| Environment | Scale (VMs) | Experiments |
| EC2 production | 871 | Measuring heterogeneity |
| EC2 test cluster | 100-243 | Scheduler performance |
| Local testbed | 15 | Measuring heterogeneity, scheduler performance |
| EC2 production | 40 | Sensitivity analysis |
| Load Level | VMs | Write Perf (MB/s) | Std Dev |
| 1 VMs/host | 202 | 61.8 | 4.9 |
| 2 VMs/host | 264 | 56.5 | 10.0 |
| 3 VMs/host | 201 | 53.6 | 11.2 |
| 4 VMs/host | 140 | 46.4 | 11.9 |
| 5 VMs/host | 45 | 34.2 | 7.9 |
| 6 VMs/host | 12 | 25.4 | 2.5 |
| 7 VMs/host | 7 | 24.8 | 0.9 |
| Load Level | Hosts | VMs |
| 1 VMs/host | 40 | 40 |
| 2 VMs/host | 20 | 40 |
| 3 VMs/host | 15 | 45 |
| 4 VMs/host | 10 | 40 |
| 5 VMs/host | 8 | 40 |
| 6 VMs/host | 4 | 24 |
| 7 VMs/host | 2 | 14 |
| Total | 99 | 243 |
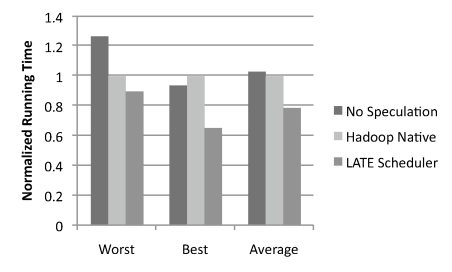
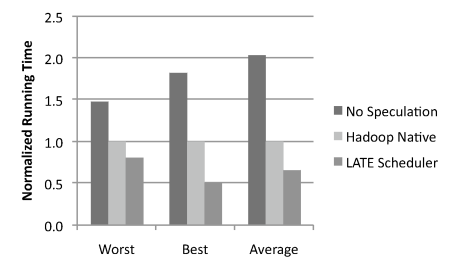
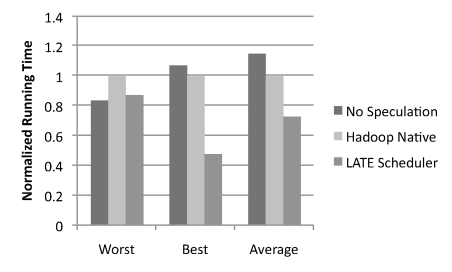
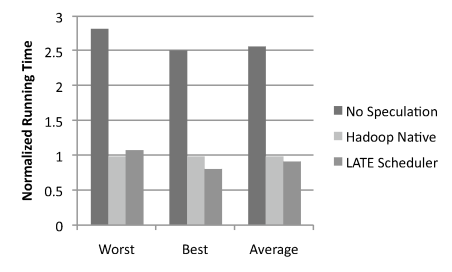
| Load Level | VMs | Write Perf (MB/s) | Std Dev |
| 1 VMs/host | 5 | 52.1 | 13.7 |
| 2 VMs/host | 6 | 20.9 | 2.7 |
| 4 VMs/host | 4 | 10.1 | 1.1 |
| Load Level | Hosts | VMs |
| 1 VMs/host | 5 | 5 |
| 2 VMs/host | 3 | 6 |
| 4 VMs/host | 1 | 4 |
| Total | 9 | 15 |