| |
|
|
| |
 |
 |
 |
 | |
 |
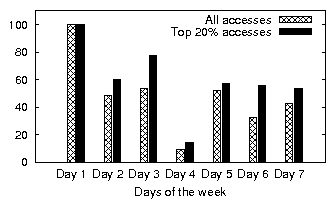 |
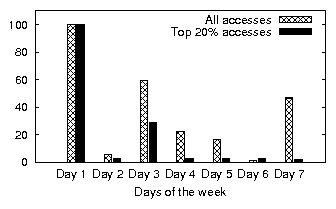 |
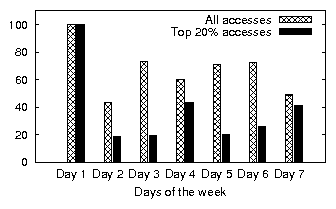 | |
| (a) office | (b) developer | (c) SVN server | (d) web server |
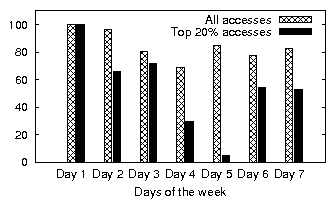
| Workload | File System | Memory | Reads [GB] | Writes [GB] | File System | Top 20% | Partial | ||
| type | size [GB] | size [GB] | Total | Unique | Total | Unique | accessed | data access | determinism |
| office | 8.29 | 1.5 | 6.49 | 1.63 | 0.32 | 0.22 | 22.22 % | 51.40 % | 65.42 % |
| developer | 45.59 | 2.0 | 3.82 | 2.57 | 10.46 | 3.96 | 14.32 % | 60.27 % | 61.56 % |
| SVN server | 2.39 | 0.5 | 0.29 | 0.17 | 0.62 | 0.18 | 14.60 % | 45.79 % | 50.73 % |
| web server | 169.54 | 0.5 | 21.07 | 7.32 | 2.24 | 0.33 | 4.51 % | 59.50 % | 15.55 % |
| |
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
| (a) office | (b) developer | (c) SVN server | (d) web server |
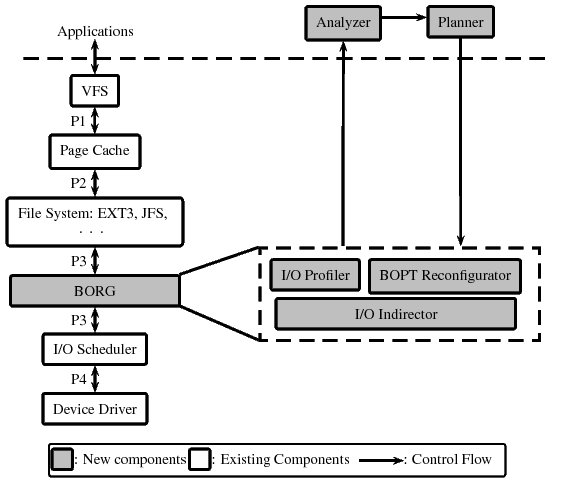
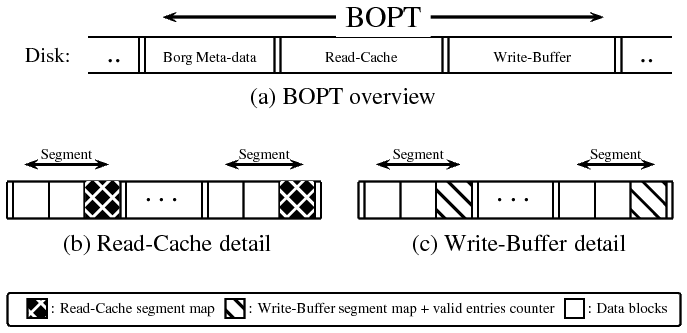
| Magic number | BORG BOPTpartition identifier. |
| BORG_REQUIRE bit | BOPT contains dirty data. |
| BOPT size | BOPT partition size. |
| Read-cache info | Offset and size of the Read-cache. |
| Write-buffer info | Offset and size of the Write-buffer. |
| Segment size | Fixed size of segments in the BOPT. |
|
S
|
|
# Seeks
|
| RAM | Capacity (GB) | |||||
| (MB) | Total | FS | BOPT | |||
| O1 | WD | 2500AAKS | 1024 | 250 | 46 | 1 |
| O2 | WD | 360GD | 1024 | 39 | 24 | 2 |
| O3 | Maxtor | 6L020L1 | 1024 | 20 | 15 | 2 |
| O4 | WD | 2500AAKS | 1024 | 250 | 180 | 8 |
| O5 | Maxtor | 6L020J1 | 1536 | 20 | 8 | 1 |
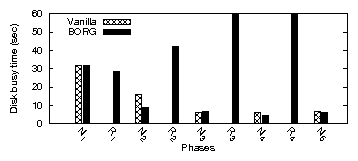
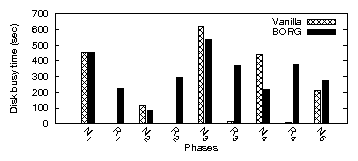
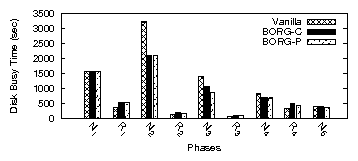
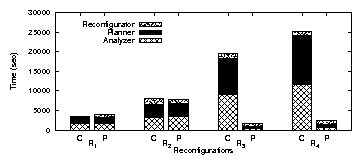
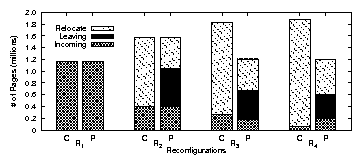
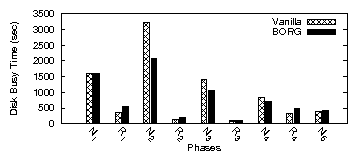
| App | Start-up time | Rand. I/O % | Avg seek (#cyl) | |||
| V | B | V | B | V | B | |
| firefox | 3.71 | 2.32 | 2.7 | 1.2 | 132 | 37 |
| oowriter | 5.30 | 2.74 | 3.8 | 0.2 | 193 | 20 |
| xemacs | 7.26 | 2.72 | 2.1 | 0.3 | 87 | 9 |
| acroread | 6.20 | 2.65 | 4.6 | 0.1 | 39 | 9 |
| eclipse | 4.12 | 1.52 | 2.5 | 0.3 | 198 | 29 |
| gimp | 3.62 | 3.66 | 2.5 | 2.1 | 102 | 63 |
| ooimpress | 5.18 | 1.97 | 2.7 | 0.3 | 61 | 39 |
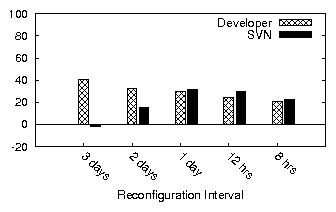
|

|
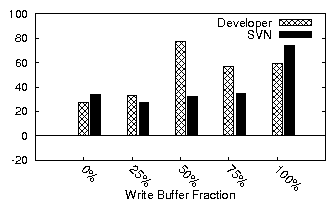
|