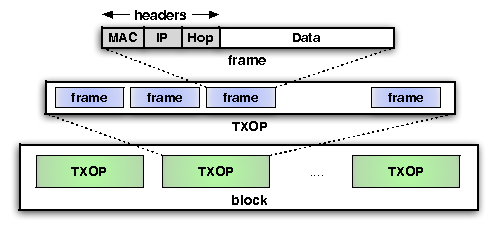
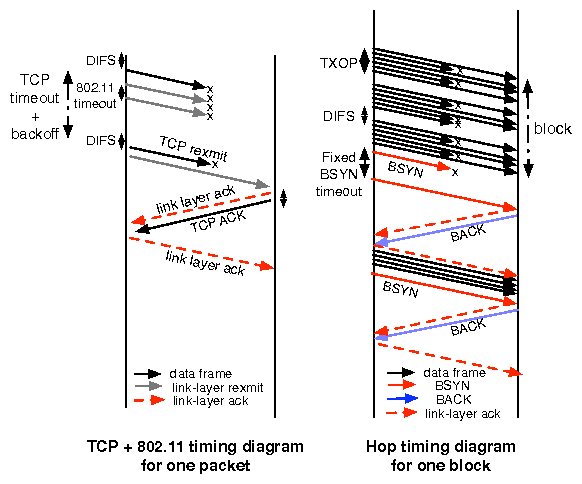
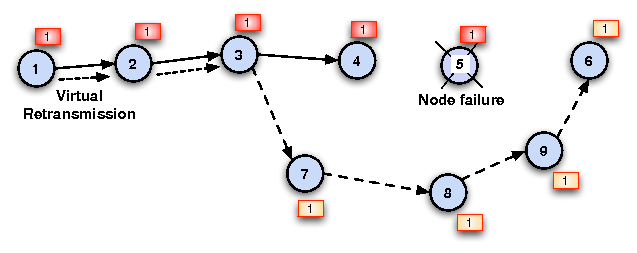
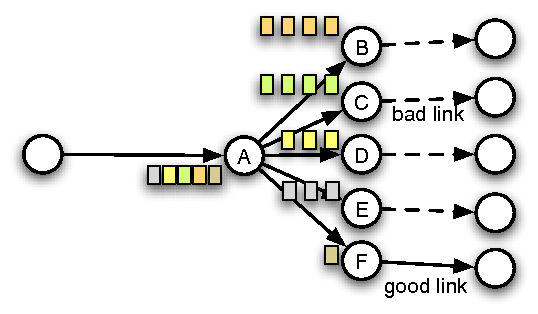
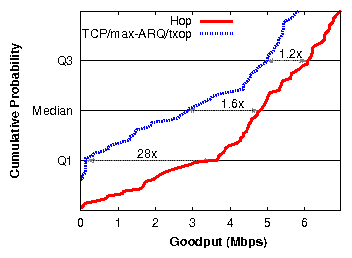
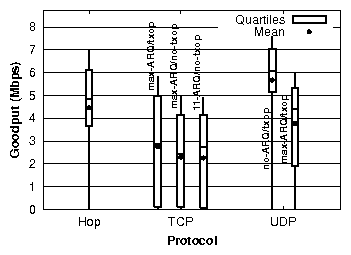
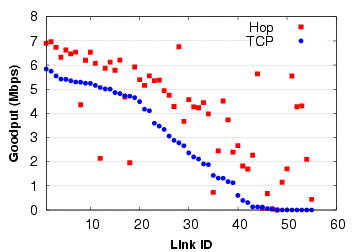
| Sec. | Experiment setup | Experiment | Result: Median (Mean) |
| § 5.1 | One single-hop flow | Hop vs. TCP | 1.6×
(1.6×) |
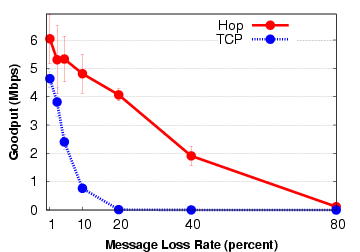
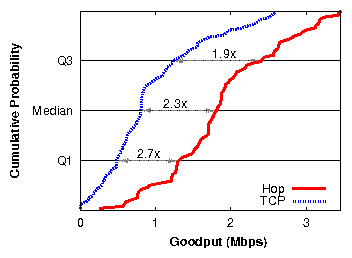
| § 5.2 | One multi-hop flow | Hop vs. TCP | 2.3× (2×) |
| Hop vs. Hop-by-Hop TCP | 2.5× (2×) |
| Hop vs. DTN2.5 | 2.9× (3.9×) |
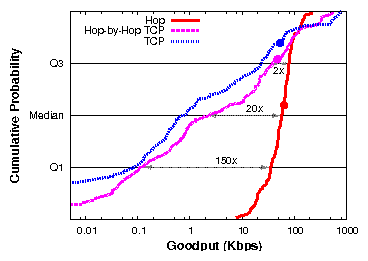
| § 5.3 | Many multi-hop flows | Hop vs. TCP | 90×
(1.25×) |
| Hop vs. Hop-by-Hop TCP | 20 × (1.4×) |
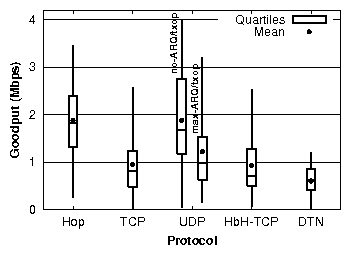
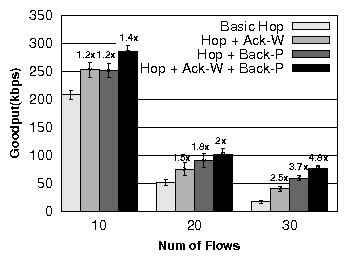
| § 5.4 | Performance breakdown | Base Hop | (1×) |
| +
ack withholding | (2.5×) |
| + backpressure | (3.7×) |
| + ack withholding + backpressure | (4.8×) |
| § 5.5 | WLAN AP mode | Hop vs. TCP | 2.7× (1.12×) |
| Hop vs. TCP + RTS/CTS | 2× (1.4×) |
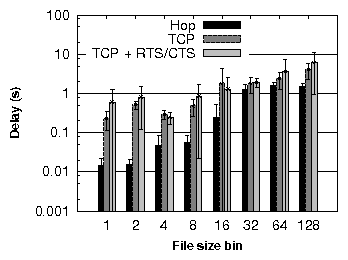
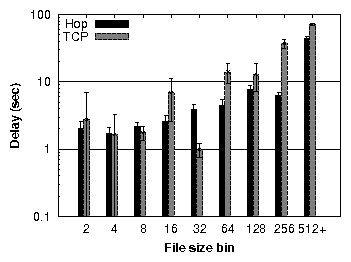
| § 5.6 | Single small file | Hop vs. TCP | 3× to
15× lower delay |
| Concurrent small files | Hop vs. TCP
| Comparable or lower delay |
| § 5.7 | Disruption-tolerance | Hop vs. DTN2.5 | 2.8×
(2.9×) |
| § 5.8 | Impact on VoIP traffic | Hop vs. TCP | Slightly lower
MOS score but significantly higher throughput |
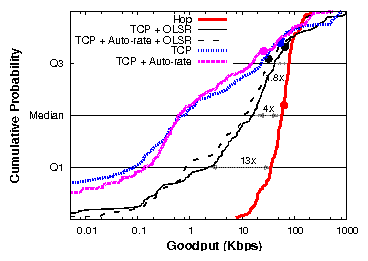
| § 5.9 | Network and link-layer dynamics | Hop vs. TCP + OLSR | 4×
(1×) |
| Hop vs. TCP + auto-rate | 95× (2.4×) |
| Hop vs. TCP + OLSR + auto-rate | 5× (1.8×) |
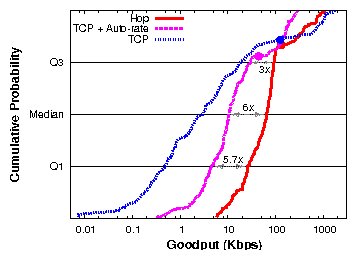
| § 5.10 | Under 802.11g | Hop vs. TCP | 22×
(1×) |
| Hop vs. TCP + auto-rate | 6×
(3×) |