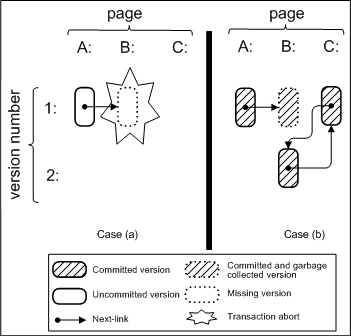
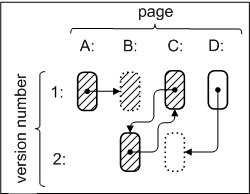
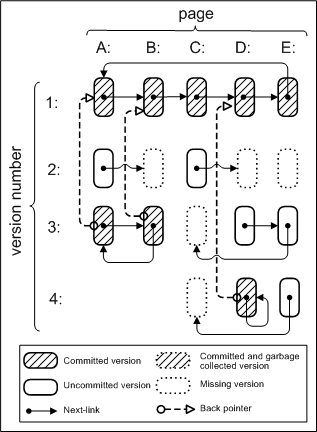
|
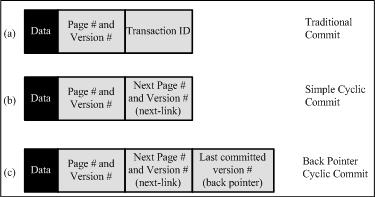
| TC | SCC | BPCC | |
| Metadata/page | 16 bytes | 24 bytes | 28 bytes |
| Space overhead | 1 commit/tx | None | None |
| Perf. overhead | 1 write/tx | None | None |
| Garbage collection | Simple | Simple | Complex |
| Recovery | Simple | Simple | Complex |
| Aborted transactions | Leave | Erase | Leave |
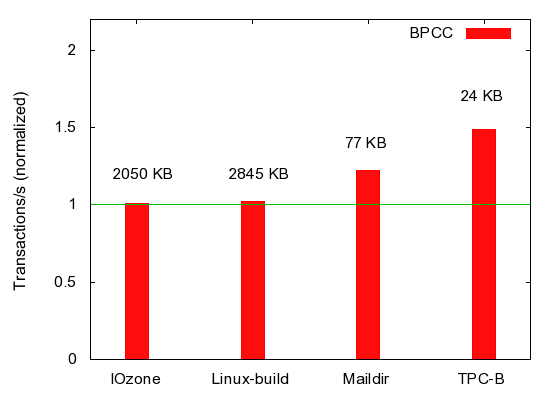
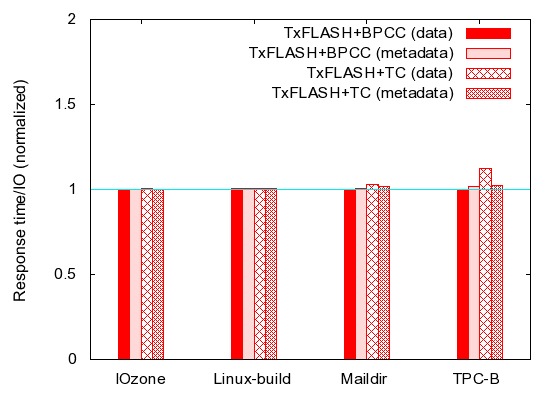
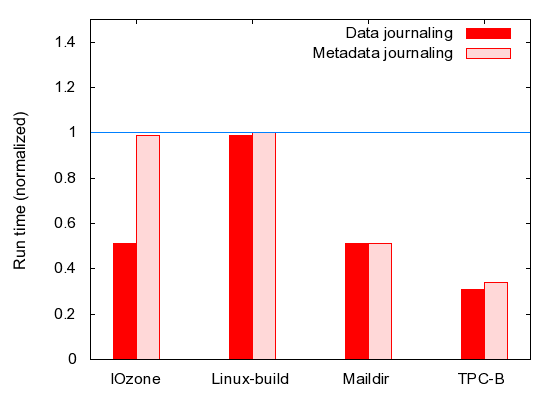
| IOzone | Linux-build | Maildir | TPC-B | |
| Space overhead | 0.23% | 0.15% | 7.29% | 57.8% |
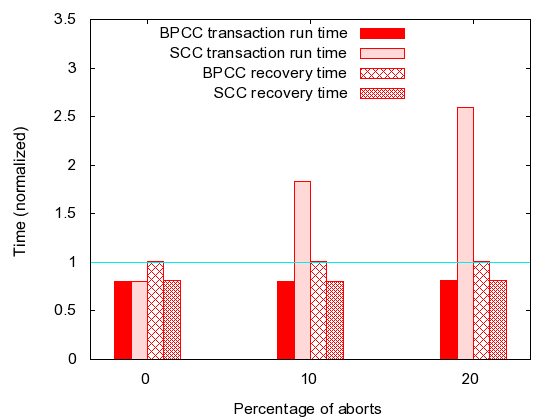
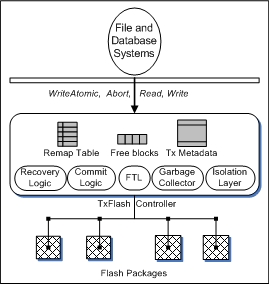
| TxFlash | ||||
| SSD | +TC | +SCC | +BPCC | |
| LOC | 7621 | 9094 | 9219 | 9495 |