



Next: Results
Up: Simulation and Results
Previous: Simulation and Results
We have implemented the nine replacement algorithms in our buffer
cache simulator. The block size for all simulations is 8 KBytes.
With experiements, we found out that using 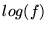 function as our
function as our
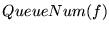 function works very well for all traces. Our experiments
also show that eight LRU queues are enough to seperate the warmer blocks
from the others. The history buffer
function works very well for all traces. Our experiments
also show that eight LRU queues are enough to seperate the warmer blocks
from the others. The history buffer
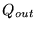 size is set to be four times of the number of blocks in the
cache. Each entry of
the history buffer occupies fewer than 32 bytes so that the memory
requirement for the history buffer is quite small, less than 0.5% of
the buffer cache size. The lifeTime parameter is adjusted
adaptively at running time. The main idea for dynamic lifeTime adjusting is to
efficiently collect statistic information on the temporal distance
distributions from access history. Due to page limits, we will not discuss
it in this paper, but details can be found in [44].
The history buffer size for 2Q is one half of the number of blocks in
the cache as suggested by Johnson and Shasha in [23]. For fairness,
we have extended the LFRU, LRU-2, FBR and LFU algorithms to use a
history buffer to keep track of
size is set to be four times of the number of blocks in the
cache. Each entry of
the history buffer occupies fewer than 32 bytes so that the memory
requirement for the history buffer is quite small, less than 0.5% of
the buffer cache size. The lifeTime parameter is adjusted
adaptively at running time. The main idea for dynamic lifeTime adjusting is to
efficiently collect statistic information on the temporal distance
distributions from access history. Due to page limits, we will not discuss
it in this paper, but details can be found in [44].
The history buffer size for 2Q is one half of the number of blocks in
the cache as suggested by Johnson and Shasha in [23]. For fairness,
we have extended the LFRU, LRU-2, FBR and LFU algorithms to use a
history buffer to keep track of 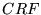 values, second-to-last reference
time and access frequencies for recently evicted blocks respectively
(see section 2), using a history buffer of size
equal to that in MQ. We have tuned the FBR and LFRU algorithms with
several different parameters as suggested by the authors and report
the best performance. The off-line optimal algorithm (OPT) was first
proposed by Belady [2,17] and is widely used to
derive the lower bound of cache miss ratio for a given reference string.
This algorithm replaces the block with the longest future reference
distance. Since it relies on the precise knowledge of future references,
it cannot be used on-line.
ws Belady's OPT algorithm and WORST
algorithm [2,17]
As with all cache studies, interesting effects can only be observed if
the size of the working set exceeds the cache capacity. The three
traces provided by other sources (HP Disk Trace, Auspex Server Trace
and Web Server Trace) have relatively small working sets. To
anticipate the current trends that working set sizes increase with
user demands and new technologies, we chose to use smaller buffer
cache sizes for these three traces. In most of experiments, we set the
second level buffer cache size to be larger than the first level
buffer cache size. However, this property does not always hold in real
systems, For example, most of storage systems such as the IBM Enterprise
Storage Server have less than 1 Giga Bytes of storage cache (second
level buffer cache), while the frontier server, database or file
servers, typically have more than 2 Gigabytes of buffer cache (first
level buffer cache). Because of this reason, we have also explored a few
cases where the second level buffer cache is equal to or smaller than
the first level buffer cache.
values, second-to-last reference
time and access frequencies for recently evicted blocks respectively
(see section 2), using a history buffer of size
equal to that in MQ. We have tuned the FBR and LFRU algorithms with
several different parameters as suggested by the authors and report
the best performance. The off-line optimal algorithm (OPT) was first
proposed by Belady [2,17] and is widely used to
derive the lower bound of cache miss ratio for a given reference string.
This algorithm replaces the block with the longest future reference
distance. Since it relies on the precise knowledge of future references,
it cannot be used on-line.
ws Belady's OPT algorithm and WORST
algorithm [2,17]
As with all cache studies, interesting effects can only be observed if
the size of the working set exceeds the cache capacity. The three
traces provided by other sources (HP Disk Trace, Auspex Server Trace
and Web Server Trace) have relatively small working sets. To
anticipate the current trends that working set sizes increase with
user demands and new technologies, we chose to use smaller buffer
cache sizes for these three traces. In most of experiments, we set the
second level buffer cache size to be larger than the first level
buffer cache size. However, this property does not always hold in real
systems, For example, most of storage systems such as the IBM Enterprise
Storage Server have less than 1 Giga Bytes of storage cache (second
level buffer cache), while the frontier server, database or file
servers, typically have more than 2 Gigabytes of buffer cache (first
level buffer cache). Because of this reason, we have also explored a few
cases where the second level buffer cache is equal to or smaller than
the first level buffer cache.
Next: Results
Up: Simulation and Results
Previous: Simulation and Results
Yuanyuan Zhou
2001-04-29