



Next: Traces
Up: Methodology
Previous: Methodology
We evaluate seven existing on-line replacement algorithms that were
original designed for client/single level buffer caches.
The Least Recently Used (LRU) algorithm has been widely employed
for buffer cache management [9,6]. It replaces
the block in the cache which has not been used for the longest period
of time. It is based on the observation that blocks which have been
referenced in the recent past will likely be referenced again in
the near future. However, for second level buffer caches, this
observation is no longer present, or exists to much lesser
extent. That is the reason why LRU does not perform well for file
server caches in Willick, Eager and Bunt's study [43]. It
is interesting to see whether this is also true for other workloads
such as database back-end storage servers. The time complexity of this
algorithm is 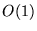 .
The Most Recently Used (MRU) algorithm is also called
Fetch-and-Discard replacement algorithm [9,6]. This algorithm is used to deal with the case such as
sequential scanning access pattern, where most of recently accessed
pages are not reused in the near future. Blocks that are
recently accessed in a second level buffer cache will likely stay in a
first level buffer cache for a period of time, so they won't be reused
in the second level buffer cache in the near future. Does this mean MRU
is likely to perform well for second level buffer caches? Willick, Eager
and Bunt did not evaluate this algorithm in their study
[43]. The time complexity of this algorithm is .
The Least Frequently Used (LFU) algorithm is another classic
replacement algorithm. It replaces the block that is least frequently
used. The motivation for this algorithm is that some blocks are
accessed more frequently than others so that the reference counts can
be used as an estimate of the probability of a block being referenced. The
``aged'' LFU usually performs better than the original LFU because the
former gives different weight to the recent references and very old
references. In [43], ``Aged'' LFU always performs
better than LRU for the file server workload, except when the client
cache is small compared to the second level buffer cache. Our results
show this is true for two traces, but for the other four, LFU performs
worse than LRU because they have some temporal locality. The time
complexity of this algorithm is
.
The Most Recently Used (MRU) algorithm is also called
Fetch-and-Discard replacement algorithm [9,6]. This algorithm is used to deal with the case such as
sequential scanning access pattern, where most of recently accessed
pages are not reused in the near future. Blocks that are
recently accessed in a second level buffer cache will likely stay in a
first level buffer cache for a period of time, so they won't be reused
in the second level buffer cache in the near future. Does this mean MRU
is likely to perform well for second level buffer caches? Willick, Eager
and Bunt did not evaluate this algorithm in their study
[43]. The time complexity of this algorithm is .
The Least Frequently Used (LFU) algorithm is another classic
replacement algorithm. It replaces the block that is least frequently
used. The motivation for this algorithm is that some blocks are
accessed more frequently than others so that the reference counts can
be used as an estimate of the probability of a block being referenced. The
``aged'' LFU usually performs better than the original LFU because the
former gives different weight to the recent references and very old
references. In [43], ``Aged'' LFU always performs
better than LRU for the file server workload, except when the client
cache is small compared to the second level buffer cache. Our results
show this is true for two traces, but for the other four, LFU performs
worse than LRU because they have some temporal locality. The time
complexity of this algorithm is 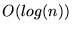 .
The Frequency Based Replacement(FBR) algorithm was originally
proposed by Robinson and Devarakonda [31] within a context of a
stand-alone system. It is a hybrid replacement policy combining both
LRU and LFU algorithms in order to capture the benefits of both
algorithms. It maintains the LRU ordering of all blocks in the cache,
but the replacement decision is primarily based upon the frequency
count. The time complexity of this algorithm ranges
from to
.
The Frequency Based Replacement(FBR) algorithm was originally
proposed by Robinson and Devarakonda [31] within a context of a
stand-alone system. It is a hybrid replacement policy combining both
LRU and LFU algorithms in order to capture the benefits of both
algorithms. It maintains the LRU ordering of all blocks in the cache,
but the replacement decision is primarily based upon the frequency
count. The time complexity of this algorithm ranges
from to 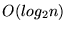 depending on the section sizes. The
algorithm also requires parameter tuning to adjust the section
sizes. So far, no on-line adaptive scheme has been proposed. In Willick, Eager
and Bunt's file server cache study (1992) [43], FBR is
the best algorithm among all tested ones including LRU, LFU, MIN, and
RAND.
The Least kth-to-last Reference (LRU-k) algorithm was first
proposed by O' Neil, et.al for database systems [15] in
1993. It bases its replacement decision on the time of the
depending on the section sizes. The
algorithm also requires parameter tuning to adjust the section
sizes. So far, no on-line adaptive scheme has been proposed. In Willick, Eager
and Bunt's file server cache study (1992) [43], FBR is
the best algorithm among all tested ones including LRU, LFU, MIN, and
RAND.
The Least kth-to-last Reference (LRU-k) algorithm was first
proposed by O' Neil, et.al for database systems [15] in
1993. It bases its replacement decision on the time of the
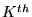 -to-last reference of the block, i.e., the reference density
observed during the past
-to-last reference of the block, i.e., the reference density
observed during the past 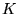 references. When is
large, it can discriminate well between frequently and infrequently
referenced blocks. When is small, it can remove cold blocks
quickly since such blocks would have a wider span between the current
time and the th-to-last reference time. The time complexity of
this algorithm is .
The Least Frequently Recently Used (LFRU) algorithm was proposed
by Lee, et.al in 1999 to cover a spectrum of replacement algorithms
that include LRU at one end and LFU at the other [14]. It
endeavors to replace blocks that are the least frequently used and not
recently used. It associates a value, called Combined Recency and
Frequency (CRF), with each block. The algorithm replaces the block
with the minimum CRF value. Each reference to a block contributes to
its CRF value. A reference's contribution is determined by a weighting
function
references. When is
large, it can discriminate well between frequently and infrequently
referenced blocks. When is small, it can remove cold blocks
quickly since such blocks would have a wider span between the current
time and the th-to-last reference time. The time complexity of
this algorithm is .
The Least Frequently Recently Used (LFRU) algorithm was proposed
by Lee, et.al in 1999 to cover a spectrum of replacement algorithms
that include LRU at one end and LFU at the other [14]. It
endeavors to replace blocks that are the least frequently used and not
recently used. It associates a value, called Combined Recency and
Frequency (CRF), with each block. The algorithm replaces the block
with the minimum CRF value. Each reference to a block contributes to
its CRF value. A reference's contribution is determined by a weighting
function 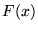 where
where 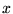 is the time span from the reference to the
current time. By changing the parameters of the weighting function,
LFRU can implement either LRU or LFU. The time complexity of this
algorithm is between and . It also requires
parameter tuning and no dynamic scheme has been proposed.
The Two Queue (2Q) algorithm was first proposed for database
systems by Johnson and Shasha in 1994 [23]. The motivation is
to removed cold blocks quickly. It achieves this by using one FIFO
queue
is the time span from the reference to the
current time. By changing the parameters of the weighting function,
LFRU can implement either LRU or LFU. The time complexity of this
algorithm is between and . It also requires
parameter tuning and no dynamic scheme has been proposed.
The Two Queue (2Q) algorithm was first proposed for database
systems by Johnson and Shasha in 1994 [23]. The motivation is
to removed cold blocks quickly. It achieves this by using one FIFO
queue 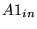 and two LRU lists,
and two LRU lists, 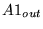 and
and 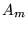 . When first
accessed, a block is placed in ; when a block is evicted from
, its identifier is inserted into . An access to a
block in promotes this block to . The time complexity
of the 2Q algorithm is . The authors have proposed a scheme to
select the input parameters: and sizes. Lee and
et. al. showed that 2Q does not perform as well as others for single
level buffer caches [14]. However, our results show that 2Q
in most cases performs better than tested alternatives except the new
algorithm for second level buffer caches.
. When first
accessed, a block is placed in ; when a block is evicted from
, its identifier is inserted into . An access to a
block in promotes this block to . The time complexity
of the 2Q algorithm is . The authors have proposed a scheme to
select the input parameters: and sizes. Lee and
et. al. showed that 2Q does not perform as well as others for single
level buffer caches [14]. However, our results show that 2Q
in most cases performs better than tested alternatives except the new
algorithm for second level buffer caches.
Next: Traces
Up: Methodology
Previous: Methodology
Yuanyuan Zhou
2001-04-29