Safe at Any Speed: Fast, Safe Parallelism in ServersJohn Jannotti and Kiran Pamnany |
Abstract: Many applications take advantage of parallelism to increase performance. Servers are a particularly common case as they must multiplex resources across many simultaneous users. Unfortunately, writing concurrent applications is difficult and prone to subtle and non-deterministic bugs that are difficult to reproduce. We advocate an approach to developing concurrent programs that is safe by default. Conservative static analysis determines when two code segments may safely run in parallel, and a runtime scheduler respects these constraints.
We have built an analyzer for event-driven servers that discovers data sharing to find safe parallelism among event handlers. As a prototype, the analysis currently considers only global data, assuming that request-specific data structures passed to event handlers are completely independent. We have also begun work on a runtime system that schedules event handler execution within the constraints determined by the analyzer. For performance reasons, the scheduler makes additional conservative assumptions about contention.
We have analyzed thttpd, an event-driven web server. We show how our system can be used to increase performance without complex synchronization schemes.
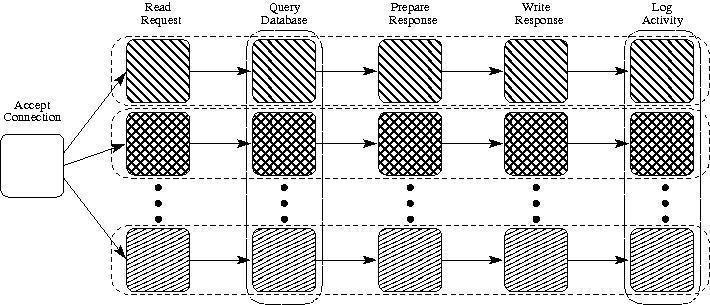
Alternatively, the programmer may split the segment into several individually atomic stages. Figure 1 illustrates a well partioned example in which the work required to process a request is split into six functions. After each connection is accepted, a chain of handlers processes the request. In this case, most handlers are independent across requests, so they may execute in parallel. The Query and Log functions access global variables, however, so they are constrained from running concurrently. If the server were broken into fewer stages, for example by handling the database query and response preparation together, the analysis and scheduler would be forced to avoid concurrency for response preparation in separate requests.