
|
||||||||||||||
2. 2. 0. 1 Modifications to the Xen hypervisor.Our modified VMM maintains a TDF variable for each hosted VM. For our applications, we are concerned with the relative passage of time rather than the absolute value of real time; in particular, we allow--indeed, require--that the host's view of wall clock time diverge from reality. Thus the TDF divides both real and wall clock time. We modify two aspects of the Xen hypervisor. First we extend the shared data structure to include the TDF field. Our modified Xen tools, such as xm, allow specifying a positive, integral value for the TDF on VM creation. When the hypervisor updates the shared data structure, it uses this TDF value to modify real and wall clock time. In this way, real time is never exposed to the guest OS through the shared data structure. Dilation also impacts the frequency of timer interrupts delivered to the VM. The VMM controls the frequency of timer interrupts delivered to an undilated VM (timer interrupts/second); in most OS's a HZ variable, set at compile time, defines the number of timer interrupts delivered per second. For transparency, we need to maintain the invariant that HZ accurately reflects the number of timer interrupts delivered to the VM during a second of dilated time. Without adjusting timer interrupt frequency, the VMM will deliver TDF-times too many interrupts. For example, the VMM will deliver HZ interrupts in one physical time second, which will look to the dilated VMM as HZ/(second/TDF) = TDF*HZ. Instead, we reduce the number of interrupts a VM receives by a factor of TDF (as illustrated earlier in Figure 1). Table 1 summarizes the discussion so far. Finally, Xen runs with a default HZ value of 100, and
configures guests with the same value. However,
2. 2. 0. 2 Modifications to XenoLinux.One goal of our implementation was to minimize required modifications to the guest OS. Because the VMM appropriately updates the shared data structure, one primary aspect of OS time-keeping is already addressed. We further modify the guest OS to read an appropriately scaled version of the hardware Time Stamp Counter (TSC). XenoLinux now reads the TDF from the shared data structure and adjusts the TSC value in the function get_offset_tsc. The Xen hypervisor also provides guest OS programmable alarm timers. Our last modification to the guest OS adjusts the programmable timer events. Because guests specify timeout values in their dilated time frames, we must scale the timeout value back to physical time. Otherwise they may set the timer for the wrong (possibly past) time. 2. 3 Time dilation on other platforms2. 3. 0. 1 Architectures:Our implementation should work on all platforms supported by Xen. One remark regarding transparency of time dilation to user applications on the x86 platform is in order: recall that we intercept calls to read the TSC within the guest kernel. However, since the RDTSC instruction is not a privileged x86 instruction, guest user applications might still issue assembly instructions to read the hardware TSC register. It is possible to work around this by watching the instruction stream emanating from a VM and trapping to the VMM on a RDTSC instruction, and then returning the appropriate value to the VM. However, this approach would go against Xen's paravirtualization philosophy. Fortunately, the current generation of x86-compatible hardware (such as the AMD Pacifica [ 6] and Intel VT [ 13]) provides native virtualization support, making it possible to make time dilation completely transparent to applications. For instance, both VT and Pacifica have hardware support for trapping the RDTSC instruction. 2. 3. 0. 2 VMMs:The only fundamental requirement from a VMM for supporting time dilation is that it have mechanisms to update/modify time perceived by a VM. As mentioned earlier, due to the difficulties in maintaining time within a VM, all VMMs already have similar mechanisms so that they can periodically bring the guest OS time in sync with real time. For instance, VMWare has explicit support for keeping VMs in a ``fictitious time frame'' that is at a constant offset from real time [ 27]. Thus, it should be straightforward to implement time dilation for other VMMs. 2. 3. 0. 3 Operating systems:Our current implementation provides dilation support for XenoLinux. Our experience so far and a preliminary inspection of the code for other guest OSes indicate that all of the guest OSes that Xen supports can be easily modified to support time dilation. It is important to note that modifying the guest OSes is not a fundamental requirement. Using binary rewriting, it would be possible to use unmodified guest OS executables. We expect that with better hardware and operating system support for virtualization, unmodified guests would be able to run under dilation.
2. 4 LimitationsThis section discusses some of the limitations of time dilation. One obvious limitation is time itself: a 10-second experiment would run for a 100 seconds for a dilation factor of 10. Real-life experiments running for hours are not uncommon, so the time required to run experiments at high TDFs is substantial. Below we discuss other, more subtle limitations. 2. 4. 1 Other devices and nonlinear scalingTime dilation uniformly scales the perceived performance of all system devices, including network bandwidth, perceived CPU processing power, and disk and memory I/O. Unfortunately, scaling all aspects of the physical world is unlikely to be useful: a researcher may wish to focus on scaling certain features (e.g., network bandwidth) while leaving others constant. Consequently, certain aspects of the physical world may need to be rescaled accordingly to achieve the desired effect. Consider TCP, a protocol that depends on observed round-trip times to correctly compute retransmission timeouts. These timing measurements must be made in the dilated time frame. Because time dilation uniformly scales the passage of time, it not only increases perceived bandwidth, it also decreases perceptions of round-trip time. Thus, a network with 10-ms physical RTT would appear to have 1-ms RTT to dilated TCP. Because TCP performance is sensitive to RTT, such a configuration is likely undesirable. To address this effect, we independently scale bandwidth and RTT by using network emulation [ 23, 26] to deliver appropriate bandwidth and latency values. In this example, we increase link delay by a factor of 10 to emulate the jump in bandwidth-delay product one expects from the bandwidth increase. In this paper, we show how to apply time dilation to extrapolate to future network environments, for instance with a factor of 10 or 100 additional bandwidth while accounting for variations in CPU power using the VMM scheduler. However, we do not currently account for the effects of increased I/O rates from memory and disk. Appropriately scaling disk performance is a research challenge in its own right. Disk performance depends on such factors as head and track-switch time, SCSI-bus overhead, controller overhead, and rotational latency. A simple starting point would be to vary disk performance assuming a linear scaling model, but this could potentially violate physical properties inherent in disk drive mechanics. Just as we introduced appropriate network delays to account for non-linear scaling of the network, accurate disk scaling would require modifying the virtual machine monitor to integrate a disk simulator modified to understand the dilated time frame. A well-validated disk simulator, such as DiskSim [ 8], could be used for this purpose. However, we leave dilating time for such devices to future work. Finally, hardware and software architectures may evolve in ways that time dilation cannot support. For instance, consider a future host architecture with TCP offload [ 20], where TCP processing largely takes place on the network interface rather than in the protocol stack running in the operating system. Our current implementation does not dilate time for firmware on network interfaces, and may not extend to other similar architectures. 2. 4. 2 Timer interruptsThe guest reads time values from Xen through a shared data structure. Xen updates this structure every time it delivers a timer interrupt to the guest. This happens on the following events: (1) when a domain is scheduled; (2) when the currently executing domain receives a periodic timer interrupt; and (3) when a guest-programmable timer expires. We argued earlier that, for successful dilation, the number of timer interrupts delivered to a guest should be scaled down by the TDF. Of these three cases, we can only control the second and the third. Our implementation does not change the scheduling pattern of the virtual machines for two reasons. First, we do not change the schedule pattern because scheduling parameters are usually global and system wide. Scaling these parameters on a per-domain basis would likely break the semantics of many scheduling schemes. Second, we would like to retain scheduling as an independent variable in our system, and therefore not constrain it by the choice of TDF. One might want to use round robin or borrowed virtual time [ 10] as the scheduling scheme, independent of the TDF. In practice, however, we find that not controlling timer scheduling does not impact our accuracy for all of the schedulers that currently ship with Xen. 2. 4. 3 Uniformity: Outside the dilation envelopeTime dilation cannot affect notions of time outside the dilation envelope. This is an important limitation; we should account for all packet processing or delays external to the VM. The intuition is that all stages of packet processing should be uniformly dilated. In particular, we scale the time a packet spends inside the VM (since it measures time in the dilated frame) and the time a packet spends over the network (by scaling up the time on the wire by TDF). However, we do not scale the time a packet spends inside the Xen hypervisor and Domain-0 (the privileged, management domain that hosts the actual device drivers), or the time it takes to process the packet at the other end of the connection. These unscaled components may affect the OS's interpretation
of round trip time. Consider the time interval between a packet
and its ACK across a link of latency
We are interested in the error relative to perfect dilation:
Note that
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(3a): Native Linux: link bandwidth 100 Mbps, link
delay 10 ms
![\includegraphics[width=3in]{figures/100Mbit-d10-l1-native-1.eps}](img19.png)
(3b): Xen VM (TDF 1): link bandwidth 100 Mbps,
link delay 10 ms
![\includegraphics[width=3in]{figures/100Mbit-d10-l1-t1-1.eps}](img20.png)
(3c): Xen VM (TDF 10): link bandwidth 10 Mbps,
link delay 100 ms
![\includegraphics[width=3in]{figures/10Mbit-d100-l1-t10-1.eps}](img21.png)
(3d): Xen VM (TDF 100): link bandwidth 1 Mbps,
link delay 1000 ms
![\includegraphics[width=3in]{figures/1Mbit-d1000-l1-t100-1.eps}](img22.png)
|
In this experiment, we first transfer data on TCP connections between two unmodified Linux hosts and use tcpdump [ 5] on the sending host to record packet behavior. We measure TCP behavior under both lossless and deterministic lossy conditions.
We then repeat the experiment with the sending host running with TDFs of {1, 10, 100}, spanning two orders of magnitude. When dilating time, we configure the underlying network such that a time-dilated host perceives the same network conditions as the original TCP experiment on unmodified hosts. For example, for the experiment with unmodified hosts, we set the bandwidth between the hosts to 100 Mbps and the delay to 10 ms. To preserve the same network conditions perceived by a host dilated by a factor of 10, we reduce the bandwidth to 10 Mbps and increase the delay to 100 ms using Dummynet. Thus, if we are successful, a time dilated host will see the same packet timing behavior as the unmodified case. We include results with TDF of 1 to compare TCP behavior in an unmodified host with the behavior of our system modified to support time dilation.
We show sets of four time sequence graphs in Figures 2 and 3. Each graph shows the packet-level timing behavior of TCP on four system configurations: unmodified Linux, and Linux running in Xen with our implementation of time dilation operating under TDFs of 1, 10, and 100. The first set of graphs shows the first second of a trace of TCP without loss. Each graph shows the data and ACK packet sequences over time, and illustrates TCP slow-start and transition to steady-state behavior. Qualitatively, the TCP flows across configurations have nearly identical behavior.
Comparing Figures 2(a) and 2(b), we see that a dilated host has the same packet-level timing behavior as an unmodified host. More importantly, we see that time dilation accurately preserves packet-level timings perceived by the dilated host. Even though the configuration with a TDF of 100 has network conditions two orders of magnitude different from the base configuration, time dilation successfully preserves packet-level timings.
Time dilation also accurately preserves packet-level timings under lossy conditions. The second set of time sequence graphs in Figure 3 shows the first second of traces of TCP experiencing 1% loss. As with the lossless experiments, the TCP flows across configurations have nearly identical behavior even with orders of magnitude differences in network conditions.
We further evaluated the performance of a single TCP flow under a wide range of time dilation factors, network bandwidths, delays and loss rates with similar results. For brevity, we omit those results.
|
(4a): Distribution under no loss
![\includegraphics[width=3in]{figures/cdf-tx-noloss.eps}](img23.png)
(4b): Distribution under 1% loss
![\includegraphics[width=3in]{figures/cdf-tx-1loss.eps}](img24.png)
|
Figures 2 and 3 illustrate the accuracy of time dilation qualitatively. For a more quantitative analysis, we compared the distribution of the inter-arrival packet reception and transmission times for the dilated and undilated flows. Figure 4 plots the cumulative distribution function for inter-packet transmission times for a single TCP flow across 10 runs under both lossy and lossless conditions. Visually, the distributions track closely. Table 3 presents a statistical summary for these distributions, the mean and two indices of dispersion -- the coefficient of variance (CoV) and the inter quartile range (IQR) [ 15]. An index of dispersion indicates the variability in the given data set. Both CoV and IQR are unit-less, i.e., they take the unit of measurement out of variability consideration. Therefore, the absolute values of these metrics is not of concern to us, but that they match under dilation is. Given the inherent variability in TCP, we find this similarity satisfactory. The results for inter-packet reception times are similar.
|
|||||||||||||||||||||||||||||||||||
To demonstrate that dilation preserves TCP behavior under a variety of conditions, even for short flows, we performed another set of experiments under heterogeneous conditions. In these experiments, 60 flows shared a bottleneck link. We divided the flows into three groups of 20 flows, with each group subject to an RTT of 20 ms, 40 ms, or 60 ms. We also varied the bandwidth of the bottleneck link from 10 Mbps to 600 Mbps. We conducted the experiments for a range of flow lengths from 5 seconds to 60 seconds and verified that the results were consistent independent of flow duration.
We present data for one set of experiments where each flow lasts for 10 seconds. Figure 5 plots the mean and standard deviation across the flows within each group for TDFs of 1 (regular TCP) and 10. To visually differentiate results in each graph for different TDFs, we slightly offset their error bars on the graph although in practice they experienced the same network bandwidth conditions. For all three groups, the results from dilation agree well with the undilated results: the throughputs for TDF of 1 match those for TDF of 10 within measured variability. Note that these results also reflect TCP's known throughput bias towards flows with smaller RTTs.
|
(5a): 20 flows subject to 20-ms RTT
![\includegraphics[width=3in]{figures/r1-d10.eps}](img25.png)
(5b): 20 flows subject to 40-ms RTT
![\includegraphics[width=3in]{figures/r2-d10.eps}](img26.png)
(5c): 20 flows subject to 60-ms RTT ![\includegraphics[width=3in]{figures/r3-d10.eps}](img27.png)
|
In our experiments thus far, all flows originated at a single VM and were destined to a single VM. However, when running multiple VMs (as might be the case to support, for instance, scalable network emulation experiments [ 26, 29]) one has to consider the impact of VMM scheduling overhead on performance. To explore the issue of VMM scheduling, we investigate the impact of spreading flows across multiple dilated virtual machines running on the same physical host. In particular, we verify that simultaneously scheduling multiple dilated VMs does not negatively impact the accuracy of dilation.
![\includegraphics[width=3in]{figures/varying-bw-mvm.eps}](img28.png)
|
In this experiment, for a given network bandwidth we create 50 connections between two hosts with a lifetime of 1000 RTTs and measure the resulting throughput of each connection. We configure the network with an 80 ms RTT, and vary the perceived network bandwidth from 0-4 Gbps using 1-Gbps switched Ethernet. Undilated TCP has a maximum network bandwidth of 1 Gbps, but time dilation enables us to explore performance beyond the raw hardware limits (we revisit this point in Section 4.1). We repeat this experiment with the 50 flows split across 2, 5 and 10 virtual machines running on one physical machine.
Our results indicate that VMM scheduling does not significantly impact the accuracy of dilation. Figure 6 plots the mean throughput of the flows for each of the four configurations of flows divided among virtual machines. Error bars mark the standard deviation. Once again, the mean flow throughput for the various configurations are similar.
We repeated the experiment shown in Figure
![[*]](crossref.png) for TCP time-dilated by a factor of 10. In this new
experiment, though, we split the 50 flows across 2, 5 and 10
virtual machines, respectively. Figure
6 shows the per-flow
throughput of the 50 flows for the different VM configurations.
As before, we have shifted the error-bars slightly to increase
readability. From the graph, we see that the per-flow
throughput for the various configurations are very similar,
even for the multi-gigabit cases.
for TCP time-dilated by a factor of 10. In this new
experiment, though, we split the 50 flows across 2, 5 and 10
virtual machines, respectively. Figure
6 shows the per-flow
throughput of the 50 flows for the different VM configurations.
As before, we have shifted the error-bars slightly to increase
readability. From the graph, we see that the per-flow
throughput for the various configurations are very similar,
even for the multi-gigabit cases.
Time dilation changes the perceived VM cycle budget; a dilated virtual machine sees TDF times as many CPU cycles per second. Utilizing VMM CPU schedulers, however, we can scale available processing power independently from the network. This flexibility allows us to evaluate the impact of future network hardware on current processor technology. In a simple model, a VM with TDF of 10 running with 10% of the CPU has the same per-packet cycle budget as an undilated VM running with 100% of the CPU. We validate this hypothesis by running an experiment similar to that described for Figure 6. This time, however, we adjust the VMM's CPU scheduling algorithm to restrict the amount of CPU allocated to each VM. We use the Borrowed Virtual Time [ 10] scheduler in Xen to assign appropriate weights to each domain, and a CPU intensive job in a separate domain to consume surplus CPU.
First, we find an undilated scenario that is CPU-limited by increasing link capacity. Because the undilated processor has enough power to run the network at line speed, we reduce its CPU capacity by 50%. We compare this to a VM dilated by TDF of 10 whose CPU has been scaled to 5%. The experimental setup is identical to that in Figure 6: 50 flows, 80ms RTT. For clarity, we first throttled the sender alone, leaving the CPU unconstrained at the receiver; we then repeat the experiment with the receiver alone throttled. Figures 7 and 8 show the results. We plot the per-flow throughput, and error bars mark the standard deviation.
![\includegraphics[width=3in]{figures/sender-validation.eps}](img29.png)
|
![\includegraphics[width=3in]{figures/receiver-validation.eps}](img30.png)
|
If we successfully scale the CPU, flows across a dilated link of the same throughput will encounter identical CPU limitations. Both figures confirm the effectiveness of CPU scaling, as the 50% and 5% lines match closely. The unscaled line (100%) illustrates the performance in a CPU-rich environment. Moreover our system accurately predicts that receiver CPU utilizations are higher than the sender's, confirming that it is possible to dilate CPU and network independently by leveraging the VMMs CPU scheduling algorithm.
|
(9a):
Validating dilation: TCP
performance under dilation matches actual, observed
performance.
![\includegraphics[scale=0.6]{figures/varying-bw-1}](img31.png)
(9b):
Using dilation for protocol evaluation: comparing
TCP with TCP BiC under high bandwidth.
![\includegraphics[scale=0.6]{figures/varying-bw-2}](img32.png)
(9c):
Pushing the dilation envelope: using a TDF of 100
to evaluate protocols under extremely high bandwidths.
![\includegraphics[scale=0.6]{figures/varying-bw-3}](img33.png)
|
Having performed micro-benchmarks to validate the accuracy of time dilation, we now demonstrate the utility of time dilation for two scenarios: network protocol evaluation and high-bandwidth applications.
A key application of time dilation is for evaluating the behavior and performance of protocols and their implementations on future networks. As an initial demonstration of our system's utility in this space, we show how time dilation can support evaluating optimizations to TCP for high bandwidth-delay network environments, in particular using the publicly available BiC [ 30] extension to the Linux TCP stack. BiC uses binary search to increase the congestion window size logarithmically -- the rate of increase is higher when the current transmission rate is much less than the target rate, and slows down as it gets closer to the target rate.
![\includegraphics[width=3in]{figures/varying-rtt.eps}](img34.png)
|
For the network configuration, we use an 80 ms RTT and vary the network bandwidth up to 100 Gbps using underlying 1-Gbps hardware. We configure the machines exactly as in Section 3.3. We perform this experiment for two different protocols: TCP, and TCP with BiC enabled (henceforth referred to as BiC). In all of the following experiments, we adjust the Linux TCP buffers as suggested in the TCP Tuning Guide [ 2].
Figure 9 shows per-flow throughput of the 50 connections as a function of network bandwidth. For one execution, we plot the average throughput per flow, and the error bar marks the standard deviation across all flows. In Figure 9(a), the x-axis goes up to 1 Gbps, and represents the regime where the accuracy of time dilation can be validated against actual observations. Figures 9(b) (1 to 10 Gbps) and 9(c) (10 to 100 Gbps) show how time dilation can be used to extrapolate performance.
The graphs show three interesting results. First, time dilation enables us to experiment with protocols beyond hardware limits using implementations rather than simulations. Here we experiment with an unmodified TCP stack beyond the 1 Gbps hardware limit to 100 Gbps. Second, we can experimentally show the impact of high bandwidth-delay products on TCP implementations. Beyond 10 Gbps, per-flow TCP throughput starts to level off. Finally, we can experimentally demonstrate the benefits of new protocol implementations designed for such networks. Figure 9(b) shows that in the 1-10 Gbps regime, BiC outperforms TCP by a significant margin. However, in Figure 9(c) we see that TCP shows a steady, gradual improvement and both BiC and TCP level off beyond 10 Gbps.
![\includegraphics[width=3in]{figures/sender-scaled.eps}](img35.png)
|
TCP performance is also sensitive to RTT. To show this effect under high-bandwidth conditions, we perform another experiment with 50 connections between two machines. However, we instead fix the network bandwidth at 150 Mbps and vary the perceived RTT between the hosts. For clarity, we present an alternative visualization of the results: instead of plotting the absolute per-flow throughput values, we instead plot normalized throughput values as a fraction of maximum potential throughput. For example, with 50 connections on a 150-Mbps bandwidth link, the maximum average per-flow throughput would be 3 Mbps. Our measured average per-flow throughput was 2.91 Mbps, resulting in a normalized per-flow throughput of 0.97. Figure 10 shows the average per-flow throughput of the three protocols as a function of RTT from 0-800 ms. We chose this configuration to match a recent study on XCP [ 16], a protocol targeting high bandwidth-delay conditions. The results show the well-known dependence of TCP throughput on RTT, and that the two dilated protocols behave similarly to undilated TCP.
We can also use time dilation as a tool to estimate the computational power required to sustain a target bandwidth. For instance, from Figure 11, we can see that across a 4-Gbps pipe with an 80-ms RTT, 40% CPU on the sender is sufficient for TCP to reach around 50% utilization. This means that processors that are 4 times as fast as today's processors will be needed to achieve similar performance (since 40% CPU at TDF of 10 translates to 400% CPU at TDF of 1).
|
(12a):
VMs are running with TDF of 1 (no
dilation). Performance degrades as clients contend for
CPU resources.
![\includegraphics[scale=0.3]{figures/bt-tdf1}](img36.png)
(12b):
VMs are running with TDF of 10 and perceived
network capacity is 1 Gbps. Dilation removes CPU
contention, but network capacity becomes saturated with
many clients.
![\includegraphics[scale=0.3]{figures/bt-tdf10-constrained}](img37.png)
(12c):
VMs are running with TDF of 10. Perceived
network capacity is 10 Gbps. Increasing perceived
network capacity removes network bottleneck, enabling
aggregate bandwidth to scale until clients again
contend for CPU.
![\includegraphics[scale=0.3]{figures/bt-tdf10}](img38.png)
|
Time dilation can significantly enhance our ability to evaluate data-intensive applications with high bisection bandwidths using limited hardware resources. For instance, the recent popularity of peer-to-peer environments for content distribution and streaming requires significant aggregate bandwidth for realistic evaluations. Capturing the requirements of 10,000 hosts with an average of 1 Mbps per host would require 10 Gbps of emulation capacity and sufficient processing power for accurate study--a hardware configuration that would be prohibitively expensive to create for many research groups.
We show initial results of our ability to scale such experiments using modest hardware configurations with BitTorrent [ 9], a high-bandwidth peer-to-peer, content distribution protocol. Our goal was to explore the bottlenecks when running a large scale experiment using the publicly available BitTorrent implementation [ 1] (version 3.4.2).
We conducted our experiments using 10 physical machines hosting VMs running BitTorrent clients interconnected through one ModelNet [ 26] core machine emulating an unconstrained network topology of 1,000 nodes. The client machines and the ModelNet core are physically connected via a gigabit switch. The ModelNet topology is unconstrained in the sense that the network emulator forwards packets as fast as possible between endpoints. We create an overlay of BitTorrent clients, all of which are downloading a 46-MB file from an initial ``seeder''. We vary the number of clients participating in the overlay, distributing them uniformly among the 10 VMs. As a result, the aggregate bisection bandwidth of the BitTorrent overlay is limited by the emulation capacity of ModelNet, resource availability at the clients, and the capacity of the underlying hardware.
In the following experiments, we demonstrate how to use time dilation to evaluate BitTorrent performance beyond the physical resource limitations of the test-bed. As a basis, we measure a BitTorrent overlay running on the VMs with a TDF of 1 (no dilation). We scale the number of clients in the overlay from 40 to 240 (4-24 per VM). We measure the average time for downloading the file across all clients, as well as the aggregate bisection bandwidth of the overlay; we compute aggregate bandwidth as the number of clients times the average per-client bandwidth (file size/average download time). Figure 12(a) shows the mean and standard deviation for 10 runs of this experiment as a function of the number of clients. Since the VMs are not dilated, the aggregate bisection bandwidth cannot exceed the 1-Gbps limit of the physical network. From the graph, though, we see that the overlay does not reach this limit; with 200 clients or more, BitTorrent is able to sustain aggregate bandwidths only up to 570 Mbps. Increasing the number of clients further does not increase aggregate bandwidth because the host CPUs become saturated beyond 20 BitTorrent clients per machine.
In the undilated configuration, CPU becomes a bottleneck before network capacity. Next we use time dilation to scale CPU resources to provide additional processing for the clients without changing the perceived network characteristics. To scale CPU resources, we repeat the previous experiment but with VMs dilated with a TDF of 10. To keep the network capacity the same as before, we restrict the physical capacity of each client host link to 100 Mbps so that the underlying network appears as a 1-Gbps network to the dilated VMs. In effect, we dilate time to produce a new configuration with hosts with 10 times the CPU resources compared with the base configuration, interconnected by an equivalent network. Figure 12(b) shows the results of 10 runs of this experiment. With the increase in CPU resources for the clients, the BitTorrent overlay achieves close to the maximum 1-Gbps aggregate bisection bandwidth of the network. Note that the download times (in the dilated time frame) also improve as a result; due to dilation, though, the experiment takes longer in wall clock time (the most noticeable cost of dilation).
In the second configuration, network capacity now limits BitTorrent throughput. When using time dilation in the second configuration, we constrained the physical links to 100 Mbps so that the network had equivalent performance as the base configuration. In our last experiment, we increase both CPU resources and network capacity to scale the BitTorrent evaluation further. We continue dilating the VMs with a TDF of 10, but now remove the constraints on the network: client host physical links are 1 Gbps again, with a maximum aggregate bisection bandwidth of 10 Gbps in the dilated time frame. In effect, we dilate time to produce a configuration with 10 times the CPU and network resources as the base physical configuration.
Figure 12(c) shows the results of this last experiment. From these results, we see that the ``faster'' network leads to a significant decrease in download times (in the dilated time frame). Second, beyond 200 clients we see the aggregate bandwidth leveling out, indicating that we are again running into a bottleneck. On inspection, at that point we find that the end hosts are saturating their CPUs again as with the base configuration. Note, however, that in this case the peak bisection bandwidth exceeds 4 Gbps -- performance that cannot be achieved natively with the given hardware.
Based upon these experiments, our results suggest that time dilation is a valuable tool for evaluating large scale distributed systems by creating resource-rich environments. Further exploration with other applications remains future work.
Perhaps the work closest to ours in spirit is SHRiNK [ 21]. SHRiNK reduces the overhead of simulating large-scale networks by feeding a reduced sample of the original traffic into a smaller-scale network replica. The authors use this technique to predict properties such as the average queueing delays and drop probabilities. They argue that this is possible for TCP-like flows and a network controlled by active queue management schemes such as RED. Compared to this effort, time dilation focuses on speed rather than size and supports unmodified applications.
The idea of changing the flow of time to explore faster networks is not a new one. Network simulators [ 3, 22, 25] use a similar idea; they run the network in virtual time, independent of wall-clock time. This allows network simulators to explore arbitrarily fast or long network pipes, but the accuracy of the experiments depends on the fidelity of the simulated code to the actual implementation. Complete machine simulators such as SimOS [ 24] and specialized device simulators such as DiskSim have also been proposed for emulating and evaluating operating systems on future hardware. In contrast, time dilation combines the flexibility to explore future network configurations with the ability to run real-world applications on unmodified operating systems and protocol stacks.
Researchers spend a great deal of effort speculating about
the impacts of various technology trends. Indeed, the systems
community is frequently concerned with questions of scale: what
happens to a system when bandwidth increases by
![]() , latency by
, latency by
![]() , CPU speed by
, CPU speed by
![]() , etc. One challenge to addressing such questions is
the cost or availability of emerging hardware technologies.
Experimenting at scale with communication or computing
technologies that are either not yet available or prohibitively
expensive is a significant limitation to understanding
interactions of existing and emerging technologies.
, etc. One challenge to addressing such questions is
the cost or availability of emerging hardware technologies.
Experimenting at scale with communication or computing
technologies that are either not yet available or prohibitively
expensive is a significant limitation to understanding
interactions of existing and emerging technologies.
Time dilation enables empirical evaluation at speeds and capacities not currently available from production hardware. In particular, we show that time dilation enables faithful emulation of network links several orders of magnitude greater than physically feasible on commodity hardware. Further, we are able to independently scale CPU and network bandwidth, allowing researchers to experiment with radically new balance points in computation to communication ratios of new technologies.
We would like to thank Charles Killian for his assistance with setting up ModelNet experiments, Kashi Vishwanath for volunteering to use time dilation for his research and Stefan Savage and all the anonymous reviewers for their valuable comments and suggestions. Special thanks to our shepherd, Jennifer Rexford, for her feedback and guidance in preparing the camera-ready version. This research was supported in part by the National Science Foundation under CyberTrust Grant No. CNS-0433668 and the UCSD Center for Networked Systems.
This document was generated using the LaTeX2 HTML translator Version 2002-2-1 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos
Drakos, Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html
-split 0 -show_section_numbers -local_icons -html_version
4.0 -dir html main.tex
The translation was initiated by Diwaker Gupta on 2006-04-07
|
This paper was originally published in the Proceedings of the
3rd Symposium on Networked Systems Design and Implementation (NSDI '06) May 8–10, 2006, San Jose, CA Last changed: 3 May 2006 jel |

![\includegraphics[width=3in]{figures/td_simple.eps}](img1.png)
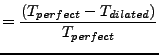
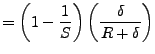
![\includegraphics[width=3in]{figures/100Mbit-d10-l0-native-1.eps}](img15.png)
![\includegraphics[width=3in]{figures/100Mbit-d10-l0-t1-1.eps}](img16.png)
![\includegraphics[width=3in]{figures/10Mbit-d100-l0-t10-1.eps}](img17.png)
![\includegraphics[width=3in]{figures/1Mbit-d1000-l0-t100-1.eps}](img18.png)