| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
NSDI '04 Paper
[NSDI '04 Technical Program]
Consistent and Automatic Replica RegenerationHaifeng Yu
Abstract
Reducing management costs and improving the availability of large-scale distributed systems require automatic replica regeneration, i.e., creating new replicas in response to replica failures. A major challenge to regeneration is maintaining consistency when the replica group changes. Doing so is particularly difficult across the wide area where failure detection is complicated by network congestion and node overload. In this context, this paper presents Om, the first read/write peer-to-peer wide-area storage system that achieves high availability and manageability through online automatic regeneration while still preserving consistency guarantees. We achieve these properties through the following techniques. First, by utilizing the limited view divergence property in today's Internet and by adopting the witness model, Om is able to regenerate from any single replica rather than requiring a majority quorum, at the cost of a small (10-6 in our experiments) probability of violating consistency. As a result, Om can deliver high availability with a small number of replicas, while traditional designs would significantly increase the number of replicas. Next, we distinguish failure-free reconfigurations from failure-induced ones, enabling common reconfigurations to proceed with a single round of communication. Finally, we use a lease graph among the replicas and a two-phase write protocol to optimize for reads, and reads in Om can be processed by any single replica. Experiments on PlanetLab show that consistent regeneration in Om completes in approximately 20 seconds.
1 IntroductionReplication has long been used for masking individual node failures and for load balancing. Traditionally, the set of replicas is fixed, requiring human intervention to repair failed replicas. Such intervention can be on the critical path for delivering target levels of performance and availability. Further, the cost of maintenance now dominates the total cost of hardware ownership, making it increasingly important to reduce such human intervention. It is thus desirable for the system to automatically regenerate upon replica failures by creating new replicas on alternate nodes. Doing so not only reduces maintenance cost, but also improves availability because regeneration time is typically much shorter than human repair time. Motivated by these observations, automatic replica regeneration and reconfiguration (i.e., change of replica group membership) have been extensively studied in cluster-base Internet services [12,34]. Similarly, automatic regeneration has become a necessity in emerging large-scale distributed systems [1,10,20,25,30,33,35]. One of the major challenges to automatic regeneration is maintaining consistency when the composition of the replica group changes. Doing so is particularly difficult across the wide-area where failure detection is complicated by network congestion and node overload. For example, two replicas may simultaneously suspect the failure of each other, form two new disjoint replica groups, and independently accept conflicting updates. The focus of this work is to enable automatic regeneration for replicated wide-area services that require some level of consistency guarantees. Previous work on replica regeneration either assumes read-only data and avoids the consistency problem (e.g., CFS [10] and PAST [33]), or simply enforces consistency in a best-effort manner (e.g., Inktomi [12], Porcupine [34], Ivy [25] and Pangaea [35]). Among those replication systems [1,6,20,30,37] that do provide strong consistency guarantees, Farsite [1] does not implement replica group reconfiguration. Oceanstore [20,30] mentions automatic reconfiguration as a goal but does not detail its approach, design or implementation. Proactive recovery [6] enables the same replica to leave the replica group and later re-join, but still assumes a fixed set of replicas. Finally, replicated state-machine research [37] typically also assumes a static set of replicas. In this context, we present Om, a read/write peer-to-peer wide-area storage system. Om logically builds upon PAST [33] and CFS [10], but achieves high availability and manageability through online automatic regeneration while still preserving consistency guarantees. To the best of our knowledge, Om is the first implementation and evaluation of a wide-area peer-to-peer replication system that achieves such functionality. Om's design targets large, infrastructure-based hosting services consisting of hundreds to thousands of sites across the Internet. We envision companies utilizing hosting infrastructure such as Akamai [2] to provide wide-area mutable data access service to users. The data may be replicated at multiple wide-area sites to improve service availability and performance. We believe that our design is also generally applicable to a broader range of applications, including: i) a totally-ordered event notification system, ii) distributed games, iii) parallel grid computing applications sharing data files, and iv) content distribution networks and utility computing environments where a federation of sites deliver read/write network services. We adopt the following novel techniques to achieve our goal of consistent and automatic replica regeneration.
Om assumes a crash (stopping) rather than Byzantine failure model. While this assumption makes our approach inappropriate for a certain class of services, we argue that the performance, availability, consistency, and flexible reconfiguration resulting from our approach will make our work appealing for a range of important applications. Through WAN measurement and local area emulation, we observe that the probability of violating consistency in Om is approximately 10-6 , which means that on average, inconsistency occurs once every 250 years with 5 replicas and a pessimistic 12 hours replica MTTF. At the same time, the ability to regenerate from any replica enables Om to achieve high availability using a relatively small number of replicas [42] (e.g., 99.9999% using 4 replicas with node MTTF of 12 hours, regeneration time of 5 minutes and human repair time of 8 hours). Under stress tests for write throughput on PlanetLab [27], we observe that regeneration in response to replica failures only causes a 20-second service interruption. We provide an overview of Om in the next section. The following three sections then discuss the details of normal case operations, reconfiguration, and single replica regeneration in Om. We present unsafety (probability of violating consistency) and performance evaluation in Section 6. Finally, Section 7 discusses related work and Section 8 draws our conclusions.
|
|
Throughout this paper, we use linearizability [18] as the definition for consistency. An access to an Om object is either a read or a write. Each access has a start time, the wall-clock time when the user submits the access, and a finish time, the wall-clock time when the user receives the reply. Linearizability requires that: i) each access has a unique serialization point that falls between its start time and finish time, and ii) the results of all accesses and the final state of the replicas are the same as if the accesses are applied sequentially by their serialization points.
To maintain consistency, Om uses two different quorum systems in two different places of the design. The first is a read-one/write-all quorum system for accessing objects on the replicas. We choose to use this quorum system to maximize the performance of read operations. In general, however, our design supports an arbitrary choice of read/write quorum. Each configuration has a primary replica responsible for serializing all writes and transmitting them to secondary replicas. The failure of any replica causes regeneration. Thus both primary and secondary replicas correspond to gold replicas in Pangaea [35]. It is straightforward to add additional bronze replicas (which are not regenerated) into our design. Distinguishing these two kinds of replicas helps to decrease the overhead of maintaining the lease graph, liveness monitoring and performing two-phase writes among the gold replicas.
Reads can be processed by any replica without interacting with other replicas. A write is always forwarded to the primary, which uses a two-phase protocol to propagate the write to all replicas (including itself). Even though two-phase protocols in WAN can incur high overhead, we limit this overhead because Om usually needs a relatively small number of replicas to achieve certain availability target [42] (given its single replica regeneration mechanism).
The second quorum system is used during reconfiguration to ensure that replicas agree on the membership of the new configuration. In wide-area settings, it is possible for two replicas to simultaneously suspect the failure of each other and to initiate regeneration. To maintain consistency, the system must ensure a unique configuration for the object at any time. Traditional approaches for guaranteeing unique configuration require each replica to coordinate with a majority before regeneration, so that no simultaneous conflicting regeneration can be initiated.
Given the availability cost of requiring a majority [42] to coordinate regeneration, we adopt the witness model [40] that achieves similar functionality as a quorum system. In the witness model, quorum intersection is not always guaranteed, but is extremely likely. In return, a quorum in the witness model can be as small as a single node. While our implementation uses the witness model, our design can trivially replace the witness model with a traditional quorum system such as majority voting.
The membership of a configuration changes upon the detection of node failures or explicit reconfiguration requests. Failures are detected in Om via timeouts on messages or heartbeats. By definition, accurate failure detection in an environment with potential network failure and node overload, such as the Internet, is impossible. Improving failure detection accuracy is beyond the scope of this paper.
There are two types of reconfigurations in Om: failure-free reconfiguration and failure-induced reconfiguration. Failure-free reconfiguration takes place when a set of nodes gracefully leave or join the configuration. ``Gracefully'' means that there are no node failures or message timeouts during the process. On the other hand, Om performs failure-induced reconfiguration when it (potentially incorrectly) detects a node failure (in either normal operation or reconfiguration).
Failure-free reconfiguration is lightweight and requires only a single round of messages from the primary to all replicas, a process even less expensive than writes. Failure-induced reconfiguration is more expensive because it uses a consensus protocol to enable the replicas to agree on the membership of the next configuration. The consensus protocol, in turn, relies on the second quorum system to ensure that the new configuration is unique among the replicas.
Under a denial of service (DoS) attack, all reconfigurations will become failure-induced. One concern is that an Om configuration must be sufficiently over-provisioned to handle the higher cost of failure-induced reconfiguration under the threat of such attacks. However, the reconfiguration functionality of Om actually enables it to dynamically shift to a set of more powerful replicas (or expand the replica group) under DoS attacks, making static over-provisioning unnecessary.
New replicas are always created by the primary in the background. To achieve this without blocking normal operations, the primary replica creates a snapshot of the data and transfers the snapshot to the new replicas. During this process, new reads and writes are still accepted, with the primary logging those writes accepted after creating the snapshot. After the snapshot has been transferred, the primary will send the logged writes to the new replicas, and then initiate a failure-free reconfiguration to include them in the configuration. Since the time needed to transfer the snapshot tends to dominate the total regeneration time, Om enables online regeneration without blocking accesses.
Each node in the system maintains an incarnation counter in stable storage. Whenever a node loses its state in memory (due to a crash or reboot), it increments the incarnation number. After the node rejoins the system, it should discard all messages intended for older incarnations. This is necessary for a number of reasons: For example, otherwise a primary that crashes and then recovers immediately will not be able to keep track of the writes in the middle of the two-phase protocol.
Given the overall architecture described above, we now discuss some of the complex system interactions in Om. Despite the simplicity of the read-one/write-all approach for accessing objects, failures and reconfigurations may introduce several anomalies in a naive design. Below we describe two major anomalies and our solutions.
The first anomaly arises when replicas from old configurations are slow in detecting failures, and continue servicing stale data after reconfiguration (initiated by other replicas). We address this scenario by leveraging leases [17]. In traditional client-server architectures, each client holds a lease from the server. However, since Om can regenerate from any replica, a replica needs to hold valid leases from all other replicas.
Requiring each replica to contact every other replica for a lease can incur significant communication overhead. Fortunately, it is possible for a replica to sublease those leases it already holds. As a result, when a replica A requests a lease from B , B will not only grant A a lease for B , it can also potentially grant A leases for other replicas (with a shorter lease expiration time, depending on how long B has been holding those leases).
Following we abstract the problem by considering replicas to be nodes
in a lease graph. If a node A directly requests a lease from
node B , we add an arc from B to A in the graph. A lease graph
must be strongly connected to avoid stale reads.
Furthermore, we would like the layers of recursive subleasing to be as
small as possible because each layer of sublease decreases the
effective duration of the lease. Define the diameter of a lease graph
to be the smallest integer d , such that any node A can reach any
other node B via a directed path of length at most d . In our
system, we would like to limit d to 2 to ensure the effectiveness of
subleasing. Overhead of lease renewal is determined by the number of
arcs in the lease graph. It has been proven [16] that
with ![]() nodes, the minimal number of arcs to achieve d=2 is
2(n-1) . For
nodes, the minimal number of arcs to achieve d=2 is
2(n-1) . For ![]() , we can show that the only graph reaching
this lower bound is a star-shaped graph. Thus, our lease graphs are
all star-shaped, with every node having two arcs to and from a central
node. The central node does not have to be the primary of the
configuration, though it is in our implementation.
, we can show that the only graph reaching
this lower bound is a star-shaped graph. Thus, our lease graphs are
all star-shaped, with every node having two arcs to and from a central
node. The central node does not have to be the primary of the
configuration, though it is in our implementation.
A second problem results from a read seeing a write that has not been applied to all replicas, and the write may be lost in reconfiguration. In other words, the read observes temporary, inconsistent state. To avoid this scenario, we employ a two-phase protocol for writes. In the first prepare round, the primary propagates the writes to the replicas. Each replica records the write in a pending queue and sends back an acknowledgment. After receiving all acknowledgments, the primary will start the second commit round by sending commits to all replicas. Upon receiving a commit, a replica applies the corresponding write to the data object. Finally, the primary sends back an acknowledgment to the user. A write becomes ``stable'' (applied to all replicas) when the user receives an acknowledgment. The lack of an acknowledgment indicates that the write will ultimately be seen by all or none of the replicas. A user may choose to re-submit an un-acknowledged write, and Om performs appropriate duplicate detection and elimination.
After a failure-induced reconfiguration and before a new primary can serialize any new writes, it first collects all pending writes from the replicas in the new configuration and processes the writes again using the normal two-phase protocol. Each replica performs appropriate duplicate detection and elimination in this process. Such design solves the previous problem because if any read sees a write, then the write must be either applied or in the pending queue on all replicas.
Each configuration has a monotonically increasing sequence number, increased with every reconfiguration. For any configuration and at any point of time, a replica can only be in a single reconfiguration process (either failure-free or failure-induced). It is however, possible that different replicas in the same configuration are simultaneously in different reconfiguration processes.
Conceptually, a replica that finishes reconfiguration will try to inform other replicas of the new configuration by sending configuration notices. In failure-free reconfigurations, only the primary does this, because the other replicas are passive. In failure-induced reconfigurations, all replicas transmit configuration notices to aid in completing reconfiguration earlier. In many cases, most replicas do not even need to enter the consensus protocol--they simply wait for the configuration notice (within a timeout).
Only the primary may initiate failure-free reconfiguration. Secondary replicas are involved only when i) the primary transmits to them data for creating new replicas; and ii) the primary transmits configuration notices.
The basic mechanism of failure-free reconfiguration is straightforward. After transferring data to the new replicas in two stages (snapshot followed by logged writes as discussed earlier), the primary constructs a configuration for the new desired membership. This new configuration will have a new sequenceNum by incrementing the old sequenceNum. The consensusID of the configuration remains unchanged.
The primary then informs the other replicas of the new configuration and waits for acknowledgments. If timeout occurs, a failure-induced reconfiguration will follow.
In contrast to failure-free reconfigurations, failure-induced reconfigurations can only shrink the replica group (potentially followed by failure-free reconfigurations to expand the replica group as necessary). Doing this simplifies design because failure-induced reconfigurations do not need to create new replicas and request them to participate in the consensus protocol. Failure-induced reconfigurations can take place during normal operations, failure-free reconfigurations or even failure-induced reconfigurations.
A replica initiates failure-induced reconfiguration (Figure 2) upon detecting a failure. The replica first disables the current configuration so that leases can no longer be granted for the current configuration. This reduces the time we need to wait for lease expiration later. Next, it will perform another round of failure detection for all members of the configuration. The result (a subset of the current replicas) will be used as a proposal for the new configuration. The replica then invokes a consensus protocol, which returns a decision that is agreed upon by all replicas entering the protocol. When invoking the consensus protocol, the replica needs to pass a unique ID for this particular invocation of the consensus protocol. Otherwise, since nodes can be arbitrarily slow, different invocations of the consensus protocol may interfere with one another.
Before adopting a decision, each replica needs to wait for all leases to expire with respect to the old configuration. Finally, the primary of the new configuration will collect and re-apply any pending writes. When re-applying pending writes, the primary only waits for a certain timeout. If a subsequent failure were to take place, the replicas will start another failure-induced reconfiguration.
One important optimization to the previous protocol is that after a replica determines newmember, it checks whether it has the smallest ID in the set. If it does not, the replica will wait (within a timeout) for a configuration notice. With this optimization, in most cases, only a single replica enters the consensus protocol, which can significantly improve the time complexity of the randomized consensus protocol (see Section 5.3).
When a failure-induced reconfiguration is invoked in the middle of a failure-free reconfiguration, they may interfere with each other and result in inconsistency. Such issue is properly addressed in our complete design [42].
Failure-induced reconfigurations depend on a consensus protocol to ensure the uniqueness of the new configuration and in turn, data consistency. Consensus [22] is a classic distributed computing problem and we can conceptually use any consensus protocol in Om. However, most consensus protocols such as Paxos [21] rely on majority quorums and thus cannot tolerate more than n/2 failures among n replicas. To reduce the number of replicas required to carry out regeneration (as a desirable side-effect, this also reduces the overhead of acquiring leases and of performing writes), we adopt the witness model [40] to achieve probabilistic consensus without requiring a majority.
The witness model [40] is a novel quorum design that allows
quorums to be as small as a single node, while ensuring probabilistic
quorum intersection. In our system, for each new configuration, the
primary chooses ![]() witnesses and communicates their identities to all secondary
replicas.
Witnesses are periodically probed by the primary and refreshed as
necessary upon failure. This refresh is trivial and can be done in
the form of a two-phase write. If failure occurs between
the first and the second phase, a replica will use both old and new
witnesses in the consensus protocol. The primary may utilize a variety of techniques
to choose witnesses, with the goal of choosing witnesses with small
failure correlation and diversity in the set of network paths from the
replicas to individual witnesses. For example, the primary may simply
use entries
from its finger table under Chord [38].
witnesses and communicates their identities to all secondary
replicas.
Witnesses are periodically probed by the primary and refreshed as
necessary upon failure. This refresh is trivial and can be done in
the form of a two-phase write. If failure occurs between
the first and the second phase, a replica will use both old and new
witnesses in the consensus protocol. The primary may utilize a variety of techniques
to choose witnesses, with the goal of choosing witnesses with small
failure correlation and diversity in the set of network paths from the
replicas to individual witnesses. For example, the primary may simply
use entries
from its finger table under Chord [38].
For now, we will consider replicas that are not in singleton partitions, where a single node, LAN, or perhaps a small autonomous system is unable to communicate with the rest of the network. Later we will discuss how to determine singleton partitions. We say that a replica can reach a witness if a reply can be obtained from the witness within a certain timeout. The witness model utilizes the following limited view divergence property:
Consider a set S of functioning randomly-placed witnesses that are
not co-located with the replicas (e.g., not in the same LAN). Suppose one replica
A can reach the subset
S1 of witnesses and cannot reach the subset S2 of witnesses
(where ![]() ). Then the probability that another
replica B cannot reach any witness in S1 and can reach all witnesses
in S2 decreases with increasing size of S .
). Then the probability that another
replica B cannot reach any witness in S1 and can reach all witnesses
in S2 decreases with increasing size of S .
Intuitively, the property says that two replicas are unlikely to have a completely different view regarding the reachability of a set of randomly-placed witnesses. The size of S and the resulting probability are thoroughly studied in [40] using the RON [4] and TACT [41] traces. Later we will also present additional results based on PlanetLab measurements.
The validity of limited view divergence can probably be explained by the rarity [9] of large-scale ``hard partitions'', where a significant fraction of Internet nodes are unable to communicate with the rest of the network. Given that witnesses are randomly placed, if the two replicas have completely different views on the witnesses, this tends to indicate a ``hard partition''. Further, the more witnesses, the larger-scale the partition would have to be to result in entirely disjoint views from the perspective of two independent replicas.
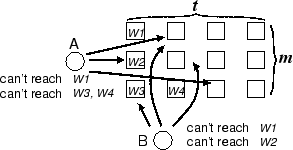
To utilize the limited view divergence property, all replicas logically organize the
witnesses into an ![]() matrix. The number of rows, m ,
determines the probability of intersection. The number of columns, t ,
protects against the failure of individual
witnesses, so that each row has at least one
functioning witness with high probability.
Each replica tries to coordinate with one witness from each
row. Specifically, a replica uses the first witness from left to right that it can
reach for each row (Figure 3). The set of
witnesses used by a replica is its quorum. Now consider two replicas
A and B . The desirable outcome is that A 's quorum intersects with
B 's. It can be shown that if the two quorums do not intersect, with
high probability (in terms of t ),
A and B have completely different views on the reachability of m witnesses [40].
matrix. The number of rows, m ,
determines the probability of intersection. The number of columns, t ,
protects against the failure of individual
witnesses, so that each row has at least one
functioning witness with high probability.
Each replica tries to coordinate with one witness from each
row. Specifically, a replica uses the first witness from left to right that it can
reach for each row (Figure 3). The set of
witnesses used by a replica is its quorum. Now consider two replicas
A and B . The desirable outcome is that A 's quorum intersects with
B 's. It can be shown that if the two quorums do not intersect, with
high probability (in terms of t ),
A and B have completely different views on the reachability of m witnesses [40].
Replicas behind singleton partitions will violate limited view divergence. However, if the witnesses are not co-located with the replica, then the replica behind the partition will likely not be able to reach any witness. As a result, it cannot acquire a quorum and will thus block. This is a desirable outcome as the replicas on the other side of the partition will reach consensus on a new configuration that excludes the node behind the singleton partition. To better detect singleton partitions, a replica may also check whether all reachable witnesses are within its own LAN or autonomous system.
We intend to substitute the majority quorum in traditional consensus protocols with the witness model, so that the consensus protocol can achieve probabilistic consensus without requiring majority. To do this however, we need a consensus protocol with ``good'' termination properties for the following reason. Non-intersection in the witness model is ultimately translated into the unsafety (probability of having multiple decisions) of a consensus protocol. Unsafety in turn, means violation of consistency in Om. For protocols with multiple rounds, unsafety potentially increases with every round. This precludes the application of protocols such as Paxos [21] that do not have good termination guarantees.
To address the previous issue, we first use the witness model to emulate a probabilistic shared-memory, where reads may return stale values with a small probability. We then apply a shared-memory randomized consensus protocol [36], where the expected number of rounds before termination is constant and thus helps to bound unsafety.
To reduce the message complexity of the shared-memory emulation, we choose not to directly emulate [40] the standard notion of reads and writes. Rather, we define an access operation on the shared-memory to be an update to an array element followed by a read of the entire array. The element to be updated is indexed by the replica's identifier. The witnesses maintain the array. Upon receiving an access request, a witness updates the corresponding array element and returns the entire array. Such processing is performed in isolation from other access requests on the same witness. Figure 4 provides the pseudo-code for such emulation.
While the access primitive appears to be a simple wrapper around reads and writes, it actually violates atomicity and qualitatively changes the semantics of the shared-memory. It reduces the message (and time) complexity of the shared-memory emulation in [40] by half. More details are available in [42].
With the shared-memory abstraction, we can now apply a previous
shared-memory consensus protocol [36]
(Figure 5). For simplicity, we assume that the
proposals and decisions are all integer values, though they are actually
configurations. In the figure, we already substitute the read and
write operations in the original protocol with our new access
operations. We implement coinFlip()
using a local random number generator
initialized using a common seed shared by all replicas. Such
implementation is different and
simpler than the design for standard shared-memory consensus
protocols, and it reduces the complexity of the protocol by a factor
of ![]() . See [42] for details on why such
optimization is possible.
. See [42] for details on why such
optimization is possible.
The intuition behind the shared-memory consensus protocol is subtle and several textbooks have chapters devoted to these protocols (e.g., Chapter 11.4 of [8]). Since the protocol itself is not a contribution of this paper, we only enumerate several important properties of the protocol. Proofs are available in [42].
This section evaluates the performance and unsafety of Om. Availability of Om and the benefit of single replica regeneration is studied separately [42]. Om is written in Java 1.4, using TCP and nonblocking I/O for communication. All messages are first serialized using Java serialization and then sent via TCP. The core of Om uses an event-driven architecture.
Om is able to regenerate from any single replica at the cost of a small probability of consistency violation. We first quantify such unsafety under typical Internet conditions.
Unsafety is about rare events, and explicitly measuring unsafety experimentally faces many of the same challenges as evaluating service availability [41]. For instance, assuming that each experiment takes 10 seconds to complete, we would need on average over four years to observe a single inconsistency event for an unsafety of 10-7 . Given these challenges, we follow the methodology in [41] and use a real-time emulation environment for our evaluation. We instrument Om to add an artificial delay to each message. Since the emulation is performed on a LAN, the actual propagation delay is negligible. We determine the distribution of appropriate artificial delays by performing a large-scale measurement study of PlanetLab sites. For our emulation, we set the delay of each message sent across the LAN to the delay of the corresponding message in our WAN measurements.
Our WAN sampling software runs with the same communication pattern as
the consensus protocol except that it does not interpret the
messages. Rather, the replicas repeatedly communicate with all
witnesses in parallel via TCP. The request size is 1KB while the reply
is 2KB. We log the time (with a cap of 6 minutes) needed to receive a
reply from individual witnesses. The sampling interval (time between
successive samples) for each replica ranges from 1 to 10 seconds in
different measurements. Notice that we do not necessarily wait for the
previous probe's reply before sending the next probe. All of our
measurements use 7 witnesses and 15 replicas on 22 different PlanetLab
sites. To avoid the effects of Internet2 and to focus on the
pessimistic behavior of less well-connected sites, we locate the
witnesses at non-educational or foreign sites: Intel Research
Berkeley, Technische Universitat Berlin, NEC Laboratories, Univ of
Technology, Sydney, Copenhagen, ISI, Princeton DSL. Half of the nodes
serving as replicas are also foreign or non-educational sites, while
the other half are U.S. educational sites. For the results presented
in this paper, we use an 8-day long trace measured in July 2003. The
sampling interval in this trace is 5 seconds, and the trace contains
150,000 intervals. Each interval has ![]() samples,
resulting in over 15 million samples.
samples,
resulting in over 15 million samples.
The key property utilized by the witness model is that Pni
(probability of non-intersection) can be quite small even with a small
number of witnesses. Earlier work [40] verifies this
assumption using a number of existing network measurement
traces [4,41].
In the RON1 trace, 5 witness rows result in ![]() Pni , while it takes 6 witness rows to yield similar Pni
under the TACT trace.
Pni , while it takes 6 witness rows to yield similar Pni
under the TACT trace.
Given these earlier results, this section concentrates on the relationship between Pni and unsafety, namely, how the randomized consensus protocol amplifies Pni into unsafety under different parameter settings. This is important since the protocol has multiple rounds, and non-intersection in any round may result in unsafety.
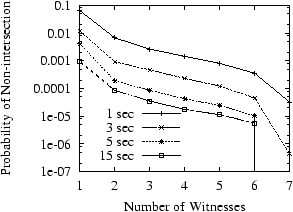
Unsafety can be affected by several parameters in our system: the message timeout value for contacting witnesses, the size of the witness matrix and the number of replicas. Since a larger t value in the witness matrix is used to guard against potential witness failures and witnesses do not fail in our experiments, we use t=1 for all our experiments. Witness failures between accesses may slightly increase Pni , but a simple analysis can show that such effects are negligible [42] under practical parameters. Larger timeout values decrease the possibility that a replica cannot reach a functioning witness and thus decrease Pni . Figure 6 plots Pni for different timeout values. In our finite-duration experiments, we cannot observe probabilities below 10-7 . This is why the curves for 5 and 15 second timeout values drop to zero with seven witnesses. The figure shows that Pni quickly approaches its lowest value with the timeout at 5 seconds.
Having determined the timeout value, we now use emulation to
measure unsafety.
We first consider the simple case of two replicas.
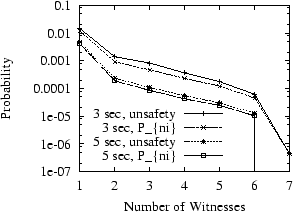
Figure 7 plots both Pni and unsafety for two
different timeout values.
Using just 7 witnesses, Om already achieves an unsafety of ![]() . With 5 replicas and a pessimistic replica MTTF of 12 hours,
reconfiguration takes place every 2.4 hours. With unsafety at
. With 5 replicas and a pessimistic replica MTTF of 12 hours,
reconfiguration takes place every 2.4 hours. With unsafety at ![]() , an inconsistent reconfiguration would take place once every
500 years. In a peer-to-peer system with a large number of nodes,
reconfiguration can occur much more frequently. For example, for a
Pastry ring with 1,000 nodes and replication degree of 5 , each
node may be shared by 5 different configurations. As a result,
reconfiguration in the entire system occurs every 8.64 seconds. In
this case, inconsistent regeneration will take place once every half
year system-wide. It may be possible to further reduce unsafety with
additional witnesses, though the benefits cannot be quantified with
the granularity of our current measurements.
, an inconsistent reconfiguration would take place once every
500 years. In a peer-to-peer system with a large number of nodes,
reconfiguration can occur much more frequently. For example, for a
Pastry ring with 1,000 nodes and replication degree of 5 , each
node may be shared by 5 different configurations. As a result,
reconfiguration in the entire system occurs every 8.64 seconds. In
this case, inconsistent regeneration will take place once every half
year system-wide. It may be possible to further reduce unsafety with
additional witnesses, though the benefits cannot be quantified with
the granularity of our current measurements.
The extended version of this paper [42] further discusses the relationship between unsafety and Pni , and also generalizes the results to more than two replicas. Due to space limitations, we will move on to the performance results.
We obtain our performance results by deploying and evaluating Om over PlanetLab. In all our performance experiments, we use the seven witnesses used before in our WAN measurement. With single replica regeneration, Om can achieve high availability with a small number of replicas. For example, our analysis [42] shows that Om can achieve 99.9999% availability with just 4 replicas under reasonable parameter settings. Thus, we focus on small replication factors in our evaluation.
We first provide basic latency results for individual read and write operations using 10 PlanetLab nodes as replicas. We intentionally choose a mixture of US educational sites, US non-educational sites and foreign sites. To isolate the performance of Om from that of Pastry, we inject reads and writes from the replicas, instead of having client nodes injecting accesses via peer-to-peer routing.
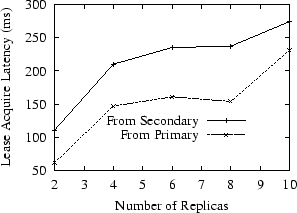
Since a read in Om is processed by a single replica (as long as it holds all necessary leases), a read involves only a single request/response pair. However, additional latency is incurred when lease renewal is required. To separate these effects, we directly study the latency of lease renewal. However, notice that though not implemented in our prototype, leases can be renewed proactively, which will hide most of this latency from the critical path. Figure 8 plots the time needed to renew leases based on our lease graph. Obviously, the primary incurs smaller latency to renew all of its leases. Secondary replicas need to contact the primary first to request the appropriate set of subleases.
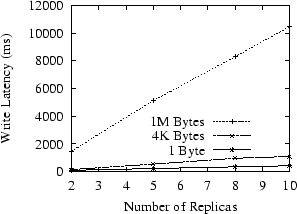
Processing writes is more complex because it involves a two-phase protocol among the replicas. Figure 9 presents the latency for writes of different sizes. In all three cases, the latency increases linearly with the number of replicas, indicating that the network bandwidth of the primary is the likely bottleneck for these experiments. For 1MB writes, the latency reaches 10 seconds for 10 replicas. We believe such latency can be improved by constructing an application-layer multicast tree among the replicas.
We next study the performance of regeneration. For these experiments, we use five PlanetLab nodes as replicas: bu.edu, cs.duke.edu, hpl.hp.com, cs.arizona.edu and cs-ipv6.lancs.ac.uk. Figure 10 shows the cost of failure-free reconfiguration. In all cases, the two components of ``finding replica set'' and ``sending configuration notices'' take less than one second. This is also the cost of failure-free reconfigurations when we shrink instead of expand the replica group. The latency of ``finding replica set'' is determined by Pastry routing, the only place where Pastry's performance influences the performance of reconfiguration. The time needed to transfer the data object begins to dominate the overall cost with 1MB of data. We thus believe that new replicas should be regenerated in the background using bandwidth consumption controlling techniques such as TCP Nice [39].

|
|
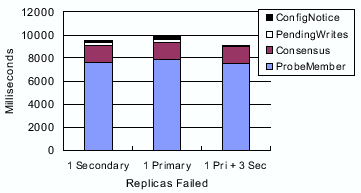
The cost of failure-induced reconfiguration is higher. Figure 11 plots the cost of failure-induced reconfiguration as observed by the primary of the new configuration. Using optimizations in Section 4.2, only one replica (the one with the smallest ID, which is also the primary of the new configuration) enters the consensus protocol immediately, while other replicas wait for a timeout (10 seconds in our case). As a result of this optimization, in all three cases, the consensus protocol terminates after one iteration (two rounds) and incurs an overhead of roughly 1.5 seconds. The new primary then notifies the other replicas of the resulting configuration. In Figure 11, the time needed to determine the live members of the old configuration dominates the total overhead. This step involves probing the old members and waiting for replies within a timeout (7.5 seconds in our case). A smaller timeout would decrease the delay, but would also increase the possibility of false failure detection and unnecessary replica removal.
Waiting for lease expiration, interestingly, does not cause any delay in our experiments (and thus is not shown in Figure 11). Since we disable lease renewal at the very beginning of the protocol and our lease duration is 15 seconds, by the time the protocol completes the probing phase and the consensus protocol, all leases have already expired. In these experiments, we do not inject writes. Thus, the time for applying pending writes only includes the time for the new primary to collect pending writes from the replicas and then to realize that the set is empty. The presence of pending writes will increase the cost of this step, as explored in our later experiments.
Our final set of experiments study the end-to-end effects of reconfiguration on users. For this purpose, we deploy a 42-node Pastry ring on 42 PlanetLab sites, and then measure the write throughput and latency for a particular object during reconfiguration.
For these experiments, we configure the system to maintain a replication degree of four. To isolate the throughput of our system from the potential bottleneck on a particular network path, we directly inject writes on the primary. Both the writes and the data object are of 80KB size. In the two-phase protocol for writes, the primary sends a total of 240KB data to disseminate each write to the three secondary replicas. For each write, the primary also incurs roughly 9KB of control message overhead.
The experiment records the total number of writes returned for every 5 second interval, and then reports the average as the system throughput. Our test program also records the latency experienced by each write. Writes are rejected when the system is performing a failure-induced reconfiguration.
For our experiment, we first replicate the data object at cs.caltech.edu, cs.ucla.edu, inria.fr and csres.utexas.edu (primary). Notice that this replica set is determined by Pastry. Next we manually kill the process running on inria.fr, thus causing a failure-induced reconfiguration to shrink the configuration to three replicas. Next, to maintain a replication factor of 4, Om expands the configuration to include lbl.gov.
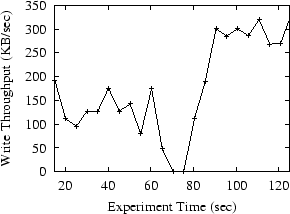
Figure 12 plots the measured throughout of the system over time. The absolute throughput in Figure 12 is largely determined by the available bandwidth among the replica sites. The jagged curve is partly caused by the short window (5 seconds) we use to compute throughput. We use a small window so that we can capture relatively short reconfiguration activity. We manually remove inria.fr at t = 62 .
The throughput between t = 60 and t = 85 in Figure 12 shows the effects of regeneration. Because of the failure at t = 62 , the system is not able to properly process writes accepted shortly after this point. The system begins regeneration when the failure is detected at t= 69 . The failure-induced reconfiguration shrinking the configuration takes 13 seconds, of which 3.7 is consumed by the application of pending writes. The failure-free reconfiguration that expands the configuration to include lbl.gov takes 1.3 seconds. After the reconfiguration, the throughput gradually increases to its maximum level as the two-phase pipeline for writes fills.
|
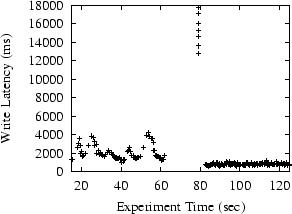
To better understand these results, we plot per-write latency in Figure 13. The gap between t = 62 and t = 82 is caused by system regeneration when the system cannot process writes (from t= 62 to t=69 ) or rejects writes (from t=69 to t=82 ). At t=80 , those seven writes submitted between t=62 and t=69 return with relatively high latency. These writes have been applied as pending writes in the new configuration.
We also perform additional experiments showing similar results when regenerating three replicas instead of one replica. Overall, we believe that regenerating in 20 seconds can be highly effective for a broad array of services. This overhead can be further reduced by combining the failure detection phase (7 seconds) with the ``ProbeMember'' phase in failure-induced reconfiguration, potentially reducing the overhead to 13 seconds.
RAMBO [15,23] explicitly aims to support reconfigurable quorums, and thus shares the same basic goal as Om. In RAMBO, configuration not only refers to a particular set of replicas, but also includes specific quorum definitions used in accessing the replicas. In our system, the default scheme for data accessing is read-one/write-all. RAMBO also uses a consensus protocol (Paxos [21]) to uniquely determining the next configuration. Relative to RAMBO, our design has the following features. First, RAMBO only performs failure-induced reconfigurations. Second, RAMBO requires a majority of replicas to reconfigure. On the other hand, Om can reconfigure from any single replica at the cost of a small probability of violating consistency. Finally, in RAMBO, both reads and writes proceed in two phases. The first phase uses read quorums to obtain the latest version number (and value, in the case of reads), while the second phase uses a write quorum to confirm the value. Thus, reads in RAMBO are much more expensive than ours. Om avoids this overhead for reads by using a two-phase protocol for write propagation.
A unique feature of RAMBO is that it allows accesses even during reconfiguration. However, to achieve this, RAMBO requires reads or writes to acquire appropriate quorums from all previous configurations that have not been garbage-collected. To garbage-collect a configuration, a replica needs to acquire both a read and a write quorum of that configuration. This means that whenever a read quorum of replicas fail, the configuration can never be garbage-collected. Since both reads and writes in RAMBO need to acquire a write quorum, this further implies that RAMBO completely blocks whenever it loses a read quorum. Om uses lease graphs to avoid acquiring quorums for garbage-collection. If Om uses the same read/write quorums as in RAMBO, Om will regenerate (and thus temporarily block accesses) only if RAMBO blocks.
Related to replica group management, there has been extensive study on group communication [3,5,19,24,28,29,31] in asynchronous systems. A comprehensive survey [7] is available in this space. Group communication does not support read operations, and thus does not need leases or a two-phase write protocol. On the other hand, Om does not deliver membership views and does not require view synchrony. The membership in the configuration can not be considered as a view, since we do not impose virtual synchrony relationship between the configurations and writes.
The group membership design in [31] uses ideas similar to failure-free reconfiguration (called update) and failure-induced reconfiguration (called reconfiguration). However, updates in [31] involve two phases rather than a single phase in our failure-free reconfiguration. In fact, their updates are similar to Om writes. Furthermore, the reconfiguration process in [31] involves re-applying pending ``updates''. Our design avoids this overhead by using appropriate manipulation [42] on the sequence numbers proposed by failure-free and failure-induced reconfigurations.
In standard replicated state machine techniques [37], all writes go through a consensus protocol and all reads contact a read quorum of replicas. With a fixed set of replicas, a read quorum here usually cannot be a single replica. Otherwise the failure of any replica will disable the write quorum. In comparison, with regeneration functionality and the lease graph, Om is able to use a small read quorum (i.e., a single replica). Om also uses a simpler two-phase write protocol in place of a consensus protocol for normal writes. Consensus is only used for reconfiguration.
Similar to the witness model, voting with witnesses [26] allows the system to compose a quorum with nodes other than the replicas themselves. However, voting with witnesses still uses the simple majority quorum technique and thus always requires a majority to proceed. The same is true for Disk Paxos [14] where a majority of disks is needed.
Motivated by the need for consistent replica regeneration, this paper presents Om, the first read/write peer-to-peer wide-area storage system that achieves high availability and manageability through online automatic regeneration while still preserving consistency guarantees. We achieve these properties through the following three novel techniques: i) single replica regeneration that enables Om to achieve high availability with a small number of replicas; ii) failure-free reconfigurations allowing common-case reconfigurations to proceed within a single round of communication; and iii) a lease graph and two-phase write protocol to avoid expensive consensus for normal writes and also to allow reads to be processed by any replica. Experiments on PlanetLab show that consistent regeneration in Om completes in approximately 20 seconds, with the potential for further improvement to 13 seconds.
We thank the anonymous reviewers and our shepherd, Miguel Castro, for their detailed and helpful comments, which significantly improved this paper.
|
This paper was originally published in the
Proceedings of the First Symposium on Networked Systems Design and Implementation,
March 29–31, 2004, San Francisco, CA, USA Last changed: 22 March 2004 ch |
|