
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
NSDI '04 Paper
[NSDI '04 Technical Program]
Design, Implementation, and Evaluation of
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Jeffrey C. Mogul |
| HP Labs |
| Palo Alto, CA 94304 |
| JeffMogul@acm.org |
| Yee Man Chan |
| Stanford Human Genome Center |
| Palo Alto, CA 94304 |
| ymc@shgc.stanford.edu |
| Terence Kelly |
| HP Labs |
| Palo Alto, CA 94304 |
| terence.p.kelly@hp.com |
NOTE: this HTML version is not necessarily accurate, and many of the graphs look horrible. Please treat the PDF version of this paper as the definitive version.
Organizations use Web caches to avoid transferring the same data twice over the same path. Numerous studies have shown that forward proxy caches, in practice, incur miss rates of at least 50%. Traditional Web caches rely on the reuse of responses for given URLs. Previous analyses of real-world traces have revealed a complex relationship between URLs and reply payloads, and have shown that this complexity frequently causes redundant transfers to caches. For example, redundant transfers may result if a payload is aliased (accessed via different URLs), or if a resource rotates (alternates between different values), or if HTTP's cache revalidation mechanisms are not fully exploited. We implement and evaluate a technique known in the literature as Duplicate Transfer Detection (DTD), with which a Web cache can use digests to detect and potentially eliminate all redundant payload transfers. We show how HTTP can support DTD with few or no protocol changes, and how a DTD-enabled proxy cache can interoperate with unmodified existing origin servers and browsers, thereby permitting incremental deployment. We present both simulated and experimental results that quantify the benefits of DTD.
Web caches are widely used to save bandwidth and improve latency. However, numerous studies have shown that, in practice, forward proxy caches (i.e., shared Web caches used near clients) incur miss rates of 51-70%, and byte-weighted miss rates of 64-86% [40,27]. Even warm caches with infinite storage cannot eliminate all misses.
In this paper, we are specifically concerned with redundant payload transfers, i.e., cases where a payload is transmitted to a recipient that has previously received it. In a traditional Web cache, each cache entry is indexed by a given URL. If a subsequent request arrives for that URL, and the cache cannot satisfy the request (it ``misses''), it forwards the request to the origin server, which normally generates a reply containing a payload (Section 4.2 gives a careful definition for ``payload''). If that exact payload has previously been received by the cache, we define this as a redundant payload transfer.
Others have identified the problem of redundant payload transfers on the World Wide Web, quantified its prevalence, and explored a range of possible solutions [2,16,28]. According to one measurement, over 20% of payload transfers between origin servers and proxies are redundant [16].
We do not know all causes of redundant transfers. Many result from three common phenomena: aliasing, in which the same content is referenced under two different URLs; rotation, in which the same content is referenced twice under a single URL, but an intervening reference to that URL resolves to different content; and absent or faulty metadata that causes avoidable revalidation failures.
We previously proposed a technique called Duplicate Transfer Detection (DTD) [16] that allows any Web cache to potentially eliminate all redundant payload transfers, regardless of cause. DTD uses message digests to detect redundant transfers before they occur. In its use of digests to detect duplication, DTD is similar to approaches developed for other contexts, e.g., router-to-router packet transfers [32] and file systems for low-bandwidth environments [23]. Unlike an alternative proposal for eliminating redundant HTTP transfers [28], DTD does not require soft state that scales with the number of clients and the size of responses.
In [16] we did not propose a concrete protocol design or describe an implementation of DTD, nor did we measure its impact on client latency. In this paper, we show how one can use standard HTTP, with few or no explicit protocol changes, to support DTD without relying on any additional semantics, naming mechanisms, validation mechanisms, or cooperation with or between origin servers. This allows a DTD-enabled cache to interoperate with unmodified existing origin servers and browsers, thereby permitting smooth, incremental deployment. We describe how to implement DTD in a Web cache, and report on experiments showing that it can accomplish its goal of completely eliminating redundant transfers. We quantify the benefits of DTD using both experimental measurements of our implementation, and simulation results.
The main contributions of this paper are a well-defined protocol specification for DTD, the design of a real implementation of DTD, and performance evaluations of DTD.
Our DTD proposal does not reduce the number of times an HTTP cache must contact an origin server; it only reduces the number of response bodies that must be transferred. What makes this worthwhile?
Eliminating redundant transfers can improve at least four metrics:
In our previous study, using two large real-world traces, we showed that roughly 20% of payload transfers between origin servers and proxy caches are redundant [16]. Therefore, a solution to the redundant-transfer problem could yield significant savings on some or all of the metrics listed above. In this paper, we concentrate on quantifying these improvements.
The first published suggestion to eliminate redundant HTTP payload transfers using message digests, and a trace-based evaluation of its impact on Web cache hit rates, appeared in [15]. A recent unpublished undergraduate dissertation [4] develops a similar idea for GPRS Web access.
Santos & Wetherall [32] and Spring & Wetherall [33] describe protocol-independent network-level analogues of DTD that employ packet digests to save bandwidth. Muthitacharoen et al. designed a network file system for low-bandwidth environments that performs similar operations on chunks of files [23].
Web caches can use payload digests to avoid wasting storage as well as bandwidth. We have implemented this natural counterpart of DTD (see Section 8) but we are not the first. Bahn et al. report that by using digests to avoid storing redundant copies of payloads a Web cache can reduce its storage footprint by 15% and increase its hit rates [1]. Inktomi Corporation has patented such a scheme [18].
A variety of ``duplicate suppression'' schemes have been proposed for the Web. These differ from DTD chiefly in that 1) they are typically end-to-end mechanisms requiring the participation of orgin servers, whereas DTD can be used hop-by-hop at any level of a cache hierarchy, 2) they avoid the extra round trip that some variants of DTD suffer upon a miss, and 3) they can reduce but not eliminate redundant transfers. Mogul [19] reviews several duplicate suppression schemes (e.g., the Distribution and Replication Protocol (DRP) of van Hoff et al. [38]) and reported that they improve hit rates by modest margins, at best.
Previous studies have shown that redundant payload transfers on the Web are caused by complexities in the relationship between URLs and reply payloads (e.g., aliasing and rotation) [16], and by deficiencies in cache management algorithms and server-supplied metadata [41,42].
Rhea et al. describe a sophisticated generalization of DTD called ``Value-Based Web Caching'' (VBWC) [28]. Whereas DTD operates on entire payloads, VBWC detects and eliminates redundant transfers at finer granularity by employing fingerprints calculated on variable-sized blocks. Block boundaries are computed as in Spring & Wetherall's approach [33]. In VBWC, editing a file affects only payload blocks in the immediate neighborhood of the change, ensuring that minor changes don't eliminate bandwidth savings. Rhea et al. implemented VBWC and evaluated it by polling seventeen popular Web sites; their evaluation also includes comparisons with delta encoding. They did not evaluate VBWC based on an actual client or proxy reference stream.
DTD sometimes entails an additional round trip between client and server, but requires no additional server state. By contrast, VBWC proxies must explicitly track client cache state in order to avoid the extra RTT except in rare circumstances. This is soft state, but it scales with both the number of clients and the size of responses, which makes VBWC less easily deployable than DTD. VBWC is also harder to evaluate using anonymized traces, because existing traces that include only MD5 digests of response bodies cannot be used to compute partial-payload fingerprints.
VBWC was designed to be run between an ISP's proxy and the end clients. While DTD can be used server-to-client or server-to-proxy, it can also be used proxy-to-client or proxy-to-proxy. In the latter cases, DTD imposes a store-and-forward cost (for computing the digest at the first proxy) on the entire payload, while VBWC's store-and-forward costs are per-block and thus potentially smaller. We do not yet know how significant these overheads are.
Motivated by the wish to eliminate redundant HTTP transfers, we proposed ``Duplicate Transfer Detection'' (DTD). This solution applies equally to all redundant payload transfers, regardless of cause. Here we provide an overview of DTD (derived from [16]), and discuss several general design issues. In Section 5, we will present a more detailed protocol design, showing how DTD can be defined as a simple, compatible extension to HTTP/1.1 [9].
First, consider the behavior of a traditional HTTP cache, which we
refer to as a ``URL-indexed'' cache, confronted with a request
for URL ![]() . If the cache finds that it does not currently hold an
entry for that URL, this is a cache miss, and the cache issues or
forwards a request for the URL towards the origin server, which would
normally send a response containing payload
. If the cache finds that it does not currently hold an
entry for that URL, this is a cache miss, and the cache issues or
forwards a request for the URL towards the origin server, which would
normally send a response containing payload ![]() . (If the cache
does hold an expired entry for the URL, it may send a ``conditional''
request, and if the server's view of the resource has not changed, it
may return a ``Not Modified'' response without a payload.)
. (If the cache
does hold an expired entry for the URL, it may send a ``conditional''
request, and if the server's view of the resource has not changed, it
may return a ``Not Modified'' response without a payload.)
Now suppose that an idealized, infinite cache retains in storage every payload it has ever received, whether or not these payloads would be considered valid cache entries. A finite, URL-indexed cache differs from this idealization because it implements both an update policy (it only stores the most recent payload received for any given URL), and a replacement policy (it only stores a finite set of entries).
The concept behind Duplicate Transfer Detection is quite simple: If
our idealized cache can determine, before receiving the server's
response, whether it had ever previously received ![]() , then we can
avoid transferring that payload. Such a cache would suffer only
compulsory misses and would never experience redundant transfers.
A finite-cache realization
of DTD would, of course, also suffer capacity misses.
, then we can
avoid transferring that payload. Such a cache would suffer only
compulsory misses and would never experience redundant transfers.
A finite-cache realization
of DTD would, of course, also suffer capacity misses.
How does the cache know whether it has received a payload ![]() before the server sends the entire response? In DTD, the server
(origin server or intermediate proxy cache) initially replies
with a digest
before the server sends the entire response? In DTD, the server
(origin server or intermediate proxy cache) initially replies
with a digest ![]() of the payload, and the cache checks to see if
any of its entries has a matching digest value. If so, the cache can
signal the server not to send the payload (although the server must
still send the HTTP message headers, which might be different).
Thus, while DTD does not avoid the request and response message
headers for a cache miss, it can avoid the transfer of any payload it
has received previously. We say a ``DTD hit'' occurs when DTD
prevents a payload transfer that would have occurred in a
conventional URL-indexed cache.
of the payload, and the cache checks to see if
any of its entries has a matching digest value. If so, the cache can
signal the server not to send the payload (although the server must
still send the HTTP message headers, which might be different).
Thus, while DTD does not avoid the request and response message
headers for a cache miss, it can avoid the transfer of any payload it
has received previously. We say a ``DTD hit'' occurs when DTD
prevents a payload transfer that would have occurred in a
conventional URL-indexed cache.
An idealized DTD cache stores all payloads that it has
received, and is able to look up a cached payload either by URL or by
payload digest. In particular, it does not delete a payload ![]() from storage simply because it has received a different payload
from storage simply because it has received a different payload
![]() for the same URL
for the same URL ![]() . A realistic DTD cache, with finite
capacity, may eventually delete payloads from its storage, based on
some replacement policy.
. A realistic DTD cache, with finite
capacity, may eventually delete payloads from its storage, based on
some replacement policy.
We have described DTD as operating on ``payloads.'' In order to precisely specify DTD, we must also precisely specify the term ``payload.'' That is, over what set of bytes is a digest calculated?
HTTP servers (the term ``server'' includes both origin servers and proxies) can send response messages containing either the full current value of a resource, a partial response containing one or more sub-ranges of the full value, or more complex partial responses (such as with delta encoding [21] or rsync [37]). HTTP responses can also be encoded using various compression formats, or with ``chunked'' encoding.
Whatever the format of the response, the ultimate client almost always wants to obtain a full current value of the referenced resource.1One of us introduced the term ``instance'' to mean ``The entity that would be returned in a status-200 response to a GET request, at the current time, for [...] the specified resource,'' in an IETF standards-track document specifying how to extend HTTP/1.1 to support ``instance digests'' [20]. An instance consists of an ``instance body'' and some ``instance headers.''
Our DTD design equates ``payloads'' and ``instance bodies.'' That is, servers provide instance digests, and a cache entry is indexed by the digest of the instance body it stores.
One could imagine an alternative in which DTD's digests are computed on HTTP message bodies, which might be partial responses. However, this seems less likely to eliminate redundant transfers; two partial responses for the same instance might not span the same range.
The ``payloads are instance bodies'' model works nicely with partial
responses. For example, if a client requests bytes 0-10000 of URL
![]() , and the server responds with a digest of the entire instance
body, a DTD client checks its cache for a matching instance digest. If
such an entry is found, the transfer can be avoided; the client can
easily extract the required byte-range from its cache entry, rather
than relying on the server's extraction.
, and the server responds with a digest of the entire instance
body, a DTD client checks its cache for a matching instance digest. If
such an entry is found, the transfer can be avoided; the client can
easily extract the required byte-range from its cache entry, rather
than relying on the server's extraction.
Nothing in the DTD design prevents a cache from computing digests on non-instance data (such as partial responses, encoded responses, etc.) and matching incoming instance digests against cached non-instance data. Our intuition, however, is that such matches will occur too rarely to justify the additional overhead.
DTD is best thought of as a hop-by-hop optimization of HTTP caching,2 which can be implemented between any HTTP server and client (either one of which could be a proxy; DTD can be implemented between any data sender and receiver). In particular, DTD can be deployed unilaterally by an organization that controls both browser and proxy caches, e.g., AOL or MSN. It can also be deployed incrementally by any implementor of clients, servers, or proxies, because it is always optional for either end of a transfer. In the experiments described in Section 9 we demonstrate that DTD can be enabled purely through proxy modifications, if the origin server supports digest generation.
DTD's main requirement for server implementors is to compute and send
instance digests. The algorithm used to compute the digest value ![]() must not use too much server CPU time, and the digest representation
must not consume too many bytes, or else the cost of speculatively
sending digests will exceed the benefits of the DTD hits. Also, the
digest must essentially never yield collisions,
or else the client could end up with
the wrong payload. A cryptographic hash algorithm such as
MD5 [29] might have the right properties. We will assume
the use of MD5 for this paper; Section 10.1 covers
some issues in the choice of digest algorithm.
must not use too much server CPU time, and the digest representation
must not consume too many bytes, or else the cost of speculatively
sending digests will exceed the benefits of the DTD hits. Also, the
digest must essentially never yield collisions,
or else the client could end up with
the wrong payload. A cryptographic hash algorithm such as
MD5 [29] might have the right properties. We will assume
the use of MD5 for this paper; Section 10.1 covers
some issues in the choice of digest algorithm.
Note that DTD does not inherently require the client to compute any digests, if all servers send digests. However, to check against transmission errors or servers sending bogus digests, clients should probably compute digests anyway (see Section 10).
Our previous paper [16] briefly covered protocol design issues for DTD. In this section, we expand that discussion, including mechanisms for suppressing data transfer and specific HTTP mechanisms to support DTD.
One key aspect of DTD is the mechanism by which the client avoids
receiving a payload, if the digest ![]() matches an existing cache
entry. This could be accomplished by deferring the transfer until the
digest can be checked, or by aborting the transfer in progress if the
digest matches some cache entry.
matches an existing cache
entry. This could be accomplished by deferring the transfer until the
digest can be checked, or by aborting the transfer in progress if the
digest matches some cache entry.
In the first category of approaches, the server sends the response headers but defers sending the payload until the client sends an explicit ``proceed'' message. In the other category, the server sends the payload immediately after the headers, but stops if the client sends an ``abort'' message. The ``proceed'' model imposes an extra round-trip time (RTT) on every cache miss, but never sends any redundant payload bytes. The ``abort'' model imposes no additional delays, but the abort message may fail to reach the server in time to save any bandwidth. Thus, the choice between alternatives requires consideration not only of implementation issues, but also of the magnitude of the RTT, and whether one is more concerned with optimizing bandwidth utilization or latency.
Each of these basic models allows several alternatives. These include:
Note that in the proceed model, not every payload need be delayed. Web pages often include multiple images; for example, we previously found 8.5 image references per HTML reference in an uncached reference stream, and 1.9 images per HTML reference in a client-cached stream [16]. A client that pipelines [26] its requests for images can also pipeline its ``proceed'' messages. Thus, the extra RTT delay can be amortized over all of the images on a Web page, rather than being paid once per image.
In this paper, we examine only the pure-proceed model, for reasons of space and simplicity.
The changes required to extend HTTP/1.1 [9] to support DTD depend on which transfer-suppression approach is chosen. The ``pure proceed'' approach to DTD can be implemented without any changes to HTTP/1.1 beyond existing IETF standards-track proposals.
The client first uses mechanisms specified in the Proposed Standard for instance digests [20] to obtain current instance headers, including an instance digest. It obtains these via a HEAD request, which prevents the server from sending an instance body [9, Section 9.4]. If the client finds no cache entry with a matching instance digest, or if a non-DTD server fails to return a digest, the client simply issues a GET request to obtain the full instance body.
This protocol design, while simple, has several drawbacks:
Figure 1 shows an example of the HTTP messages between a client and server for a DTD miss. For a DTD hit, the second pair of messages would simply be omitted. The Want-Digest and Digest headers are described in RFC 3230 [20]; all other headers are standard in HTTP/1.1 [9].
Using Want-Digest and Digest is the ``right'' implementation of DTD, because it works even for partial-content responses, is extensible to digest algorithms other than MD5, and avoids unnecessary digest computations at the origin server. But since RFC 3230 is not widely implemented, we tested DTD using the Content-MD5 support available in major Web servers (e.g., Apache and IIS). This is sub-optimal because it does not allow the server to avoid computing MD5s when the client has no use for them.
The pure-proceed approach is equally usable hop-by-hop or end-to-end, because any intermediate proxy can generate or check digests. (A proxy-to-proxy implementation must use Digest because HTTP/1.1 [9, section 14.15] specifically prohibits proxies from adding Content-MD5.) Note that proxy-to-client or proxy-to-proxy DTD could impose an extra store-and-forward delay, while the first proxy computes the digest header. (Some existing proxies might already buffer short responses, in any case.)
Section 9 presents measured performance of an actual DTD implementation. However, those measurements are driven from a synthetic reference stream, which cannot prove how frequent redundant transfers are in real-world workloads. Here we analyze two real-world traces to show how many redundant transfers, and how many bytes, could be eliminated by DTD.
Relatively few existing client and proxy HTTP traces include the response body digests we needed for our analysis. For example, the trace used by Douglis et al. [5] may have been lost in a disk crash; other such traces are unavailable due to proprietary considerations. We re-analyzed the anonymized client and proxy traces from our prior study [16]. These were collected, respectively, at WebTV Networks in September 2000 and at Compaq Corporation in early 1999. The WebTV trace was made with client caches disabled; both traces were made without proxy caching. Both traces include an MD5 digest for each payload transferred. The WebTV trace includes 326 million references from 37 thousand clients to 33 million URLs on 253 thousand servers over sixteen days; the Compaq trace includes 79 million references from 22 thousand clients to 20 million URLs on 454 thousand servers over 90 days. Many further details of these traces are described in [16] and are omitted here for space reasons.
Given a request for URL ![]() that results in reply
instance body
that results in reply
instance body ![]() , the following properties may or
may not hold:
, the following properties may or
may not hold:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
We analyzed both the WebTV and Compaq traces according to this categorization. The results are in Tables 1 and 2 respectively. The cold-start results cover the entire traces. Consistent with our earlier methodology [16], for the warm-start results we (only somewhat arbitrarily) warm the simulated cache with the first 186 million references (for WebTV) or 50 million references (for Compaq).
In the WebTV warm-start results, 10% of the transfers involve payloads never before seen in the trace (``new payloads''); these will miss in any kind of cache. Another 87% have property (iv), for which a traditional, infinite cache with perfect revalidation would avoid a payload transfer. (This ``hit rate'' seems high, but remember that the WebTV trace was made with client caches disabled.) The remainder, about 3%, are transfers that DTD would avoid. In other words, a traditional URL-indexed cache would see a miss rate of at least 13%, compared to a DTD-cache miss rate of 10%; DTD would eliminate 23% of a conventional cache's misses.
In the Compaq warm-start results, 37% are new payloads, and 55% have property (iv). The remainder, about 8%, are transfers that DTD would avoid. A traditional cache would see a miss rate of 45%, versus a DTD-cache miss rate of 37%; DTD would eliminate roughly 18% of a conventional cache's misses for this trace.
If we restrict the DTD implementation to save at most one entry per URL (i.e., to store no more entries than a traditional cache), then the DTD cache will require transfers for properties (ii) and (iii), but will still avoid transfers for property (i). In this situation, DTD would avoid 2.6% of the transfers in the WebTV trace, and 5.8% of the transfers in the Compaq trace, assuming a warm cache. (These values are the sums of the Warm-start Transfers column for rows where property (i) holds and property (iv) does not.)
Weighting the results by bytes transferred better describes bandwidth savings, of course. Looking just at the warm-cache data, new (i.e., mandatory-transfer) payloads account for 30% of the WebTV bytes, and 57% of the Compaq bytes. Variations of property (iv), hits for a perfect traditional cache, account for 64% of the WebTV bytes, and 34% of the Compaq bytes. The transfers that DTD would avoid account for 5% of the WebTV bytes, and 9% of the Compaq bytes.
In other words, a traditional URL-indexed cache would see a byte-weighted miss rate of at least 36% for the WebTV trace, compared to a DTD-cache miss rate of 30% (66% vs. 57% for the Compaq trace). In terms of the reduction in the number of bytes sent from the origin server, DTD would save (relative to a URL-indexed cache) 15% for the WebTV trace, and 14% for the Compaq trace.
Because the proceed model for DTD causes an extra pair of request and response headers when the digest does not match, to evaluate the overall byte-transfer savings for this model we must compare the bytes saved by DTD (for properties (ii) and (iii)) with the number of extra header bytes spent on the new-payload transfers. We can ignore property (iv) by assuming that these references could be cache hits. DTD (warm-start) saves a mean of 3036 bytes of payload transfer for each new-payload reference in the WebTV trace (warm-start), and 2857 bytes for each new-payload reference in the Compaq trace. These savings are much larger than the mean request+response header sizes reported in previous studies (e.g., [6,13]) 3 so the proceed model does not waste too much of the potential savings.
DTD requires digests in response headers (for MD5, 24 bytes plus about 10 bytes of syntax overhead), which further reduces savings. However, digests are useful for integrity checks, and so might be sent even without DTD.
HTTP/1.1 supports the use of entity tags to validate cache entries: a server may provide an instance-specific entity tag in the ETag response header, and a client may send this entity tag back to the server in an If-None-Match request header to check if its cache entry is still valid. If-None-Match may carry multiple entity tags, in which case the server can return ``304 Not Modified'' (along with the current entity tag) if any of those tags is current.
This feature would allow a non-DTD cache to avoid transfers when property (iii) holds. Referring to the warm-start columns in Tables 1 and 2, we see that this could avoid at most 0.6% of the transfers and 2.6% of the bytes for the WebTV trace, and 2.9% of the transfers and 1.7% of the bytes for the Compaq trace.
However, these are upper bounds, since this simple analysis assumes that every response carries an entity tag, and the servers always use exactly one entity tag per distinct instance body. Neither is true in practice; only 66% of the responses in the WebTV trace carried entity tags, and we know that some servers can assign different entity tags to identical instance bodies. In summary, DTD avoids transferring significantly more bytes than could be avoided using multiple entity tags in If-None-Match.
The full benefit of DTD accrues when the cache stores more than one payload per URL. The most natural clean-slate DTD cache design treats payloads rather than URLs as the basic storage type. URLs are merely one way to index into this underlying store; payload digests are another. The cache may therefore store multiple payloads for a given URL, and also payloads that are not the most-recent response for any URL (as in the case of rotated resources). These properties, while desirable, might be difficult to retrofit onto some legacy cache implementations; how much do they help? It helps for references that have either property (ii) or (iii) while having neither property (i) nor (iv). These represent just 0.4% of the warm-start transfers in the WebTV trace, but 2.5% of the warm-start transfers in the Compaq trace, so it probably is useful to store multiple payloads per URL.
The analysis in Section 6 concentrates on the number of bytes that could be saved using DTD, which may be of economic interest to network operators. End users, however, care more about latency. Predicting the latency effects of change to Web protocols can be difficult, since so many variables can affect overall latency.
We have developed a simple model for understanding when pure-proceed DTD might improve latency over a traditional Web cache. This model ignores issues such as response pipelining, network congestion, TCP algorithms such as slow-start, and correlations of the hit ratio and duplication ratio with other parameters, but it can help guide intuition.
Given these parameters:
We simplify by assuming that
![]() , a reasonable
approximation for a well-implemented cache.
, a reasonable
approximation for a well-implemented cache.
We can then express the expected latencies for conventional
and DTD caches:
| |||||||||||||||||||||||||||||||||||
We evaluated Equation 1 using warm-cache hit-ratio values taken from the WebTV and Compaq trace analyses in Tables 1 and 2 and various combinations of RTT and bandwidth. Table 3 shows the results for several scenarios: ``cellphone,'' ``modem,'' ``DSL,'' and ``WAN,'' corresponding respectively to the results shown later in Figures 4(a), 4(b), 4(c), and 6. The break-even response sizes shown in the table imply that DTD would improve latency on cellphone and modem links, and perhaps on DSL links, given the typical mean response sizes summarized in Table 4 of [16]. DTD would hurt latency on high-speed WAN links except if its use were restricted to relatively large responses.
Most of the new code required for DTD, using the proceed model, is located in cache implementations. (We also needed server support for digests; we relied on existing support for Content-MD5, which is only partially appropriate; see Section 5.2.) Both clients (browsers) and proxies have caches; for our experiments, we limited ourselves modifying a proxy cache server. By running a ``private'' proxy cache co-located with a browser, we can emulate most of the benefits of integrating DTD into a browser cache. (It should be simpler to add DTD to a browser cache than it was to add it to a proxy cache.)
We chose to implement the pure-proceed approach to DTD as modifications to the Squid proxy server [34] (version 2.4.STABLE7). Our code is available from https://devel.squid-cache.org/dtd/. The major changes we made are:
Our modified Squid uses ``Duplicate Storage Avoidance'' (DSA). Each distinct payload (i.e., with a given digest) is stored only once; if the payload is current for several URLs, the URL-indexed entries incorporate the payload by reference (see https://devel.squid-cache.org/dsa/).
The DTD and DSA changes together involve about 3420 lines of mostly simple but tedious ``diffs'' to Squid; much of the new code represents modified versions of existing Squid code. About one third of the new lines are pre-processor directives (e.g., ``#ifdef'').
A cache that supports partial content (HTTP status-206 responses) must be careful not to associate an entire-instance digest with a stored partial-instance body, or else DTD could unwittingly supply incomplete bodies. Our implementation does not yet support partial content.
In hindsight, the choice to modify Squid may have been a mistake. The existing Squid code is extremely complex and hard to understand, and we found many bugs in our own code that resulted from our failure to maintain poorly documented invariants expected by the rest of Squid. We know some bugs remain.
The analysis in Section 6, based on traces of real users, predicts the bandwidth savings from DTD, but cannot tell us how DTD affects latency. To help answer this question, we ran experiments using our modified version of Squid.
We tested our DTD implementation in two different environments The first was an ``Emulated-WAN'' environment, in which the two systems (server, proxy+client) were physically close, and connected by a 10 Mbit/sec LAN. We then emulated a variety of WAN environments using the Dummynet [30] feature of FreeBSD, which allowed us to choose a variety of latency and bandwidths between the server and proxy, enabling us to measure how DTD performance varies with network characteristics. The second was a ``Real-WAN'' environment, using a server at Worcester Polytechnic Institute (WPI) in Massachusetts, while the DTD-capable proxy and the client ran on a system at the University of Michigan.
In our tests, we ran the proxy (modified or unmodified) on the same system as the client, to simulate the use of a client cache with or without support for DTD. All systems were otherwise unloaded, except for the real-WAN origin server.
All of the hosts ran Linux, except for the emulated-WAN server which ran FreeBSD. The server at WPI uses Apache/1.3.12, while the emulated-WAN server uses Apache/2.0.47. For the emulated-WAN experiments, the proxy/client was a 550 MHz Pentium III and the server was a 466 MHz AlphaServer DS10L. For the real-WAN experiments, the proxy/client was a 4-CPU 450 MHz Pentium II and the server was a 600 MHz Pentium III.
We measured a mean RTT of 42 msec for the real-WAN path, and approximate effective bandwidths from 6.1 to 7.7 Mbits/sec. In the emulated-WAN tests, we used Dummynet to impose symmetric RTTs of 0, 30, and 100 msec, and bandwidth limits of 10K, 56K, 384K, 1.5M, and 10M bits/sec.
We ran trials with file (body) sizes (not including HTTP headers) of
![]() bytes, for
bytes, for
![]() ; i.e., between
1KB and 1MB.4Each file byte was derived from a pseudo-random number generator,
thus making it difficult for any network element (such as a
modem) to compress the files and change their effective transfer
sizes.
; i.e., between
1KB and 1MB.4Each file byte was derived from a pseudo-random number generator,
thus making it difficult for any network element (such as a
modem) to compress the files and change their effective transfer
sizes.
For each combination of network characteristics and body size, we ran experiments using three different proxy configurations: no proxy, unmodified Squid, and our DTD-capable modified Squid proxy. With unmodified Squid, we ran trials where the references were arranged to be compulsory cache misses, and trials where the references were guaranteed to be cache hits. With our DTD-capable Squid, we ran compulsory-miss, guaranteed-hit, and DTD-only-hit trials; the last category were references where we arranged that the cache contained an entry with a matching digest value, but not a matching URL. We arranged compulsory cache misses by restarting the proxy software with a cold cache as necessary; we arranged guaranteed hits by careful choice of the reference sequence, and by ensuring that the working set was much smaller than the cache size.
In each set of experiments, we measured end-to-end response time using
httperf [22].
This program reports the latency between issuing a request and receiving
the first byte of the response headers (time-to-first-byte, or TTFB),
as well as the latency between receiving the first byte of the
response headers and the last byte of the response body (transfer
duration, or TD). For the 1KB body size, the headers and body
might fit into one packet, in which case TD would be negligible.
The total response latency is thus TTFB![]() TD.
In each trial, we used httperf to fetch ``bunches'' of 10
distinct files with the same length.
TD.
In each trial, we used httperf to fetch ``bunches'' of 10
distinct files with the same length.
For
a given network configuration, we measure latencies for one
bunch for each combination of body size and proxy configuration,
then repeat that set of measurements ![]() times.
Results in this paper show the mean for
times.
Results in this paper show the mean for
![]() unless otherwise noted.
unless otherwise noted.
The use of a proxy server introduces overheads that would not be present if our DTD implementation were integrated into a client cache. Also, Squid is known to add significant latency due to fundamental design choices [17]. We can estimate the overheads imposed by our implementation strategy of using Squid rather than an integrated client cache; we do this by comparing the no-proxy latencies with the latencies for cache-miss retrievals via unmodified Squid.
Figure 2 shows the overheads imposed by unmodified Squid connected to the server over both a full-speed LAN and over the WAN path described above. In the LAN case, Squid adds almost no latency larger than the trial-to-trial measurement errors (which cause some of the negative ``overheads'' in Figure 2(a); these errors are below 2% of the total latencies). Overheads from our WAN tests (Figure 2(b)) are harder to interpret, although using unmodified Squid seems to consistently improve the transfer times for most body sizes. This effect also holds when we run experiments using an emulated WAN with similar delay and bandwidth. We cannot offer a plausible explanation, but because most of the results in this paper compare performance for our modified Squid against the unmodified version, rather than against the no-proxy case, we leave this mystery to others.
On our LAN, the TTFB latency difference between a Squid miss and a no-proxy operation, for most body sizes, is about 1 msec. This places an upper bound on the cache-lookup latency, because Squid imposes other overheads beyond this lookup, and so confirms our assumption in Section 7 that the lookup latency is negligible.
DTD requires the origin server to send the digest of the payload (body). In our experiments, we use the MD5 digest algorithm, whose computation imposes some cost [36]. In principle, servers could cache MD5 computations for frequently-accessed content. Also, Moore's Law suggests that MD5 computation will decline in cost relative to speed-of-light latencies. However, current servers (such as Apache) do not cache MD5 values, so the use of DTD adds this computational overhead. We quantified the cost by comparing the latencies for no-proxy retrievals with and without MD5 computation enabled at the Apache server.
Figure 3 shows the overheads that MD5 imposes for a LAN-based, proxyless configuration. For bodies smaller than 128 KBytes, the overheads are negligible (under 3 msec). For larger bodies, MD5 computation adds measurable overhead, but still less than a tenth of the absolute response time (e.g., 1218 msec for 1024-byte bodies). The increase in response time is smaller than the increase in TTFB for these larger sizes, probably because the MD5 pass effectively prefetches the file into the server's file buffer; this prefetching (as Figure 3 implies) makes the TCP transfer slightly more efficient.
(a) 100 msec RTT, 10 Kbits/sec
(body size limited to 128 KBbytes, to keep experiment durations
reasonable)
(b) 100 msec RTT, 56 Kbits/sec (e.g., typical modem)
(c) 30 msec RTT, 384 Kbits/sec (e.g., typical DSL)
(d) 100 msec RTT, 10 Mbits/sec (bad case for DTD) |
Figure 4 shows
time-to-first-byte and total response time results, in the
left and right columns respectively, for selected
emulated-WAN experiments. For reasons of space, we only
show results for:
![]() , a plausible cell-phone link;
, a plausible cell-phone link;
![]() , a typical dialup modem;
, a typical dialup modem;
![]() , a DSL connection to a regional server;
and
, a DSL connection to a regional server;
and
![]() ,
a bad case for DTD because the RTT and bandwidth are both high.
,
a bad case for DTD because the RTT and bandwidth are both high.
For all combinations of network parameters that we tested, the TTFB latency for a DTD-only hit is slightly above one RTT (approximately the TTFB of a cache miss), as we would expect from the cost of the HEAD operation. The total response latency for a DTD-only hit is also approximately one RTT, because no body is transferred from origin server to cache. (The cache is co-located with the client, so there is almost no transfer cost between those agents.)
The total latency for compulsory miss by a DTD-capable cache will be one RTT higher than that of a traditional cache. This is clearly visible in the left column of figures (the log scale makes it less visible in the right column, where results are sometimes dominated by bandwidth-induced delays). This is a penalty that a DTD cache must make up by its improved latency on DTD-only hits, with respect to the conventional misses that they displace.
A DTD-only hit should never have a higher total latency than a conventional miss by a non-DTD cache, but it can be much lower if the conventional miss incurs a large transfer cost. For example, in Figure 4(a-c), at a body size of just 8 KBytes, the total latency is significantly lower for a DTD-only hit than for a conventional miss. In Figure 4(d), however, DTD shows no latency benefit except for very large body sizes, because the high bandwidth minimizes transfer cost, while the high RTT dominates total latency.
Note that while Figure 4 shows that DTD-only hits can be much faster than the conventional misses they replace, without knowing the various hit ratios (see Section 7) one cannot infer whether DTD provides a net benefit.
Figure 5 and 6 show, respectively, the
time-to-first-byte and total response time results for our
real-WAN experiments.
(In this experiment, ![]() .)
These results
agree quite closely with our emulated-WAN results
(not shown in Figure 4)
for similar RTT and bandwidth.
.)
These results
agree quite closely with our emulated-WAN results
(not shown in Figure 4)
for similar RTT and bandwidth.
Our experimental results generally confirm the analytic model in Section 7, although our experiments do not attempt to model miss ratios.
We can evaluate whether DTD is beneficial at a particular
point in the parameter space. For this example, we assume the
miss ratios reported from the WebTV trace in Section 6,
10% for a DTD client cache vs. 13% for a conventional client cache,
and assume that these ratios are independent of response size.
Using the results in Figure 4(b),
a modem user with
![]() who retrieves
a number of 8 KByte files would have a mean expected latency improvement
using DTD of about 15 msec (compared to an overall expected mean,
without DTD,
of 185 msec). The same user retrieving a number
of 32 KByte files would see a mean improvement of 126 msec
(vs. an overall non-DTD mean of 661 msec).
who retrieves
a number of 8 KByte files would have a mean expected latency improvement
using DTD of about 15 msec (compared to an overall expected mean,
without DTD,
of 185 msec). The same user retrieving a number
of 32 KByte files would see a mean improvement of 126 msec
(vs. an overall non-DTD mean of 661 msec).
A user on a slower network, with
![]() ,
would see even larger improvements from DTD. However, a user of
our relatively good WAN connection would see a net latency loss
from DTD for body sizes below a break-even point of about 64 KBytes.
Since most Web responses are smaller than that,
on good WAN links one might only want to
use DTD for special tasks such as downloading software (the
original motivation for DRP [38]).
,
would see even larger improvements from DTD. However, a user of
our relatively good WAN connection would see a net latency loss
from DTD for body sizes below a break-even point of about 64 KBytes.
Since most Web responses are smaller than that,
on good WAN links one might only want to
use DTD for special tasks such as downloading software (the
original motivation for DRP [38]).
Measures that improve the performance of computing systems often create subtle security vulnerabilities, and caching is a prime example. Timing attacks on processor memory hierarchies have been known for decades, e.g., the famous TENEX password attack [35, pp. 183-4]. Recently Felten et al. have described variants applicable to Web caching [8]. DTD adds at least two additional security problems.
First, if an attacker can generate payload digest collisions, then she can cause a DTD proxy to deliver incorrect payloads. The details are omitted here but are available in [14]. The attack is straightforward and can be prevented through the use of secure message digest functions (see Section 10.1).
A more subtle problem involves information leakage; interestingly, the attack does not rely on timing information of any kind.5A server can exploit DTD to learn the contents of a client's cache:
nosy.com server employ DTD.
https://nosy.com/humdrum.html.
nosy.com replies with digest(naughty.gif),
even though it never receives or serves requests for this
interesting payload.
DTD would be unreliable if the digest function were prone to accidental collisions under normal usage. MD5 might not be sufficient for widespread deployment; if not, one could achieve an arbitrarily low rate of accidental collisions by increasing the hash size, at the cost of slightly higher overheads. (Henson [12] discusses some risks associated with digest-based protocols; we disagree with some of the conclusions in that paper.)
DTD would be vulnerable to attack if it were computationally feasible to generate digest collisions deliberately. Our work has assumed the use of MD5 [29], but MD5's collision-resistance has been questioned [31]. Other algorithms, such as SHA1 [24], might be more appropriate.
We see many possible extensions of this work. We would like to explore and evaluate the protocol alternatives in Section 5, and perhaps to unify DTD with similar techniques such as rsync [37]. We would also like to see the trace-based analysis of Section 6 applied to a broader set of traces. One could also improve on our synthetic benchmarks by using miss-ratio and response-length distributions taken from traces.
Neither our model nor the original Squid code base supports pipelining, which is known to benefit HTTP performance in general [25], and ought to improve the tradeoff in favor of DTD; evaluation of a pipelined DTD cache would require shifting to a new code base.
Because a DTD cache, unlike a traditional cache, might store multiple entries per URL, cache replacement policies designed for traditional caches might interact poorly with DTD. We suspect that the most natural replacement policy for DTD is to redefine an existing policy with respect to unique instances rather than to URLs. While we have not yet evaluated such policies, we believe that a DTD cache with such a policy will not suffer a higher miss rate than a conventional URL-indexed cache with the analogous policy.
This paper has described how Duplicate Transfer Detection can be implemented in HTTP without explicit protocol changes, and briefly sketched several alternative designs. We showed, using two real-world traces, how DTD could reduce miss rates and bandwidth requirements--14% to 15% of the bytes transferred in our traces. We provided a simple model to show when use of DTD should reduce expected latency relative to a conventional cache. We described a simple implementation of DTD for Squid. Using tests of real and emulated WANs, we showed measurements that clarify the conditions under which DTD reduces overall latency. For realistic hit ratios and response sizes, DTD does provide a net latency benefit for some common network environments.
We thank Microsoft for allowing us to study their data, especially Stuart Ozer, Arnold de Leon, and Jay Logue (and others listed in [15]) for gathering the trace, and David Surovell and Jake Brutlag for describing how WebTV client caches work. HP Labs gave us access to the Compaq trace and generous equipment support. Glenn Cooper (HP Labs) and Jeff Kopmanis (U. Michigan AI Lab) provided computer support.
We would especially like to thank Alex Rousskov, for spending late nights adding aliased-content support to Polygraph, and for answering many novice questions. Duane Wessels helped us with Squid. Mikhail Mikhailov lent us a server that made our WAN tests possible, configured it to order, and answered numerous questions. Anja Feldmann, James Hall, and Kevin Jeffay each provided information on request sizes. Fred Douglis, the reviewers from both USITS and NSDI, and our shepherd Geoff Voelker provided helpful comments.
This document was generated using the LaTeX2HTML translator Version 2002 (1.67)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -no_navigation -no_footnode -numbered_footnotes nsdi04web.tex
The translation was initiated by Jeffrey Mogul on 2004-02-09
|
This paper was originally published in the
Proceedings of the First Symposium on Networked Systems Design and Implementation,
March 29–31, 2004, San Francisco, CA, USA Last changed: 18 March 2004 ch |
|

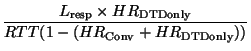
![\includegraphics[height=2.75in,width=5in]{prox_over_lan_mean.eps}](img51.png)
![\includegraphics[height=2.75in,width=5in]{prox_over_wan_mean.eps}](img52.png)
![\includegraphics[height=2.75in,width=5in]{md5_over_mean.eps}](img54.png)
![\includegraphics[height=2.75in,width=5in]{keyonly.eps}](img63.png)
![\includegraphics[height=2.75in,width=5in]{delay100bw10k_resp_mean.eps}](img55.png)
![\includegraphics[height=2.75in,width=5in]{delay100bw10k_total_mean.eps}](img56.png)
![\includegraphics[height=2.75in,width=5in]{delay100bw56k_resp_mean.eps}](img57.png)
![\includegraphics[height=2.75in,width=5in]{delay100bw56k_total_mean.eps}](img58.png)
![\includegraphics[height=2.75in,width=5in]{delay30bw384k_resp_mean.eps}](img59.png)
![\includegraphics[height=2.75in,width=5in]{delay30bw384k_total_mean.eps}](img60.png)
![\includegraphics[height=2.75in,width=5in]{delay100bwfull_resp_mean.eps}](img61.png)
![\includegraphics[height=2.75in,width=5in]{delay100bwfull_total_mean.eps}](img62.png)
![\includegraphics[height=2.75in,width=5in]{wan_resp_mean_ll.eps}](img68.png)
![\includegraphics[height=2.75in,width=5in]{wan_total_mean_ll.eps}](img69.png)