Next: Self-Tuning
Up: Experimental Results
Previous: Experimental Results
In a sufficiently-provisioned, non-overloaded system, the failure and
recovery of a single brick does not affect:
- Correctness. As described above, the failure of a single brick does
not result in data loss. In particular, SSM can tolerate
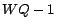 simultaneous brick failures before losing data.
simultaneous brick failures before losing data.
A restart of the brick does not impact correctness of the system.
- Performance. So long as
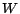 is chosen to be greater than
is chosen to be greater than 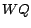 and
and 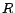 is
chosen to be greater than 1, any given request from a stub is not
dependent on a particular brick. SSM harnesses redundancy to remove
coupling of individual requests to particular bricks.
is
chosen to be greater than 1, any given request from a stub is not
dependent on a particular brick. SSM harnesses redundancy to remove
coupling of individual requests to particular bricks.
A restart of the brick does not impact performance; there is no
special case recovery code that must be run anywhere in the system.
- Throughput. A failure of any individual brick does not degrade system
throughput in a non-overloaded system. Upon first inspection, it
would appear that all systems should have this property. However,
systems that employ a buddy system or a chained clustering system [17,24] fail to balance the resulting load evenly. Consider
a system of four nodes A, B, C, and D, where A and B are buddies, and
C and D are buddies. If each node services load at 60 percent of its
capacity and subsequently, node D fails, then its buddy node C must
attempt to service 120 percent of the load, which is not
possible. Hence the overall system throughput is reduced, even though
the remaining three nodes are capable of servicing an extra 20 percent
each.
Because the resulting load is distributed evenly between the
remaining bricks, SSM can continue to handle the same level of
throughput so long as the aggregate throughput from the workload is
lower than the aggregate throughput of the remaining machines.
The introduction of a new brick or a revived brick never decreases
throughput; it can only increase throughput, as new bricks add
new capacity to the system. A newly restarted brick, like every other
brick, has no dependencies on any other node.
- Availability. In SSM, all data is available for reading and writing
during both brick failure and brick recovery. In other systems such
as unreplicated file systems, data is unavailable for reading or
writing during failure. In DDS [17] and in Harp [27], data
is available for reading and writing after a node failure, but data is
not available for writing during recovery because data is locked and
is copied to its buddy en masse.
SSM is recovery-friendly. In this benchmark, is set to 3, is set to 2, 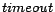 is set
to 60 ms, is set to 2, and the size of state written is 8K.
is set
to 60 ms, is set to 2, and the size of state written is 8K.
We run four bricks in the experiment, each on a different physical
machine in the cluster. We use a single machine as the load
generator, with ten worker threads generating requests at a rate of
approximately 450 requests per second.
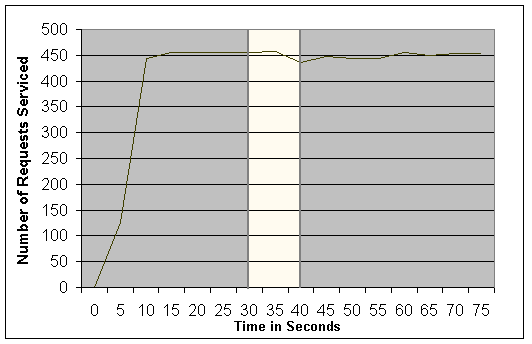
Figure:
SSM running with 4 Bricks. One brick is
killed manually at time 30, and restarted at time 40. Throughput and
availability are unaffected. Although not displayed in the graph, all
requests are all fulfilled correctly, within the specified timeout.
|
We induce a fault at time 30 by killing a brick by hand. As can be
shown from the graph, throughput remains unaffected. Furthermore, all
requests complete successfully; the load generator showed no failures.
This microbenchmark is intended to demonstrate the recovery-friendly
aspect of SSM. In a non-overloaded system, the failure and recovery
of a brick has no negative effect on correctness, system throughput,
availability, or performance. All generated requests completed within
the specified timeout, and all requests returned successfully.
Next: Self-Tuning
Up: Experimental Results
Previous: Experimental Results
Benjamin Chan-Bin Ling
2004-03-04