
5th USENIX Conference on File and Storage Technologies – Abstract
Pp. 185–198 of the Proceedings
AMP: Adaptive Multi-stream Prefetching in a Shared Cache
Binny S. Gill and Luis Angel D. Bathen, IBM Almaden Research Center
Abstract
Prefetching is a widely used technique in modern data storage systems.
We study the most widely used class of prefetching algorithms known as
sequential prefetching.
There are two problems that plague the state-of-the-art sequential prefetching algorithms:
(i) cache pollution, which occurs when prefetched data replaces more
useful prefetched or demand-paged data, and (ii) prefetch wastage,
which happens when prefetched data is evicted from the cache before it
can be used.
A sequential prefetching algorithm can have a fixed or adaptive degree of
prefetch and can be either
synchronous (when it can prefetch only on a miss), or
asynchronous (when it can also prefetch on a hit). To capture these
distinctions we define four
classes of prefetching algorithms: Fixed Synchronous (FS), Fixed Asynchronous (FA), Adaptive Synchronous (AS), and Adaptive Asynchronous (AA).
We find that the relatively unexplored class of AA
algorithms is in fact the most promising for sequential prefetching.
We provide a first formal analysis of the criteria necessary for
optimal throughput when using an AA algorithm in a cache shared by
multiple steady sequential streams.
We then provide a simple implementation called AMP, which adapts
accordingly leading to near optimal performance
for any kind of sequential workload and cache size.
Our experimental set-up consisted of an IBM xSeries 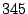 dual
processor server running Linux using five SCSI disks.
We observe that AMP convincingly outperforms all the contending members of the
FA, FS, and AS classes for any number of streams, and over all
cache sizes. As anecdotal evidence, in an experiment with dual
processor server running Linux using five SCSI disks.
We observe that AMP convincingly outperforms all the contending members of the
FA, FS, and AS classes for any number of streams, and over all
cache sizes. As anecdotal evidence, in an experiment with 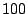 concurrent sequential streams and varying cache sizes, AMP beats the
FA, FS, and AS algorithms by
concurrent sequential streams and varying cache sizes, AMP beats the
FA, FS, and AS algorithms by 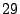 - -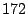 %, %, 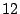 - -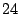 %, and %, and
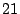 - -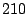 % respectively while outperforming OBL by a factor of % respectively while outperforming OBL by a factor of 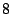 .
Even for complex workloads like SPC1-Read, AMP is consistently the
best performing algorithm.
For the SPC2 Video-on-Demand workload, AMP can sustain at least .
Even for complex workloads like SPC1-Read, AMP is consistently the
best performing algorithm.
For the SPC2 Video-on-Demand workload, AMP can sustain at least 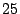 % more
streams than the next best algorithm. Finally, for a workload consisting of
short sequences, where optimality is more elusive,
AMP is able to outperform all the other
contenders in overall performance. % more
streams than the next best algorithm. Finally, for a workload consisting of
short sequences, where optimality is more elusive,
AMP is able to outperform all the other
contenders in overall performance.
- View the full text of this paper in HTML and PDF. Listen to the presentation in MP3 format.
 Until February 2008, you will need your USENIX membership identification in order to access the full papers.
The Proceedings are published as a collective work, © 2007 by the USENIX Association. All Rights Reserved. Rights to individual papers remain with the author or the author's employer. Permission is granted for the noncommercial reproduction of the complete work for educational or research purposes. USENIX acknowledges all trademarks within this paper.
Until February 2008, you will need your USENIX membership identification in order to access the full papers.
The Proceedings are published as a collective work, © 2007 by the USENIX Association. All Rights Reserved. Rights to individual papers remain with the author or the author's employer. Permission is granted for the noncommercial reproduction of the complete work for educational or research purposes. USENIX acknowledges all trademarks within this paper.
|

