![[*]](footnote.png)
| Jelena Mirkovic | Karen Sollins | John Wroclawski |
| USC Information Sciences Institute | MIT CSAIL | USC Information Sciences Institute |
| 4676 Admiralty Way ste 1001 | 32 Vassar St. | 4676 Admiralty Way ste 1001 |
| Marina Del Rey, CA 90292 | Cambridge, MA 02139 | Marina Del Rey, CA 90292 |
| sunshine@isi.edu | sollins@csail.mit.edu | jtw@isi.edu |
We introduce a new paradigm of experiment health that denotes a user-supplied description of correct experiment behavior, i.e., healthy experiments behave as their creators intended. We then propose an experiment health management infrastructure that can be added to existing testbeds to improve their usability and robustness. The infrastructure consists of an expectation language in which a user expresses her notion of experiment health, a monitoring infrastructure that is driven by user expectations, health evaluators, recovery engines and a shared library of health tools and collected experiment statistics. This infrastructure is useful not only for experiment management, but also for testbed management.
In the past decade several large and many small testbeds have been created to promote realistic testing of solutions in fields such as networking, distributed systems and applications, security, sensor networks, etc. Experiments on these testbeds are distributed by nature, which makes their monitoring, problem detection, diagnosis and recovery challenging if done in manual fashion. We refer to all these actions as experiment health management, where a healthy experiment behaves as its creator intended, at all levels of observation. This notion of health at all levels is necessary to differentiate a healthy experiment from an experiment that reaches a creator-intended goal but in a way that creator did not intend. We will illustrate this point in the following section.
Security experiments pose additional management challenges of high scale, complexity and risk. Because security events, such as DDoS or worm propagation, are high-scale, experiments that recreate them usually require tens to hundreds of machines, which increases cost and complexity of health management, and probability of health failures. Security experiments must recreate realistic threats to either study them or test proposed defenses. This is complex because security threats often require a complex set of conditions to be effective, such as presence of a particular vulnerable version of a specific application for a worm to propagate. Security defense performance also often depends on the deployment environment. If any puzzle piece is not set just right the threat or its defense may not succeed. Security experiments are often risky because they involve malware or create disruptive events. Testbeds need to effectively manage this risk, which is often done assuming user collaboration, e.g., requiring (but not checking or enforcing) that a user restricts malware probes only to machines within her experiment.
Finally, there are many cases when a user running the experiment is not its creator; e.g., a researcher repeats another's experiment, teams collaborate on a project, or a testbed is used in education. Such a user has a particularly hard time to detect and diagnose unexpected experiment behavior, and would benefit from automated health management.
In this paper we introduce a novel notion of experiment health in Section 2, which denotes the fact that experiment behavior matches some critical set of its creator's expectations. We propose an automated health management infrastructure in Section 3 and discuss its benefits both to users and to testbeds. The infrastructure consists of an expectation language through which a user expresses her expectations about experimental behavior, monitoring agents that collect statistics of experiment behavior, health evaluators that process statistics and compare them to expectations to detect failures, recovery engines that restore experiment health, and a shared library of observations and health tools. We survey related work in section 4 and conclude in Section 5.
We define experiment health as the property of the experiment behaving according to its creator's expectations, at all observation levels. To see why health at all levels is important imagine the case of a misconfigured SYN Flood experiment. SYN traffic is sent to another port than 80, which should not deny service to C's Web traffic. The user can easily spot that something is wrong by observing lack of SYN repetitions in C's traffic, although she may have trouble diagnosing the cause. Now imagine that in addition to the previous misconfiguration the machine R freezes and stops forwarding traffic. The effect the user expects to see - C repeating SYN packets - will occur, but for the wrong reason. This is why experiment health encompasses experiment behavior at all levels and not just the end outcome. C's service should be denied because of the SYN flood and not for any other reason. Even this simple example brings home the point that defining experiment health is a complex task. We will describe in Section 3 how we plan to ease it for the user.
It may seem that maintaining experiment health is very similar to network management, whose goal is to support the network mission of delivering traffic effectively between end nodes by maintaining connectivity, distributing load, ensuring correct network configuration, etc. The main difference is that the definition of experiment health depends critically on experimenter's research goals. Unlike network management that maintains common, well-understood network performance targets, experiment health management must understand what a user wants and maintain that specific behavior. In the example of SYN flood attack, the goal was to deny service - quite opposite from the network management's goal of keeping networks up and running.
We now briefly discuss why an experiment may fail to meet user's expectations. An experiment's behavior is influenced by the following internal and external elements, which we believe form an exhaustive list: (1) Experiment definition and configuration, including the software and scripts written by the user, topology settings, location and resources of the experimental hardware, and default OS and applications loaded by the testbed on the experimental hardware, (2) Testbed infrastructure, such as experimental node hardware, switching fabric, control network, and shared testbed services like DNS and network file system, (3) Resource sharing with other experiments, and (4) The public Internet, if any of the experimental traffic is expected to cross it. Any of these four elements may behave in a way unforeseen by a user, and interfere with experimental results.
An experiment may be misconfigured, either by inclusion or by omission. Misconfiguration by inclusion means that some feature is explicitly present in the experiment's setup but it is set to a wrong value, e.g., a traffic generator is engaged at a rate that is too low or a topology is disconnected. We had such misconfiguration in the above example with SYN packets going to a wrong port. Misconfiguration by omission means that a user implicitly assumes presence of some feature/value pair but the assumption does not always hold, e.g., a user assumes that an experimental application always works correctly, but its behavior is actually hardware-dependent, thus the experiment fails when assigned some hardware types.
Any of the critical pieces of testbed infrastructure may fail, including shared services. It is particularly difficult for users to detect or anticipate this kind of failure, since many testbed internals are usually hidden from them.
Resource sharing may create interference between experiments. An experiment may overload the shared resource, such as a file system, if fair sharing is not strictly enforced. An experiment may also interact with a shared application improperly causing it to misbehave and influence other users. In the DETER testbed we have observed experiments crashing the shared server that controls experimental events by sending it overly long messages. Again, users have a hard time diagnosing misbehavior that stems from resource sharing since sharing is implicit in the testbed's design, whose details are not publicized to users.
Finally, if any experimental traffic travels over the Internet, connectivity, congestion and any Internet services accessed by it may influence experimental behavior. For example, if SYN Flood experiment were to be performed on Planetlab [2] there may be connectivity between R and S but excess SYN traffic may be filtered by some ISP-level defense on this link. This may or may not lead to denial of service for C, depending on the exact filtering behavior.
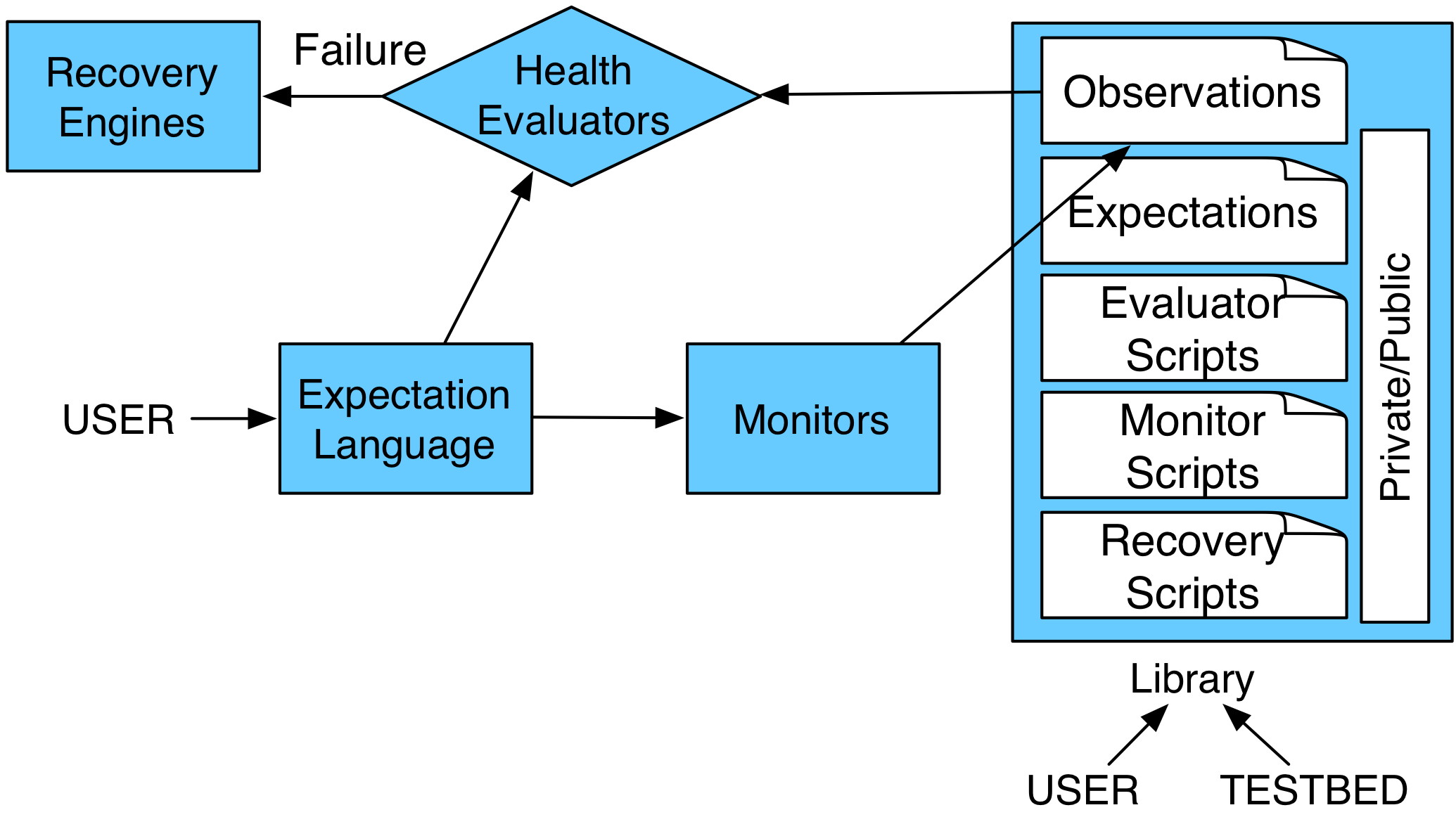
We propose a health management infrastructure that can be integrated with current testbeds to improve their usability and robustness. We plan to integrate this infrastructure with the DETER testbed [3]. Figure 2 shows key pieces of this infrastructure and how they relate to each other. Users express their expectations using the expectation language. The expectations then drive setup of monitors that collect statistics and store them in the library. Periodically health evaluators read the expectations and evaluate statistics against them. On mismatch, failed health is detected and an evaluator triggers recovery engines to restore the health or inform the user. Specifics of desired recovery actions are also obtained from expectations. In addition to observations, the library may hold expectations, together with custom monitor, evaluator and recovery scripts that a user wants to reuse . Each library component can be marked as private or public, thus users may share their data and scripts with others. Testbed operators populate the public library with commonly used scripts and expectations such as the expectation of all experimental machines being up and accepting logins, and all experimental links being passable.
With regard to deployment, we envision some monitors running on experimental nodes (such as those monitoring file system changes) and others running on the testbed infrastructure (those monitoring the testbed's health). Placement of health evaluators and the library must be such to minimize communication cost for library reads and writes, while maximizing sharing and robustness. In a geographically centralized testbed like Emulab [4] is likely that both these services would run on shared testbed nodes. In a distributed testbed like Planetlab [2] creating a local copy of relevant library modules and deploying evaluators on a dedicated experimental node may yield better performance. Recovery engines are instantiated on need bases, and their location depends on the type of recovery.
Figure 3 shows the preliminary grammar of the expectation language in yacc format. We expect to extend this design as our work progresses.
Expectation statements start by specifying some action, such as calling a user-supplied script. After the keyword EXPECT, the user specifies what the desired outcome should be by invoking health evaluators (see next section). If the expectation is not met, actions after the IFFAIL keyword are invoked. Within the IFFAIL body the user may specify additional expectations, invoke recovery actions (such as sending herself an email), or stop the execution using the keyword STOP. Commands that specify health evaluators and recovery actions refer to corresponding library scripts. An EXPECT keyword can be followed by ALWAYS denoting that health evaluation should be repeated periodically. The default period of 1 minute can be changed using the keyword CHECK followed by a number of seconds. An EXPECT AFTER followed by a number of seconds denotes evaluation that should be performed after that delay, to let the action take effect.
We now illustrate how a user may use expectations to detect and diagnose failures. While early experimentation requires user interaction with the experiment, mature experimentation is often scripted so many runs can be executed to collect statistically significant data. Expectations are meant to extend existing scripts with failure detection and diagnostics. Figure 4 shows a sample expectation script for the SYN flood attack. Text shown in black is the original user's script that starts the legitimate traffic and starts the attack. The first line invokes library functions that continuously check if all nodes and links are functioning. The second line checks for presence of SYN cookies [5], a popular defense against SYN flood that is on by default in some operating systems. Legitimate traffic is then run and an evaluator checks if it arrives successfully at the server; the same check is repeated for attack traffic in the next line. Finally, the attack's success is checked by verifying that the number of SYN packets is larger than number of data packets arriving at the server. On all failures the user is alerted via a message that helps diagnose the source of failure, and execution is halted.
Expectations may be written by an experimenter, or a testbed may attempt to aid expectation writing by providing support for user action observation, correlation and learning. We plan to first implement explicit expectations in DETER and then add the following learning approach. The testbed monitors the user's shell history and correlates this with traffic, file and process changes observed on all experimental machines, at a relatively low frequency, customizable by the user. Changes that occur in a small window after a user's action are recorded as an expected outcome. It is likely that several iterations will be needed to discern cause-effect changes vs changes that just happen to overlap a user's action but are not causally related. We also anticipate that inferred expectations will be incomplete and imperfect -- an automated process can hardly match a human's understanding of experimental behavior. We emphasize however that even human-designed expectations are likely to evolve over a life of an experiment as the user discovers new behavior invariants and failure modes. The learning approach we propose is simply meant to provide a rough starting point that must further be iteratively refined by the user.
To support health evaluation it is critical to provide monitoring and data collection about what is happening in the testbed as a whole and in each particular experiment. There are three key sources of such data: (1) static testbed data such as IP addresses, node allocation to a particular experiment, etc. (2) data collected routinely in all experiments and in the facility itself, such as packet traces, node liveness, etc., and (3) explicit data collection requested by an experimenter or the testbed management, in context of an expectation's condition evaluation. We also identify three challenges to data collection. First, because of scale and system unreliability, available data may be incomplete. Second, the desired information may not be directly measurable, but must be inferred from other measurements that can be gathered (e.g. quality of service). Finally, in light of security expectations that relate to privacy, some information may not be accessible where it is desired. Either an experiment or the testbed system may withhold information from the other. We will provide a base set of data collection tools in our library, which will be extensible by researchers. Specifically we will provide tools that collect traffic, process status data, file system data and file contents.
There is also an inherent tradeoff in data collection that influences its frequency. Too frequent collection may interfere with the experiment's behavior, but infrequent collection may delay detection of failures. It will likely be impossible to set a default frequency that satisfies all users, since each experiment's sensitivity to data collection depends on user-specified experiment's behavior, and users may be satisfied with a wide range of detection delays. Instead we hope to provide a safe, low-frequency setting as a default for novice users and a monitor API for advanced users to customize frequencies. We acknowledge that getting these settings right will be challenging for users but we do not see a better alternative.
The job of health evaluation is to determine whether the current behavior of a subject meets specified health criteria. There are two aspects to evaluating the health of a subject. The first is to select the particular behaviors of the subject, such as link bandwidth, jitter or loss rate, that are to be evaluated for the desired expectation goal. The second is to determine if the health of that subject meets the desired goal, i.e. to translate a quantitative result such as a link's loss rate into a qualitative true/false result. We plan to implement evaluators that must be explicitly invoked by users, with success criteria that must also be explicitly specified. Initial evaluators provided in the library will help users detect if a machine is live, if there is a shell on that machine, if a link is passable, if a file exists, if file contents match a regular expression supplied by the user, if a process exists and matches a specified state, and if specific traffic flows between two nodes.
Returning to Figure 4, evaluators all_nodes_up and all_links_up are complex library functions that call simple functions node_up(node) and link_up(link) for each node and link in the experiment and return true if all evaluations are true. Evaluator exists checks for presence of a file on a specific experimental node -- in our case node S. Evaluator contents is similar to exists but has a third argument -- a regular expression that should match file contents for the result to be true. Evaluator traffic checks if traffic flows from the first node in the argument list to the second, and returns packet count within some prespecified interval. The third argument is a tcpdump expression that is used to filter traffic of interest.
We now touch on the problem of composite evaluation in the case of more complex goals. For example, our goal may be to create the SYN flood attack from 20 machines to a server, then engage some defense on several routers in the topology that are on the traffic's path, and measure if it is working. Expressing this goal via low-level expectations would result in a long, unwieldy script. We will likely need to extend the expectation language vocabulary in the future for iteration, expectation parameterization and composition of high-level expectations by invoking low-level ones by name, similar to function calls.
Similarly to monitoring tools, we will initially develop several common recovery tools and store them into the public library: emailing the user or the operator, displaying a pop-up window to the user, rebooting a machine, swapping out the experiment, reswapping the experiment, quarantining the experiment, reconfiguring the experimental firewall or the main DETER firewall, and stopping, starting or restarting a process.
We expect that a lot of tools developed for experiment health management will be reusable. Tool sharing occurs via the library that we will initially populate with public, monitoring and recovery scripts, and health evaluators. The library will be extensible, so that users can reuse their custom scripts and can build upon each other's work. Users will be able to mark library components they contribute as either public or private.
The collected information may be valuable to more than one monitoring tool in different contexts. For example, it may be important to collect packet traces in an experiment for the following uses: (1) user's evaluators may depend on these traces to verify correct experiment behavior, (2) the testbed may use such traffic information to determine the health of the complete set of resources it is managing, (3) testbed operators may use it to develop long-term traffic and usage models for planning provisioning, (4) traffic traces may provide an audit trail if an experiment creates a security risk for the testbed. The information should be collected once and managed effectively to allow for multiple uses. This requires a common information substrate or information plane, with well defined access rules and contexts, that we plan to develop on DETER. Information collection and access must be designed to reflect the security and privacy expectations both of users and of the testbed.
We now summarize the expected benefits from experiment health management. While many users and all testbed operators already deploy custom scripts to monitor the experimental and testbed behavior, there are several drawbacks to this practice. First, scripts are usually written based on prior experience with common failure modes and an implicit definition of desired behavior. They are often engaged on need basis. The health management framework encourages explicit specification of desired behavior and engagement dynamics thus helping users and operators become aware of, formalize and refine their assumptions. Second, scripts are often tied to a single experiment or testbed, and hard to share or reuse while we hope to develop parameterized monitors, health evaluators and recovery engines that facilitate sharing and can be reused without modifications.
Our experiment health management is an extension and customization of knowledge plane [6] ideas to network testbeds. Much recent work in this area has concentrated on the sub-problem of supporting an information plane [7,8,9,10] but it does not provide the ability to control or limit access to information based on security and privacy policies, which we plan to develop.
There is vast work in network management, which differs from our health management because testbed experiments lack generally agreed-upon correctness or performance goals. Another difference lies in the granularity at which management is done: networks are managed at the high granularity of network elements and links, while experiments also need to be managed at the low granularity of user actions.
There are a number of tools for distributed application management on PlanetLab [2], of which the most advanced is Plush [11]. Plush is a toolkit for distributed application configuration, management and visualization. Plush enables users to specify tasks in XML format, then executes them invoking low-level process, file and resource monitoring to detect failures. Plush also provides synchronization primitives and performs resource acquisition and reallocation as needed. The primary distinction between Plush and our proposed health monitoring is that Plush manages for known performance goals (connectivity, process liveness, etc.) suitable for continuously running applications, while we additionally manage for customizable performance goals that are suitable for widely varying testbed experiments. Our management thus includes the notion of ``expected performance'' and covers a wider range of behaviors than Plush.
Emulab's Experimenters Workbench [12] contains support for experiment versioning, cloning via a template, and archiving. These capabilities support pre-packaged experiments, and are needed for sharing but they do not provide any support for experiment creation and correctness checking, which is our main focus.
In the area of expectation or policy specification languages, we mention two extremes. XACML [13] is a declarative language and expects something else to enforce policies. From our perspective, policy declarations are only a small part of our challenge. In contrast, Ponder [14,15] is an object-based language for declaring not only security and management policies, but time, state, and composite conditions under which they should be evaluated, sets of subjects to be evaluated, sets of targets over which some action might be taken, and the actions themselves. Simpler than Ponder, Tcl Expect [16] is a scripting environment whose syntax enables specification of control flows that depend on controlled program outputs, thus automating system testing. Our expectation language will incorporate capabilities present in Ponder and Tcl Expect, but our challenge is to make the language easily accessible, usable, and understandable by a broad set of differently skilled experimenters. We thus plan to reuse features of existing languages, wrapping them in more user-friendly syntax and higher level language constructs.
We see two distinct advantages to the use of such a system. First, the very act of making expectations explicit improves research methodology and leads to improved understanding. The act of documenting experiment invariants within our system may help the researcher to carefully consider the scope and validity of their experiment. Once complete, this documentation will communicate the experimenter's assumptions and expectations to other researchers and students, promoting repeatable research.
The system's second advantage is its ability to improve the validity of experimental results, by detecting failures of experiment configuration, setup, or underlying infrastructure that might otherwise go undetected. This capability increases quickly in importance as experiments grow in scale and complexity.
The system described in this paper represents a first step towards a comprehensive and usable experiment health monitoring system. To fully realize the potential of such a system, further advances will be required both in functionality of the system and ease of use. High level, intuitive tools that assist the experimenter in capturing expectations and developing appropriate responses to failures will be particularly important. Nonetheless, even this first step may be of significant value - to researchers and teachers willing to take the time to draft expecation scripts; to students who find the resulting expectation documentation helpful in understanding the intent of an experiment, and to those seeking to make further progress in experimental cybersecurity research methodology itself.