fully patched Windows 2000 Server often rejected or disconnected the session before we had enough information to classify the attack vector accurately. This could be due to invalid NetBIOS names or user/password combinations. Our active responder accepted all NetBIOS names and user/password combinations. Second, Windows 2000 servers limit the number of simultaneous network share accesses which also inhibit connection requests from succeeding.
We collected two sets of traces, a short term training set (2 days) and a longer testing set (7 days) to evaluate Nemean detection capability as summarized in Table 2. The reduction in the volume of port 80 traffic moving from the 2-day to the 5-day dataset is not uncommon in honeynets due to the bursty nature of this traffic often associated with botnet activity [16].
![]() HTTP Clusters: Figure 6 provides
an overview of the major HTTP clusters in our learning data set.
WebDAV scans account for the majority of the attacks in our data set.
WebDAV is a collection of HTTP extensions that allow users to
collaboratively edit and manage documents in remote web
servers. Popular WebDAV methods used in exploits include OPTIONS,
SEARCH, and PROPFIND and are supported by Microsoft IIS web
servers. Scans for exploits of WebDAV vulnerabilities are gaining in
popularity and are also used by worms like Welchia. Nimda attacks
provide great diversity in the number of attack variants and HTTP URL
obfuscation techniques. These attacks exploit directory traversal
vulnerabilities on IIS servers to access cmd.exe or root.exe. Figure 5 contains a connection-level
signature for Nimda generated by Nemean. Details of other
observed exploits, such as Frontpage, web crawlers and open-proxy, are
provided in [35].
HTTP Clusters: Figure 6 provides
an overview of the major HTTP clusters in our learning data set.
WebDAV scans account for the majority of the attacks in our data set.
WebDAV is a collection of HTTP extensions that allow users to
collaboratively edit and manage documents in remote web
servers. Popular WebDAV methods used in exploits include OPTIONS,
SEARCH, and PROPFIND and are supported by Microsoft IIS web
servers. Scans for exploits of WebDAV vulnerabilities are gaining in
popularity and are also used by worms like Welchia. Nimda attacks
provide great diversity in the number of attack variants and HTTP URL
obfuscation techniques. These attacks exploit directory traversal
vulnerabilities on IIS servers to access cmd.exe or root.exe. Figure 5 contains a connection-level
signature for Nimda generated by Nemean. Details of other
observed exploits, such as Frontpage, web crawlers and open-proxy, are
provided in [35].
![]() NetBIOS Clusters: Worms that are typically better known as email viruses dominate the
NetBIOS clusters. Many of these viruses scan for open network shares
and this behavior dominated the observed traffic. They can be
broadly classified into three types:
NetBIOS Clusters: Worms that are typically better known as email viruses dominate the
NetBIOS clusters. Many of these viruses scan for open network shares
and this behavior dominated the observed traffic. They can be
broadly classified into three types:
1. Hidden and open share exploits: This includes viruses, including LovGate [5], NAVSVC, and Deloder [12], that use brute force password attacks to look for open folders and then deposit virus binaries in startup folders.
2. MS-RPC query exploits: Microsoft Windows provides the ability to remotely access MSRPC services through named pipes such as epmapper (RPC Endpoint Mapper), srvsvc (Windows Server Service), and samr (Windows Security Account Manager). Viruses often connect to the MSRPC services as guest users and then proceed to query the system for additional information that could lead to privileged user access. For example, connecting to the samr service allows the attacker to obtain an enumeration of domain users,
3. MS-RPC service buffer overflow exploits: The most well-known of these exploits are the epmapper service which allows access to the RPC-DCOM exploit [15] used by Blaster and the more recent lsarpc exploit used by Sasser [25]. We provide more details in the technical report [35].
![]() Cluster Quality: We quantitatively evaluated the
quality of clusters produced by the star
clustering algorithm using two common metrics: precision and
recall. Precision is the proportion of positive matches among
all the elements in each cluster. Recall is the fraction of positive
matches in the cluster among all possible positive matches in the data
set. Intuitively, precision measures the relevance of each cluster,
while recall penalizes redundant clusters.
Cluster Quality: We quantitatively evaluated the
quality of clusters produced by the star
clustering algorithm using two common metrics: precision and
recall. Precision is the proportion of positive matches among
all the elements in each cluster. Recall is the fraction of positive
matches in the cluster among all possible positive matches in the data
set. Intuitively, precision measures the relevance of each cluster,
while recall penalizes redundant clusters.
We first manually tagged each session with conjectures as shown in Figure 6. Conjectures identified sessions with known attack types and it is possible for a session to be marked with multiple conjectures. It is important to note that these conjectures were not used in clustering and served simply as evaluation aids to estimate the quality of our clusters.
The conjectures allow us to compute weighted precision (wp) and
weighted recall (wr) for our clustering. As sessions can be
tagged with multiple conjectures, we weight the measurements based
upon the total number of conjectures at a given cluster of
sessions. We compute the values ![]() and
and ![]() as follows: Let
as follows: Let ![]() be
the set of all clusters,
be
the set of all clusters, ![]() be the set of all possible conjectures,
and
be the set of all possible conjectures,
and ![]() be the set of elements in cluster
be the set of elements in cluster ![]() labeled with
conjecture
labeled with
conjecture ![]() . Then
. Then ![]() is the count of the number of elements
in cluster
is the count of the number of elements
in cluster ![]() with conjecture
with conjecture ![]() .
.
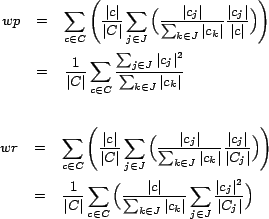
In the formulas above,
![]() and
and
![]() as sessions may have multiple
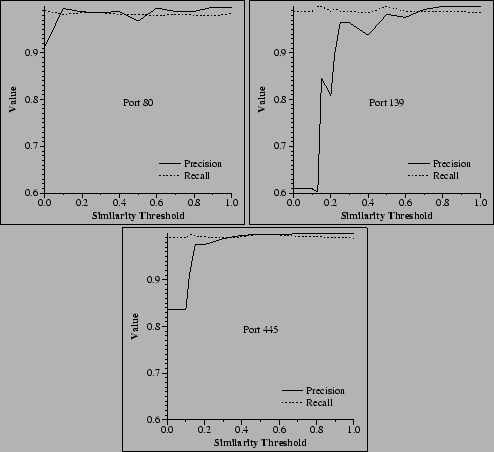
conjectures. Figure 7 presents graphs indicating how
precision and recall vary with the clustering similarity
threshold. Recall that in the star clustering algorithm, an edge is
added between two sessions in the graph of all sessions only if their
similarity is above the threshold. Although less true for NetBIOS data, the similarity threshold does not
have a significant impact on the quality of the resulting clustering.
Clustering precision drops as the threshold nears 0 because the star
graph becomes nearly fully connected and the algorithm cannot select
suitable cluster centers. Recall that no cluster centers can share an
edge, so many different clusters merge together at low threshold
values. At the clustering threshold used
in our experiments (0.8), precision scores were perfect or nearly
perfect.
as sessions may have multiple
conjectures. Figure 7 presents graphs indicating how
precision and recall vary with the clustering similarity
threshold. Recall that in the star clustering algorithm, an edge is
added between two sessions in the graph of all sessions only if their
similarity is above the threshold. Although less true for NetBIOS data, the similarity threshold does not
have a significant impact on the quality of the resulting clustering.
Clustering precision drops as the threshold nears 0 because the star
graph becomes nearly fully connected and the algorithm cannot select
suitable cluster centers. Recall that no cluster centers can share an
edge, so many different clusters merge together at low threshold
values. At the clustering threshold used
in our experiments (0.8), precision scores were perfect or nearly
perfect.
|
 |
Intrusion detection signatures should satisfy two basic properties. First, they should have a high detection rate; i.e., they should not miss real attacks. Second, they should generate few false alarms. Our results will show that Nemean has a 99.9% detection rate with 0 false alarms. Two additional metrics evaluate the quality of the alarms raised by an IDS. Precision empirically evaluates alarms by their specificity to the attack producing the alarm. Noise level counts the number of alarms per incident and penalizes redundant alarms. In these tests, we use Snort as a baseline for comparison simply because that is the most widely adopted intrusion detection system. We used the latest version of Snort available at the time, Snort-2.1.0 with the HTTP pre-processor enabled, and its complete associated ruleset. In some sense, Snort is the strawman because of its well-known susceptibility to false-positives. We use this because of our inability to compare with Honeycomb (see Section 7.4) and because there is no source code publicly available for Earlybird or Autograph [10,27].
![]() 99.9% Detection Rate:
We evaluated the detection rate of Nemean signatures using leave-out testing, a common technique in machine learning. We used
the honeynet data set described in Table 2 to
automatically create connection-level and session-level signatures
for the clusters identified in a training data set. We measured the
detection rate of the signatures by running signature matching against
data in a different trace collected from the same network (see
Table 2).
99.9% Detection Rate:
We evaluated the detection rate of Nemean signatures using leave-out testing, a common technique in machine learning. We used
the honeynet data set described in Table 2 to
automatically create connection-level and session-level signatures
for the clusters identified in a training data set. We measured the
detection rate of the signatures by running signature matching against
data in a different trace collected from the same network (see
Table 2).
Connection-level HTTP signatures detected 100.0% of the attacks present, and the somewhat more restrictive session-level signatures detected 97.7%. We did not evaluate session-level signatures for Nimda because the extreme variability of Nimda attacks made such signatures inappropriate. Table 3 shows the number of occurrences of the HTTP attacks and the number detected by Nemean signatures. For comparison, we provide detection counts for Snort running with an up-to-date signature set. Snort detected 99.7% of the attacks.
The detection rate of NetBIOS attacks is similarly very high: we detected 100.0% of the attacks present. Table 4 contains the detection rates for NetBIOS/SMB signatures. Snort provides only limited detection capability for NetBIOS attacks, so a comparison was infeasible. All signatures were connection-level because the defining characteristic of each attack is a string contained in a single connection. The structure of connections within a session is irrelevant for such attacks.
![]() Zero misdiagnoses or false alarms: We qualify incorrect alerts on the honeynet data as misdiagnoses.
Although not shown in Table 3, all Nemean
HTTP signatures generated 0 misdiagnoses on the honeynet
trace. Misdiagnosis counts for NetBIOS/SMB on the honeynet data were
also 0, as shown in Table 4. We also measured
false alarm counts of Nemean HTTP signatures against 16GB of
packet-level traces collected from our department's border router over
an 8 hour time period. The traces contained both inbound and outbound
HTTP traffic. We evaluated both Nemean and Snort against the
dataset.
Zero misdiagnoses or false alarms: We qualify incorrect alerts on the honeynet data as misdiagnoses.
Although not shown in Table 3, all Nemean
HTTP signatures generated 0 misdiagnoses on the honeynet
trace. Misdiagnosis counts for NetBIOS/SMB on the honeynet data were
also 0, as shown in Table 4. We also measured
false alarm counts of Nemean HTTP signatures against 16GB of
packet-level traces collected from our department's border router over
an 8 hour time period. The traces contained both inbound and outbound
HTTP traffic. We evaluated both Nemean and Snort against the
dataset.
Nemean results are highly encouraging: 0 false alarms. Snort generated 88,000 alarms on this dataset, almost all of which were false alarms. The Snort false alarms were produced by a collection of overly general signatures. In fairness, we note that Snort had a larger signature set which made it more prone to false positives. Our Snort signature set included about 2200 signatures, whereas Nemean's database of HTTP and NetBIOS signatures contained only 22 connection-level and 7 session-level signatures. Snort has a high signature count because it is meant to detect classes of attacks beyond those seen by Honeynets.
Table 5 provides a summary of the Snort alarms generated on an 8 hour trace of overwhelmingly benign HTTP traffic collected at our department's border router. Reducing Snort's alarm rate would require reengineering of many signatures. Additionally, the overly general signature provides little specific information about the type of exploit that may be occurring.
We assume that in a real network deployment of Snort the most noisy signatures such as those in Table 5 would be disabled. A more reasonable estimate of the expected false alarm rates might be obtained from the remaining alerts shown in Table 6. The remaining alerts come from 60 signatures and are responsible for 1643 alerts (excluding Others). While we did not inspect each of these individually for true positives due to privacy concerns with the dataset, sampling revealed that they are mostly false alarms. Traffic classified as Others were legitimate alerts fired on benign P2P traffic and traffic from web crawlers.
Our university filters NetBIOS traffic at the campus border, so we were unable to obtain NetBIOS data for this experiment.
![]() Highly specific alarms:
Although the decision is ultimately subjective, we believe our
signatures generate alerts that are empirically better than alerts
produced by packet-level systems such as Snort. Typical Snort alerts, such as ``Bare Byte Unicode Encoding'' and
``Non-RFC HTTP Delimiter'', are not highly revealing. They report the
underlying symptom that triggered an alert but not the high-level
reason that the symptom was present.
This is particularly a problem for NetBIOS alerts
because all popular worms and viruses generate virtually the same set of
alerts. We call these weak alerts and describe them in more
detail in the technical report [35].
Nemean, via connection-level or
session-level signatures, has a larger perspective of a host's intentions.
As a result, we generate alerts specific to particular worms
or known exploits.
Highly specific alarms:
Although the decision is ultimately subjective, we believe our
signatures generate alerts that are empirically better than alerts
produced by packet-level systems such as Snort. Typical Snort alerts, such as ``Bare Byte Unicode Encoding'' and
``Non-RFC HTTP Delimiter'', are not highly revealing. They report the
underlying symptom that triggered an alert but not the high-level
reason that the symptom was present.
This is particularly a problem for NetBIOS alerts
because all popular worms and viruses generate virtually the same set of
alerts. We call these weak alerts and describe them in more
detail in the technical report [35].
Nemean, via connection-level or
session-level signatures, has a larger perspective of a host's intentions.
As a result, we generate alerts specific to particular worms
or known exploits.
![]() Low noise due to session-level signatures:
Moreover, Nemean provides better control over the level of noise in its
alarms. Packet-level detection systems such as Snort often raise alerts
for each of multiple packets comprising an attack. A security administrator
will see a flurry of alerts all corresponding to the same incident.
For example, a Nimda attack containing an encoded
URL will generate URL decoding alarms in Snort and alerts for WEB-IIS
cmd.exe access. Sophisticated
URL decoding attacks could later get misdiagnosed as Nimda alerts and
be filtered
by administrators. Our normalizer converts the URL to a canonical
form to accurately detect Nimda attacks. Since Nemean aggregates
information into connections or sessions and generates alerts only on
the aggregated data, the number of alerts per incident is reduced.
Low noise due to session-level signatures:
Moreover, Nemean provides better control over the level of noise in its
alarms. Packet-level detection systems such as Snort often raise alerts
for each of multiple packets comprising an attack. A security administrator
will see a flurry of alerts all corresponding to the same incident.
For example, a Nimda attack containing an encoded
URL will generate URL decoding alarms in Snort and alerts for WEB-IIS
cmd.exe access. Sophisticated
URL decoding attacks could later get misdiagnosed as Nimda alerts and
be filtered
by administrators. Our normalizer converts the URL to a canonical
form to accurately detect Nimda attacks. Since Nemean aggregates
information into connections or sessions and generates alerts only on
the aggregated data, the number of alerts per incident is reduced.
In summation, we believe these results demonstrate the strength of Nemean. It achieves detection rates similar to Snort with dramatically fewer false alarms. The alerts produced by Nemean exhibit high quality, specifying the particular attack detected and keeping detection noise small.
|
Although our current implementation operates offline on collected data sets, we intend for Nemean to be used in online signature generation. Online systems must be efficient, both so that new signatures can be rapidly constructed as new attacks begin to appear and so that the system can operate at network speeds with low computational demands. Figure 8 shows Nemean's overheads on the 2-day training data set containing about 200,000 HTTP packets and 2,000,000 NetBIOS packets. Total data processing time is divided into the three stages of data abstraction, clustering, and automaton generalization plus an additional preprocessing step that translated SSTs produced by the DAL into the input format of our clustering module. The HTTP connection-level automaton generalization step used the sk-strings algorithm. The session-level generalization used beam search, with nearly 100% of the cost arising from one cluster of Nimda sessions. At 200,000 packets, the cost of session-level generalization was 587 seconds. NetBIOS signature generalization used simulated beam annealing at the connection-level only, with no construction of session-level signatures.
Nemean is efficient. We are able to generate signatures for 2 days worth of NetBIOS data, totaling almost 2 million packets, in under 70 seconds. Even our most expensive operation, session-level generalization of HTTP data, required less than 10 minutes of computation. The design of our system helps keep costs low. By processing only data collected on a honeynet, the overall volume of data is significantly reduced. Deploying Nemean as an online signature generator would require limited system resources and can easily operate at the speeds of incoming data.
Honeycomb was one of the first efforts to address the problem of automatic signature generation from honeypot traces. We performed a comparison between Nemean and Honeycomb on identical traces as a means to further understand the benefits of semantics awareness in automated signature generators. This evaluation was complicated by two issues: first, we transformed Honeycomb's Honeyd plug-in implementation into a standalone application by feeding it the input traffic from a pcap loop. Second, since Honeycomb was developed as a proof-of-concept tool, it turned out to be incapable of processing large traces7. In our experience, Honeycomb's processing time grows quadratically with each connection since it performs pairwise comparison across all connections, and running it on a relatively small trace of 3000 packets took several hours on a high performance workstation. As a result, our evaluation is a qualitative comparison of Honeycomb signatures and its performance on a small trace with 126 HTTP connections.
|
Honeycomb produced 202 signatures from the input trace. While there were several perfectly functional signatures, there were also a surprisingly large number of benign strings that were identified by the LCS algorithm. Some of these were small strings such as ``GET'' or ``HTTP'' that are clearly impractical and just happened to be the longest common substring between unrelated sessions. Communication with the Honeycomb author revealed these were part of normal operation and the typical way to suppress these are to whitelist signatures smaller than a certain length. There were also much longer strings in the signature set, such as proxy-headers that also do not represent real attack signatures. It seems that the only way to avoid these kinds of problems is through manual grooming of signatures by an expert with protocol knowledge. It should be noted that while Nemean also requires a sanity check process, this affects Honeycomb to a much greater extent because of it tendency to generate a large number of signatures.
The summary of the comparison of signatures produced by Honeycomb versus those produced by Nemean is as follows:
We present examples of signatures that we obtained from Honeycomb that demonstrate these weaknesses in Table 7.
A potential vulnerability of Nemean is its use of honeynets as a data source. If attackers become aware of this, they could either attempt to evade the monitor or to pollute it with irrelevant traffic resulting in many unnecessary signatures. Evasion can be complicated by periodic rotation of the monitored address space. Intentional pollution is a problem for any automated signature generation method and we intend to address it in future work.
Three issues may arise when deploying Nemean on a live network. First, live networks have real traffic, so we cannot assume that all observed sessions are malicious. To produce signatures from live traffic traces containing mixed malicious and normal traffic, we must first separate the normal traffic from the malicious. Flow-level anomaly detection or packet prevalence techniques [27] could help to identify anomalous flows in the complete traffic traces. Simple techniques that flag sources that horizontally sweep the address space, vertically scan several ports on a machine, and count the number of rejected connection attempts could also be used.
Second, Nemean must generate meaningful signatures for Snort, Bro, or other NIDS. Snort utilizes an HTTP preprocessor to detect HTTP attacks and does not provide support for regular expressions. Converting Nemean signatures to Bro signatures is straightforward since Bro allows for creation of policy scripts that support regular expressions.
Third, while it is not the focus of the current implementation, the limited manual selection required suggests that automating deployment of Nemean signatures should be realizable. This resiliency of Nemean signatures to false positives makes it quite attractive as a means to automate defense against flash worms that propagate rapidly. The data abstraction component's modules work without any changes on live traces. The star clustering algorithm is also designed to perform incremental clustering and work in an online fashion. Anomaly detection techniques could be employed in parallel with Nemean to flag compelling clusters for worm outbreaks. Automatically generated Nemean signatures for these clusters could then be rapidly propagated to NIDS to defend against emergent worms.
We have described the design and implementation of Nemean, a system for automated generation of balanced NIDS signatures. One of the primary objectives of this system is to reduce false alarm rates by creating signatures that are semantics aware. Nemean's architecture is comprised of two major components: the data-abstraction component and the signature-generation component. This modular design supports and encourages independent enhancement of each piece of the architecture. Nemean uses packet traces collected at honeynets as input since they provide an unfettered view of a wide range of attack traffic.
We evaluated a prototype implementation of Nemean using data collected at two unused /19 subnets. We collected packet traces for two services for which we developed service normalizers (HTTP and NetBIOS/SMB). Running Nemean over this data resulted in clusters for a wide variety of worms and other exploits. Our evaluation suggests that simple similarity metrics, such as the cosine metric, can provide clusters with a high degree of precision. We demonstrated the signature generation capability of our system and discussed optimizations used by our automata learning module, such as structure abstraction and subsequence creation. We showed that Nemean generated accurate signatures with extremely low false alarm rates for a wide range of attack types, including buffer overflows (Welchia), attacks with large diversity (Nimda), and attacks for complicated protocols like NetBIOS/SMB.
In future work, we intend to hone the on-line capabilities of Nemean and to assess its performance over longer periods of time in live deployments. We will also continue to evaluate methods for clustering and learning with the objective of fine tuning the resulting signature sets.
This work is supported in part by Army Research Office grant DAAD19-02-1-0304, Office of Naval Research grant N00014-01-1-0708, and National Science Foundation grant CNS-0347252. The first author was supported in part by a Lawrence H. Landweber NCR Graduate Fellowship in Distributed Systems. The second author was supported in part by a Cisco Systems Distinguished Graduate Fellowship.
The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes, notwithstanding any copyright notices affixed thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the above government agencies or the U.S. Government.
We thank CSL for providing us access to the traces, Dave Plonka, Geoff Horne, Bill Jensen and Michael Hare for support of iSink project. Finally, we would like to thank Vern Paxson, our shepherd Fabian Monrose and the anonymous reviewers whose insightful comments have greatly improved the presentation of the paper.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons paper.tex
The translation was initiated by Jonathon Giffin on 2005-05-12
|
This paper was originally published in the
Proceedings of the 14th USENIX Security Symposium,
July 31–August 5, 2005, Baltimore, MD Last changed: 3 Aug. 2005 ch |
|
![\includegraphics[width=\columnwidth]{figs/overhead80.eps}](img73.png)
![\includegraphics[width=\columnwidth]{figs/overhead445.eps}](img74.png)