| # | App. | Router | Problem | Cause | Fix |
|
| 1 | VPN | WGR614 | VPN Client does not connect | Stateful firewall was off | Turn on the stateful firewall |
| 2 | VPN | WRT54G | VPN drops connection after 3 minutes | (n/a) | Set MTU to 1350-1400, uncheck "block anonymous internet request", "filter multicast boxes" in router configuration |
| 3 | VPN | WRT54G | No VPN connectivity | No PPTP passthrough | turn on PPTP passhthrough |
| 4 | VPN | WRT54G | No VPN connectivity | double NAT, second NAT was dropping PPTP packets | Switch from PPTP server to SSTP server |
|
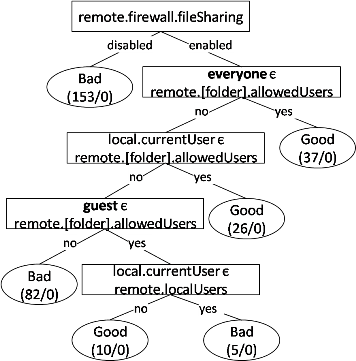
| 5 | File Sharing | any | Only unidirectional sharing | End-host firewall is not properly configured | Allow file sharing through all firewalls |
| 6 | File Sharing | WGR614v5 | No file sharing | Client machine is on a domain, server machine is on workgroup | Put both machines either on the same domain or workgroup |
|
| 7 | FTP | any | Cannot connect to FTP server from outside home network | Port forwarding incorrect | Turn on port forwarding on port 21 |
| 8 | FTP | WGR614 | Cannot connect to FTP server at home | Client firewall blocking traffic, active FTP being used | Turn on firewall rule to allow active FTP connections |
| 9 | VPN server | WRT54G | PPTP server behind NAT does not work despite port forwarding and PPTP passthrough allowed | IP of server is 192.168.1.109, which is inside default DHCP range of router; router's port forward to IPs inside default range of router does not work | Use static IP outside DHCP range for server |
|
| 10 | Outlook | WRT54G | Outlook does not connect via VPN to office | Default IP range of router was same as that of the remote router | Change the IP range of home router |
| 11 | Outlook | WGR614 | Router not able to email logs | SMTP server not configured properly | Setup SMTP server details in the router configuration |
| 12 | Outlook | Linksys | Not able to send mail through Linksys router; Belkin router works fine | MTU value too high for remote router, so remote router discards packets | Reduce MTU to 1458 or 1365 |
| 13 | SSH | WGR614 | SSH client times out after 10 minutes | NAT table entry times out | Change router or increase NAT table timeout |
| 14 | Office Communicator | WRTP54G | IM client does not connect to office | DNS requests not resolved | Turn off DNS proxy on router |
|
| 15 | STEAM games | WGR614 | Listing game servers causes connection drops | Router misinterprets the sudden influx of data as an attack and drops connection | Upgrade to latest firmware |
| 16 | Real-Player | BEFW11s4 | Streaming kills router | Firmware upgrade caused problems | Downgrade to previous firmware |
|
| 17 | Xbox | WRT54G | Xbox does not connect and all games do not run | Some ports are blocked and NAT traversal is restricted | Set static IP address on Xbox and configure it as DMZ, enable port forwarding on UDP 88,TCP 3074 and UDP 3074, disable UPnP to open NAT |
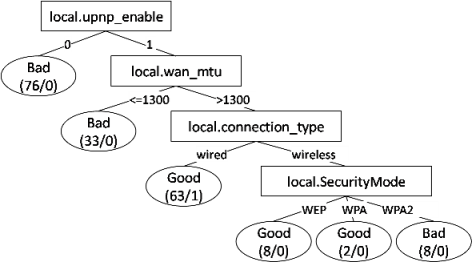
| 18 | Xbox | WRT54G | Xbox works with wired network but not with wireless | WPA2 security is not supported | Change wireless security feature from WPA2 to WPA personal security |
| 19 | Xbox | WGR614 | Not able to host Halo3 games | NAT settings too strict | Set Xbox as DMZ |
| 20 | IP Camera | DG834GT | Camera disconnects periodically at midnight, router needs reboot | DHCP problem | Configure static IP on the camera |
| 21 | ROKU | DIR-655 | ROKU did not work with mixed b, g and n wireless modes | (n/a) | Change to mixed b and g mode |