
 |
It is extremely important to examine the common case where a limited
cache is used by prefetching algorithms to cater to multiple sequential streams.
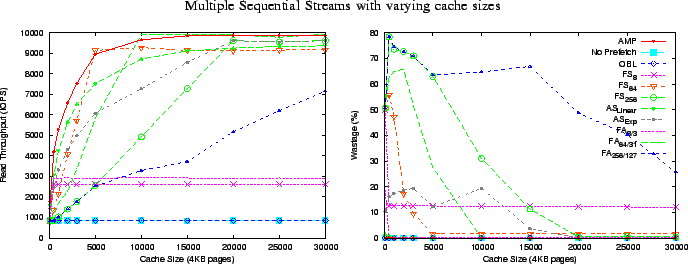
In Figure 8, we depict the aggregate throughput achieved by
a hundred parallel sequential streams with a thinktime of ![]() ms.
The key observation is that different algorithms are suitable for different cache
sizes, while AMP is universally the best, closely enveloping all the other plots.
ms.
The key observation is that different algorithms are suitable for different cache
sizes, while AMP is universally the best, closely enveloping all the other plots.
Out of the FS algorithms, FS
![]() is the best at very low cache sizes,
while FS
is the best at very low cache sizes,
while FS
![]() is much better at the higher cache sizes. In FA algorithms, FA
is much better at the higher cache sizes. In FA algorithms, FA
![]() is again the best at low cache sizes, while FA
is again the best at low cache sizes, while FA
![]() is much superior at the higher
cache sizes. As a rule of thumb, a lower prefetch degree performs better at lower
cache sizes as high values of
is much superior at the higher
cache sizes. As a rule of thumb, a lower prefetch degree performs better at lower
cache sizes as high values of ![]() create prefetch wastage in smaller caches.
This is in contrast to the single stream case, where a higher
create prefetch wastage in smaller caches.
This is in contrast to the single stream case, where a higher ![]() was always
a better choice.
This leads us to the adaptive synchronous algorithms. AS
was always
a better choice.
This leads us to the adaptive synchronous algorithms. AS
![]() increases
increases ![]() exponentially, reaching higher values of
exponentially, reaching higher values of ![]() quickly
creating significant prefetch wastage for lower cache sizes. AS
quickly
creating significant prefetch wastage for lower cache sizes. AS
![]() , being
slower in its adaptation, usually performs better than AS
, being
slower in its adaptation, usually performs better than AS
![]() at lower cache sizes
while the reverse is true at higher cache sizes.
The only algorithm that truly adapts the value of
at lower cache sizes
while the reverse is true at higher cache sizes.
The only algorithm that truly adapts the value of ![]() so as to minimize prefetch
wastage is AMP.
As a rough measure of the overall performance of each algorithm, we compute the
average throughput across all cache sizes in Figure 8. We find that
AMP outperforms the FA algorithms by
so as to minimize prefetch
wastage is AMP.
As a rough measure of the overall performance of each algorithm, we compute the
average throughput across all cache sizes in Figure 8. We find that
AMP outperforms the FA algorithms by ![]() -
-![]() %, the AS algorithms by
%, the AS algorithms by ![]() -
-![]() %,
the FS algorithms by
%,
the FS algorithms by ![]() -
-![]() % and no prefetching and OBL by a factor of
% and no prefetching and OBL by a factor of ![]() .
This is also a testimonial to the fact that AMP algorithm
closely follows the optimality criteria derived in Section III-B.
.
This is also a testimonial to the fact that AMP algorithm
closely follows the optimality criteria derived in Section III-B.
In the right panel of Figure 8 we plot wastage, which is
the percentage of evicted pages that were evicted before they could be accessed.
We observe that the prefetching
algorithms that have a high ![]() or aggressively increase
or aggressively increase ![]() suffer from
the most prefetch wastage, and that wastage is larger for
smaller cache sizes. The prefetch wastage in the case of AMP is always less
than
suffer from
the most prefetch wastage, and that wastage is larger for
smaller cache sizes. The prefetch wastage in the case of AMP is always less
than ![]() %, while on an average,
FA, FS, and AS algorithms waste up to
%, while on an average,
FA, FS, and AS algorithms waste up to ![]() %,
%, ![]() %, and
%, and ![]() % respectively.
% respectively.