| ||||||||||||||||||||||||||||||||||||||||||||||||||||
WIESS 2000 Paper
[WIESS Tech Program Index]
C++ Exception Handling for IA-64
Christophe de Dinechin AbstractThe C++ programming language offers a feature known as exception handling, which is used for instance to report error conditions. This technique can result in more robust software. On the other hand, it generally has a highly negative performance impact, including when exceptions are not actually thrown. This impact is especially important on an architecture such as the HP/Intel IA-64 processor, which is very sensitive to compiler optimizations. Hewlett-Packard implemented exception handling for IA-64 in a way that leaves the door open for optimizations, even in the presence of exceptions. Overview of C++ Exception Handling
Most software has to deal with exceptional conditions, such as
insufficient resources, missing file or invalid user input. In C, such
a condition is typically reported using special return codes from
functions. For instance, the ubiquitous void *ptr = malloc(1000000); if (ptr == NULL) fprintf(stderr, "Sorry, out of memory\n"); C++ exceptions are a better way to report such a condition. A C++ function that detects an exceptional situation can throw an exception , which can be caught by any of the calling functions using an exception handler. For instance, the previous code could be written in a C++ program as follows (the error test is in bold): struct OutOfMemory {};
struct Resource {
Resource(); // Ctor allocates resource
~Resource(); // Dtor frees resource
};
int foo(int size) {
void *ptr = malloc(size);
if (ptr == 0)
throw OutOfMemory();
/* Do something else */
}
int bar(int elements) {
Resource object;
int result = foo(2 * elements);
/* Do something else */
}
int main() {
int i;
try {
for (i = 0; i < 100; i++)
bar(i);
} catch (OutOfMemory) {
/* Report out-of-memory condition*/
cerr << "Out of memory for i="
<< i << endl;
} catch (...) {
/* Report other problems. */
}
}
If the anomalous situation is detected (in this case,
Throwing an exception involves unwinding the call stack until an exception handler is found. This process is made more complex in the presence of C++ automatic objects, since these objects may have destructors. In that case, destructors have to be called as the stack is being unwound. Performance Impact of Various SolutionsSince exceptions occur infrequently, the performance of exception handling code is normally not critical. In addition, developers can easly control how their application uses exceptions, and avoid exceptions in performance-critical code.
On the other hand, implementations of exception handling generally have a negative performance impact on the code that may throw an exception (the code inside a The performance of an exception-handling solution is therefore measured by its impact on the non-exceptional code when no exception is thrown; it should try to minimize the degradation of code speed and size for this "normal" code. Portable Exception Handling with setjmp
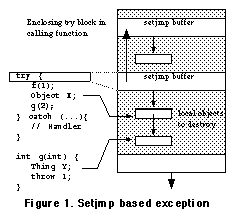
The first implementations of C++ exception handling used a mechanism based on the standard C
In "portable" exception handling, a try block is replaced with a
The major difficulty with this approach is to correctly destroy automatic objects (such as the
On the other hand, the performance drawbacks are significant.
This impact exists even if no exception is ever thrown, since the
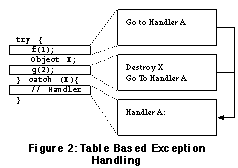
calls to Table-Driven Exception HandlingAnother implementation of C++ exception handling uses tables generated by the compiler along with the machine code. When an exception is thrown, the C++ runtime library uses the tables to perform the appropriate actions. Conceptually, this process works as follows:
This approach is significantly more efficient than the previous
one. There is no longer the systematic cost of a On the other hand, there are still negative effects from a performance point of view:
Extension of Variable LifetimeThe following code illustrates a first problem related to keeping the value of local variables in the presence of exception handling: void f() {
int x = 0;
x = f1(x);
f2(x);
}
A smart compiler can discover that the only use of the initial value of void f() {
int x = f1(0);
f2(x);
}
However, if the above code were to be placed in a try block, this transformation would no longer be valid. For instance, the value of void f() {
int x = 0;
try {
x = f1(x);
f2(x);
} catch (...) {
cout << "The value of x is " << x;
}
}
This phenomenon extends the lifetime of a variable, and therefore puts additional pressure on the register allocator. It also makes the control flow much more complex, by creating additional potential control-flow arcs between any call and each of the catch clauses. As a result, register usage will tend to be much more conservative within a try block than outside of it. On the other hand, these effects occurs only in the presence of a try block: destructors, for instance, cannot access local variables whose addresses have not been exposed. Register Selection ConstraintsAnother slightly different problem can be shown on the following code: int f(int x) {
x = f1(x);
return f2(x);
}
A smart compiler can notice that the initial value of int f(int x) {
int x2 = f1(x); // and discard x
int x3 = f2(x2); // and discard x2
return x3;
}
This alternative leaves much more freedom in terms of register allocation, since now different registers (or memory locations) can be allocated for Control-Flow Complexity
In the presence of a try block, the control flow becomes much more complex, since an implicit "goto" exists between any function call or for (i = 0; i < 1000; i++) x = f(i) * 3 + 1;
Outside of a try block, the code in question has a rather well known behavior, so if
Optimizing away the computation can't be done if there is a try block surrounding the code, since in that case any of the Memory Access Order
Memory accesses are more strictly ordered in the presence of exceptions. This effect is quite significant, because it occurs even without the presence of a struct Object { float x, y; ~Object(); };
Object object;
for (int i = 1; i < 1000; i++) {
object.x += f(i);
object.y += g(i);
}
In this code, the compiler can identify that for a normal iteration of the loop, memory accesses can be avoided, and replace the loop code with something like: register float tmp_x = object.x;
register float tmp_y = object.y;
for (int i = 0; i < 1000; i++) {
tmp_x += f(i);
tmp_y += g(i);
}
object.x = tmp_x;
object.y = tmp_y;
Of course, if In practice, this last effect and its variants tends to be the most significant, since it affects memory accesses, which are expensive on today's microprocessors, and it occurs whenever exceptions are enabled, regardless of whether there are exception-related constructs in the code. IA-64 Exception HandlingThe various problems listed previously can be classified in one of the two following categories:
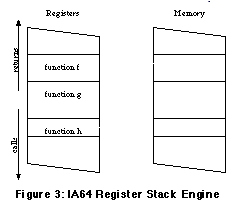
The first problem is addressed in a rather original way by a feature of the IA-64 architecture called the " Register Stack Engine " (RSE) See IA-64 Register Stack Engine. . The RSE defines a standard way to save and restore registers when entering and exiting functions which is not directly under program control. As a result there is no real need to explicitly save registers, yet there is a way for the runtime to restore them to their original value. The second problem is addressed in our implementation of C++ exception handling by allowing the non-exceptional path to be optimized, as long as compensation code is placed along the exceptional paths to restore program state before executing the exception handlers to what it would have been if the optimization had not taken place. The place where such compensation code is added is called a landing pad , and serves as an alternate return path for each call. Register Stack Engine and Unwind TableThe IA-64 architecture features numerous registers See IA-64 Instruction Set Architecture Guide. . The integer register set is partitioned into 32 fixed registers and 96 stacked registers. The stacked registers are automatically saved on a special stack, using free cycles in the load-store unit whenever possible.
Registers are typically not stored to memory immediately on function entry. Instead, stacked registers are renamed so that the first stacked register for the current procedure is always called This technique maximizes the chances that a function call or function return can be performed without memory accesses to save or restore registers.
The Register Stack Engine which performs these operations is itself a very complex topic that would require an article in its own right See IA-64 Register Stack Engine. . For C++ exception handling, however, the key feature of the RSE is the way it transparently saves and restores stacked registers "in the background", and does so at locations onto the stack that the runtime can compute. When an exception is thrown, the runtime forces the RSE to flush all stacked registers on the stack. It can then manipulate them as needed, and later let the RSE restore them as the stack is unwound. Only stacked registers are saved this way. The IA-64 runtime architecture See IA-64 Software Conventions and Runtime Architecture. indicates that non-stacked registers are saved in stacked registers. Floating-point registers are saved using more traditional mechanism. The information indicating where each particular register is being saved is stored in separate tables, called unwind tables See Stack Unwinding and Exception Handling. . Together, the unwind tables, stack unwinding routines See C++ ABI for IA-64: Exception Handling. and the RSE help restore register values to the exact same state they were in any given function, without the runtime cost of saving them "manually" in each function. Exception Handling TablesRestoring registers to their previous state is necessary, but not sufficient for throwing a C++ exception. The C++ runtime also needs to call the destructors, to find the appropriate exception handler, and to transfer control to this exception handler. The information required to do this is found in exception handling tables . These tables are C++ specific. They contain information to map call sites to the landing pads. Each landing pad will process any exception thrown from the corresponding call site, and serve as an alternate return point for this call. The table also contains information regarding which exceptions the landing pad can process and catch, and records exception specifications if any.
The reason the table maps call sites is that our C++ implementation only throws from a call site. The
Therefore, from a machine language point of view, the only places that can throw are call instructions. If the program counter is within the range of a given subroutine but no call site matches, the runtime will call the
An interesting implication: this mechanism does not allow C++ exceptions to be thrown out of a Unix signal handler, something that the ISO C++ Standard specifically discourages
See ISO 14882: C++ Programming Language.
(Clause 18.7, paragraph 5, restricts signal handlers to what can also be written in plain C). For instance, if a memory access instruction causes a signal, and if the signal handler throws an exception, the program counter of the function containing the memory access will not be on a call instruction, and Landing PadsThe runtime transfers control to a landing pad whenever an exception is thrown from a given call site. The landing pad will contain code in the following order:
The same mechanism can deal with all kind of destructors (inlined or not, array destructors, ...), which all had to be special table entries in a table-driven exception handling runtime. A catch-all exception handler ( Together, the landing pads form a funnel where the compensation code can be somewhat different for each call site, while destructor code is shared for sections of code between declarations, and the exception switch and landing pad exit are shared for all code within the same try block. Compensation CodeIt is relatively easy for the compiler to generate compensation code for any of the operations listed in previous sections:
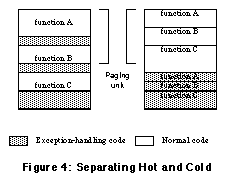
Compensation code therefore allows the compiler to utilize any of the optimizations that were prevented by simpler table-driven techniques. Since the IA-64 architecture is very sensitive to optimizations, the ability to insert compensation code alone is a compelling reason for selecting a landing pad based approach. On other architectures, the benefit of landing pads may not be high enough to compensate for the code size penalty compared to other table-driven techniques. Placing Landing Pad in "Cold" CodeLanding pad code is not used except when an exception is thrown. If the landing pad code is simply placed at the end of the code for each function, the useful code becomes interspersed with blocks of little-used code. This can affect paging and caching performance, since the exception handler code will occupy space in the various memory caches and in the virtual memory active set. For this reason, landing pad code can be placed in a different code section. This code can be placed at link time arbitrarily far from normal "hot" code. The hot code can then be kept contiguous and makes better use of the cache and virtual memory pages.
Even when it does not actually use cache lines or virtual memory active pages, landing pad wastes space on disk when it is not used. Since it is in general infrequently used, landing pad code can therefore be space optimized rather than speed optimized. Compressing TablesThe overhead of exception handling includes the exception handling tables. These tables are not used except when an exception is thrown. Just like landing pad code, they can be placed arbitrarily far from the code so as to minimize impact on caching and virtual memory. On the other hand, they still use valuable disk space in the executable image. The exception handling tables in the Hewlett-Packard aC++ compiler use a compression scheme known as "LEB128". This encoding uses less space for small values: 1 byte for any value less than 128, 2 bytes for any value less than 16384 and so on. So the tables contain relative offsets that are often small. For instance, the first call site address is encoded as the number of 16-byte instruction bundles from the start of the function, and later call sites are relative to the previous call site in the table. This helps keep the offsets small enough to fit in one or (rarely) two bytes. Compressing the tables has a slight negative effect when an exception is actually thrown, since the table contents need to be decoded. In that infrequently executed case, we traded speed for space. Known Functions That Can't ThrowWhen exceptions are enabled, there is a landing pad and table space overhead for each call site. This overhead can be avoided for specific functions that are known not to throw. These functions typically include:
If such a call ever throws, the C++ runtime will call Remaining Negative EffectsEven with landing pads, exception handling still has a cost. The space overhead of enabling exception handling includes the code for the landing pads, exception switches, destructor calls and catch handlers, as well as the space for all the exception handling tables. This remains significant in terms of memory usage, even though the performance impact of this additional memory can be kept low by carefully segregating hot and cold memory. However, performance itself can remain affected by a variety of factors:
ResultsThe following tables records timing and size measurements done on various benchmarks. These have been run on a performance simulator for the next generation IA-64 processor, and remain to be validated on real hardware. For comparison purposes, similar meaurements have been done on current generation PA-RISC processors. Only relative results are shown, since absolute SPEC results for IA-64 have not been published yet.
The values measure the performance penalty when enabling exception handling. For speed, the penalty is the additional number of cycles in the simulator. For memory, it is the additional size of text and initialized data, as reported by the These benchmarks contain a mix of C and C++ application code, but they often do not rely very much on C++ local objects or exception handling. Therefore, they represent a worst case but not very uncommon scenario where exception handling is not used and therefore you don't want to pay for it. Some of the benchmarks were originally written in C and have been modified to be compilable with a C++ compiler. This first table records size and speed penalties at the maximum optimization level, except for the last two rows. Suprisingly, in some benchmarks, enabling exception handling actually yields better performance. This has to be taken with a grain of salt. At this point, it is quite difficult to do accurate IA-64 measurements, whether on real hardware or on a simulator. For instance, simulator results are sampled, and the sampling noise alone can account for a few percents of variation either way. Similarly, optimizer "luck" in scheduling instructions can also introduce unpredictable variations. Therefore, the "noise level" of these measurements is quite high. You should not expect code to become faster because of exception handling. The size aspect is even more surprising. Processing exceptions requires additional code. The effect above on the IA-64 compiler shows only for the maximum optimization level (+O3), and may actually indicate a problem with the tested compiler. At lower optimization levels, the PA-RISC compiler consistently produces executables of the same size with or without +noeh. The IA-64 compiler produces executables that are significantly larger with exception handling enabled, which is what one would expect. AnalysisOverall, the objective of minimizing the negative runtime performance impact at high optimization levels is achieved. This constrasts with PA-RISC, where penalties as high as 15% are observed (and in practice 10% is not uncommon). It remains to be seen if this conclusion remains valid as more aggressive optimizations are added to the IA-64 compiler. The size penalty on IA-64 tends to be higher, at least at optimization levels used during application development. This is due largely to cleanup code, which takes more space than the same information stored in PA-RISC action tables. As usual, there was a space versus time trade off, and this technology definitely favored speed. The added exception handling code is normally infrequently executed. Modern operating systems do not load code into memory until it is about to be executed. So most of the time, the additional code just consumes disk space, without necessarily increasing the memory footprint of the application. Disk space gets cheaper all the time, so the trade off was a reasonable one. This code size penalty may be reduced somewhat in the production compilers by a change in the C++ Application Binary Interface (ABI) See C++ ABI for IA-64: Exception Handling. that is not implemented in the tested compiler. This change reduces the size of a minimal landing pad from 32 bytes down to 16. The reason for the size reduction at maximum optimization has not been investigated yet. It may indicate a problem with the compiler, such as an optimization being accidentally turned off when exceptions are disabled. Exception handling may also prevent some code-expanding transformations that look less profitable, such as inlining and loop unrolling. It is unclear if these results will persist with a production compiler. In general, keep in mind that all measurements above were made with a largely prototype compiler, and in a simulator. As our understanding of optimization techniques specifically targetting the IA-64 architecture improve, the results may vary significantly. ConclusionLanding pads offer an interesting alternative to more traditional implementations of C++ Exception Handling. They leave more optimization freedom to the compiler. Many aggressive optimizations can now be performed equally well even in the presence of exception handling code, making applications that require exception handling faster. One the design objectives of C++ is that you don't pay for features that you don't use. This objective was not met with many exception handling implementations. The IA-64 implementation presented here is one more little step towards that goal. This design has been shared by Hewlett-Packard with other Unix vendors, and should hopefully become available on a variety of IA-64 platforms as part of the effort towards a common C++ Application Binary Interface for IA-64 on Unix See C++ ABI for IA-64: Exception Handling. . ReferencesA Portable Implementation of C++ Exception HandlingD. Cameron, P. Faust, D. Lenkov and M. Mehta, Proc. USENIX C++ Conference, August 1992. IA-64 Instruction Set Architecture Guide
Revision 1.0, Intel Corporation / Hewlett-Packard Company IA-64 Register Stack Engine
Chapter 9 of the
IA-64 Instruction Set Architecture Guide.
IA-64 Software Conventions and Runtime Architecture
Vers. 1.0, Hewlett-Packard Company Stack Unwinding and Exception HandlingChapter 11 of IA-64 Software Conventions and Runtime Architecture. . C++ ABI for IA-64: Exception Handling
Working document, C++ ABI Committee
1.
Typically, |
|
This paper was originally published by the USENIX Association in the
Proceedings of the First WIESS Workshop,
October 22, 2000, San Diego, California, USA
Last changed: 23 Jan. 2002 ml |
|