
However, with respect to our goal of minimizing interference, this
congestion signal ![]() a packet loss
a packet loss ![]() arrives too late to avoid damaging
other flows. In particular, overflowing a buffer (or filling a RED
router enough to cause it to start dropping packets) may trigger
losses in other flows, forcing them to back off multiplicatively and
lose throughput.
arrives too late to avoid damaging
other flows. In particular, overflowing a buffer (or filling a RED
router enough to cause it to start dropping packets) may trigger
losses in other flows, forcing them to back off multiplicatively and
lose throughput.
In order to detect incipient congestion due to interference we monitor
round-trip delays of packets and use increasing round-trip delays as a
signal of congestion. In this respect, we draw inspiration from TCP
Vegas [7], a protocol that differs from TCP-Reno in its congestion
avoidance phase. By monitoring round-trip delays, each Vegas flow
tries to keep between ![]() (typically 1) and
(typically 1) and ![]() (typically 3)
packets buffered at the bottleneck router. If fewer than
(typically 3)
packets buffered at the bottleneck router. If fewer than ![]() packets are queued, Vegas increases the window by one per window of
data acknowledged. If more than
packets are queued, Vegas increases the window by one per window of
data acknowledged. If more than ![]() packets are queued, the
algorithm decreases the window by one per window of data
acknowledged. Vegas adjusts the window
packets are queued, the
algorithm decreases the window by one per window of data
acknowledged. Vegas adjusts the window ![]() once every round
as follows (
once every round
as follows (![]() is
the minimum value of all measured round-trip delays and
is
the minimum value of all measured round-trip delays and ![]() is the round-trip delay experienced by a distinguished packet in the
previous round):
is the round-trip delay experienced by a distinguished packet in the
previous round):
// Expected throughput
// Actual throughput
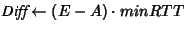
if ()
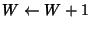
else if ()
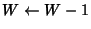
Bounding the difference between the actual and expected throughput
translates to maintaining between ![]() and
and ![]() packets in the
bottleneck router. Although Vegas seems a promising candidate protocol
for background flows, it has some drawbacks: (i) Vegas has been
designed to compete for throughput approximately fairly with Reno,
(ii) Vegas backs off when the number of queued packets from
its flow increases, but it does not necessarily back off when the
number of packets enqueued by other flows increase, (iii) each Vegas
flow tries to keep 1 to 3 packets in the bottleneck queue, hence a
collection of background flows could cause significant interference.
packets in the
bottleneck router. Although Vegas seems a promising candidate protocol
for background flows, it has some drawbacks: (i) Vegas has been
designed to compete for throughput approximately fairly with Reno,
(ii) Vegas backs off when the number of queued packets from
its flow increases, but it does not necessarily back off when the
number of packets enqueued by other flows increase, (iii) each Vegas
flow tries to keep 1 to 3 packets in the bottleneck queue, hence a
collection of background flows could cause significant interference.
Note that even setting ![]() and
and ![]() to very small values does
not prevent Vegas from interfering with cross traffic. The linear
decrease on the ``
to very small values does
not prevent Vegas from interfering with cross traffic. The linear
decrease on the ``
![]() '' trigger is not
responsive enough to keep from interfering with other flows. We
confirm this intuition using simulations and Internet experiments,
and it also follows as a conclusion from the theoretical analysis.
'' trigger is not
responsive enough to keep from interfering with other flows. We
confirm this intuition using simulations and Internet experiments,
and it also follows as a conclusion from the theoretical analysis.