Christine F. Reilly
University of Wisconsin-Madison
Jeffrey F. Naughton
University of Wisconsin-Madison
We are motivated by our observations of the Condor system [3]. Condor is a production system that executes user jobs on clusters of machines, and is used on over 100,000 CPUs worldwide. It is used by groups of all sizes in universities, government labs, and private companies. A wide variety of applications are run in Condor, representing a diverse set of fields that includes computer engineering, biology, chemistry, physics, finance, and insurance.
We observed that Condor is privy to a lot of information about the jobs it runs. This led us to wonder if we could use Condor as the base for a system that transparently gathers provenance [11]. A transparent provenance system gathers information without requiring that applications be altered. Because we start with an existing job execution system, we also aim to transparently add provenance gathering capabilities to Condor by only changing the system in ways that are not visible on the surface.
A benefit of using Condor as the base of our provenance system is its ability to run a wide range of applications. Any application that runs on the same operating system as at least one machine in the cluster and is able to run as a background batch job can run in Condor.
A number of interesting questions arise from our proposed provenance system design. The most obvious question is if it is actually possible to gather provenance information without making changes that are visible to the application designer, Condor user, or Condor system administrator. Once we found that it is possible to design a transparent system, our next question was whether the provenance gathered by such a system is useful. We also wondered about the overhead imposed by this provenance system on applications and Condor in terms of running time and data storage. In order to explore these questions we built a prototype provenance system on top of Condor. We call the combination of Condor and our provenance system Provenance Aware Condor (PAC).
By adding provenance capabilities to the Condor system, our goal is to provide a baseline amount of provenance for any application that runs in Condor. We recognize that, by gathering provenance for a wide range of applications, we are not able to gather all of the information provided by special-purpose provenance systems. For this reason, we expect special-purpose provenance systems to continue to be used and developed for applications that are widely used, and for those that will be in use for a long duration of time. However, there are many applications that are unlikely to ever be modified solely for the purpose of gathering provenance. These applications are the target of our provenance system. Our question is not whether our system is as powerful as a special-purpose system, rather it is whether it can be useful at all while requiring virtually no modifications to user programs or the execution system.
PAC is transparent because it is able to gather provenance from any program that runs in Condor. Although PAC does require a program to run in Condor, we consider PAC to be transparent for two reasons. First, Condor is able to run any program that can run in the background. Second, any program that currently runs in Condor can utilize PAC without making any changes to the program or to how it is submitted to Condor. PAC provides provenance to programs that currently run in Condor for ``free''. The Earth System Science Server (ES3) [6,7] uses a similar approach for transparently collecting provenance. ES3 gathers provenance by monitoring programs as they run. Users do not need to alter their programs in order to use ES3.
Another strategy for obtaining detailed provenance is to require certain behaviors from applications. For example, Trio [1] requires the data used by the application to be stored in its database, and only records provenance for computations expressed as queries over this data. This design allows Trio to gather provenance at the granularity of a database tuple, but it excludes applications that do not conform to its data storage and computation model.
Another system that gathers information by monitoring system activity is the Provenance-Aware Storage System (PASS) [10]. PASS is implemented as a layer on top of a conventional file system and stores provenance in an in-kernel port of Berkeley DB. Because PASS is a storage system, it maintains provenance for every file and detects all file activities. By integrating a provenance system with the storage system, PASS has knowledge of everything that happens to a file. In contrast, PAC is only able to record information about files when they are used by an application that is running in PAC. If a file is renamed or altered by a process that is not part of PAC, then PAC will have no knowledge of the alteration. A drawback of PASS is that it requires the use of its storage system. In contrast, PAC runs as on application on existing desktop computer systems.
The Pegasus system [9] refines an abstract workflow into an executable workflow. It uses Condor as the execution environment. Pegasus collects two sets of provenance: information about the workflow refinement, and information about the execution. Pegasus uses a wrapper around each job in the workflow to gather provenance from the job execution process. Because Pegasus performs its provenance collection outside of Condor, it cannot detect the use of system files, libraries, and other files that are not explicitly declared by the job.
One of our major design principles is that the additions we make to Condor are not disruptive to how Condor runs or to how a user interacts with Condor. We use the word ``transparency'' to describe this design principal. Because Condor is a production system, transparent changes allow users who are interested in provenance to utilize the new features while allowing other users to remain unaware of the changes.
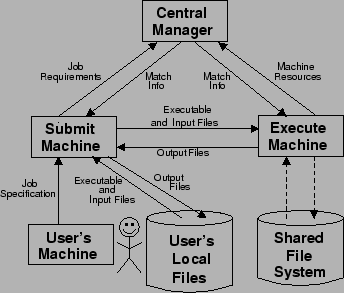
The submit machine accepts jobs from users and sends information about these jobs to the central manager. When a job is matched with an execute machine, the submit machine transfers the executable and any input files to the execute machine. After the job finishes, the submit machine downloads output files from the execute machine. A submit machine can manage many jobs from many users at the same time.
The role of an execute machine is, simply, to run jobs. When matched with a job, the execute machine first receives the executable and any input files from the submit machine. Next, it runs the job. When the job finishes, the execute machine sends the output files to the submit machine.
A major difference between using the file transfer mechanism or a shared file system is how the job accesses files. The file transfer mechanism requires the user to specify all input files when the job requirements are sent to the submit machine. Condor transfers these files to the execute machine and they are the only input files available to the job. With a shared file system, the job can access any files, provided it has the proper permissions. It is possible for a job to access files using both file mechanisms.
Condor uses a flexible set of attribute-value pairs to store information about current and past jobs in the log files. This set of attribute-value pairs is flexible in that there are no attributes that are guaranteed to be used for every job, and the set of attributes is not necessarily constant between jobs. Additionally, the user is allowed to create arbitrary attributes for each job. Despite this flexibility, there is a set of common attributes that are used by most jobs.
Command-line tools allow the user and administrator to access information about the Condor system. The basic information available is the names of machines in the pool and their usage over time, and the names of users who have ran jobs in a given time period. The basic information can be used to derive more detailed information about system utilization. The Condor Team at the University of Wisconsin has developed visual representations of system utilization and displays the information on a series of web pages.
The job history log does not necessarily contain complete information about the files used by a job. The file information that is recorded depends on the information provided by the user during job submission and on how the executable accesses files. If the user provides relative pathnames, based on the directory where the job is submitted from, the initial working directory and output directory attributes could be used to obtain the absolute pathname. If the job has access to a shared filesystem it can access input and output files that are not specified by the user. Condor only allows one file to be specified as the output file; additional output files are not recorded in the job history log.
We designed Quill to transparently interface with Condor, so that a user or an administrator who is not interested in Quill can remain unaware of its presence. The changes we made to Condor were superficial and we left the operational portions of Condor untouched. In order to achieve this goal of transparency, Quill follows Condor's data collection method of having the various daemons write information to log files. Periodically, Quill reads the logs and inserts the data into a relational database that is shared by all machines in the pool.
Queries to the Quill database can provide the same information as Condor's command-line tools. Two benefits of storing information about a Condor system in Quill's relational database are that SQL queries are often faster than running the command-line tool, and that custom queries are easy to write in SQL.
Quill provides more information about files than is available from Condor. For the files that use Condor's file transfer mechanism, Quill records the absolute path, checksum, size, and last modified time, thus providing version information.
FileTrace is a modified version of the strace program [13]. FileTrace required relatively minor modifications to strace. The biggest change was adding the capability to obtain the file checksum. The remainder of the changes involved filtering and formatting the output so it is more human-readable and easier to insert into the database. We only altered how strace handles open and close operations, so the strace output for all of the other system calls remains unchanged. This approach of making minor modifications to only the necessary components fits with our goal of developing a transparent provenance collection system.
We added FileTrace to Condor using methods that are transparent to the user and have little or no affect on the operation of Condor. In order for FileTrace to gather information from an executable, the executable and its arguments are provided to FileTrace as arguments. Condor allows the pool administrator to create a wrapper for executables that are run by Condor. We use this wrapper to run all Condor jobs with FileTrace. The data collected by FileTrace is handled in the same way as data collected by Quill: the output from FileTrace is written to a file and is imported into the database by a process that is separate from the standard Condor operations. FileTrace is a prototype that we developed for the purposes of our research and is not currently shipped with Condor.
Table 1 provides a summary of the PAC schema. The full Quill schema is available in the Condor Manual [3]. The Jobs table contains information about the machine that ran the job, names of files used by the job, and whether the job finished successfully. PAC stores information about jobs that are currently in the Condor system, as well as jobs that have exited the system. Information recorded about machines includes the hardware, operating system, and state of a machine. One result of transparently building PAC on top of Condor is that PAC has four tables that store information about files. We are only discussing the File Transfers and FileTrace tables. We are omitting the other two tables because they contain redundant information, and they only provide information about files that are listed in the job submission file. The FileTrace table contains the information gathered by the FileTrace program, including when the file was used by Condor and information that can be used to determine the version of the file. The File Transfers table contains information about files that used Condor's File Transfer mechanism to move between the submit and execute machines. PAC contains separate tables for Matches and Rejects, but the schemas of these tables are nearly identical. At the end of a matchmaking cycle, information about matches between jobs and machines is recorded in the Matches table, and information about jobs that failed to match with a machine is recorded in the Rejects table. When a job runs in Condor, information about the run is recorded in the Runs table.
| PAC Schema | |
| Table | Attributes |
|---|---|
| Jobs | job id; submission date; user id; id of the execute machine; Condor version; machine platform; initial working directory; execution environment; Condor log file name; names of files where stdin, stdout, and stderr are redirected; name and size of the executable; exit status; completion time |
| Machines | machine id; operating system; architecture; memory; state; time when it entered current state; other information that allows Condor to know if a machine is available and for Condor to derive matchmaking information. |
| FileTrace | job id; file access time; activity type; pathname; open_flags; filesystem permissions; return value of filesystem call; file_pointer; last_modified time; size; checksum |
| File Transfers | job id; direction of transfer; bytes transferred; timestamp; elapsed time; checksum; last modified time |
| Matches and Rejects | timestamp; id of the user who submitted the job; job id; machine the job matched with (only for matches) |
| Runs | run id; job id; id of machine that ran the job; start and end time of the run; image size of the executable |
The information gathered by PAC can be used to answer a wide variety of questions. We show two example queries in Tables 2 and 3. These tables show a truncated version of the query results. The queries return a large number of rows due to two factors: PAC records all system files that are used by a program; and the program we used has many input and output files. We selected rows that provide a good illustration of the capabilities of PAC.
The first query (Table 2) finds the files that were used by a specific job. Our result shows the executable, input, and output files that were used by the job. A user can determine if this job used the current input and executable files by comparing the version information from her files with the information returned by the query. This query can also return information about the system files and libraries that the job used.
In the second query (Table 3) we are looking for files that were created by a bad machine. A user can compare the list of files returned by this query with her files in order to determine if she has any files that might be bad.
| SELECT pathname, activity_type,
open_flags, last_modified, size, checksum
FROM filetrace WHERE globaljobid=`my_job_id'; |
|||||
| program.exe | exe | 2008-10-06 17:52:16-05 | 687 | 8FC8316B8930835C9085E 953F2D36745C2877346 | |
| /path/to/input.xml | open | O_RDONLY | 2008-10-06 17:52:28-05 | 9554599 | 57B7A53ACF390B1928A6 C4B6E935DD9F2CBE9F46 |
| /path/to/output.xml | open | O_WRONLY | O_CREAT | 2008-10-06 17:55:18-05 | 0 | DA39A3EE5E6B4B0D3255 BFEF95601890AFD80709 |
| /path/to/input.xml | close | 2008-10-06 17:52:28-05 | 9554599 | 57B7A53ACF390B1928A6 C4B6E935DD9F2CBE9F46 | |
| /path/to/output.xml | close | 2008-10-06 17:55:19-05 | 19895258 | 9D32885FDCD9171E44F9 302BB0141DFC1FC6B772 | |
| SELECT f.globaljobid,
f.pathname, f.last_modified, f.checksum, f.size
FROM filetrace f, (SELECT f1.globaljobid, f1.pathname, f1.activity_time, f1.file_pointer FROM filetrace f1, jobs_horizontal_history j WHERE j.lastremotehost=`foo.cs.wisc.edu' AND j.globaljobid=f1.globaljobid AND f1.open_flags LIKE `%O_WRONLY%') fopen WHERE f.activity_type=`close' AND f.globaljobid=fopen.globaljobid AND f.pathname=fopen.pathname AND f.file_pointer=fopen.file_pointer AND f.activity_time>=fopen.activity_time; |
||||
| job_id | /path/to/output.xml | 2008-08-25 14:43:40-05 | A0CA0D7D2D35C0AE6A4BD657A 115387B33167031 | 185191 |
| job_id | /path/to/log.txt | 2008-08-25 14:43:40-05 | 7A41E9EDF98605F67307C6404 D314C012F4B828E | 148 |
For these experiments we used two identical clusters of machines. Each machine runs Red Hat Enterprise Linux 5, and has a Pentium 2.40 GHz Intel Core 2 Duo processor, 4GB RAM, and two 250GB SATA-I hard disks. One cluster runs Condor without Quill or FileTrace. The other cluster runs PAC: Condor with Quill and FileTrace. Each cluster consists of a central manager machine, a submit machine, and 10 execute machines. The PAC cluster also has a machine for the PostgreSQL database. Because Condor counts each processor as a machine, each of our clusters has 20 execute machines from the perspective of Condor.
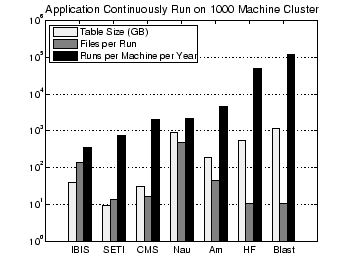
Our first estimation of the FileTrace table growth rate uses resource usage data for seven scientific applications [2]. The seven applications are: BLAST (genetics); IBIS (earth system simulation); CMS (high-energy physics); Nautilus (molecular dynamic simulation); Messkit Hartree-Fock (HF) (interactions between atomic nuclei and and electrons); AMANDA (astrophysics); and SETI@home (searches space noise for indications of extraterrestrial intelligence). Each of these applications has a different combination of number of files used and run time.
We estimate the growth rate of the FileTrace table by computing the resulting table size for each application when it is continuously run for one year on 1000 machines. Figure 2 shows the result of these computations. The FileTrace table is a reasonable size for all of these applications. The largest table is 1.15 terabytes, and would easily fit on a couple of currently available disks. As expected, the size of the FileTrace table is affected by both the number of files used by each run of the application and by the time it takes for the application to run. A large value for either variable leads to a big FileTrace table. The biggest FileTrace table, at 1.15 terabytes, is created by Blast. Blast uses the smallest number of files per job, but the large number of runs per year results in a large table size. The second largest table, approximately 900 gigabytes, is generated by Nautilus. Nautilus uses the most files per run and has a medium run time.
This estimate of the size of the FileTrace table is useful for obtaining a rough idea of how fast the table will grow. But FileTrace also records information about the system files and libraries. The table size estimate could also be inaccurate if the application opens and closes the same file multiple times. Including information about these additional file open and close calls will provide a more accurate estimate of the table size.
We used our synthetic program to compare our estimate of the size of the FileTrace table with the table that is produced by PAC. We ran four sets of the program, with the parameters for each set loosely based on the scientific applications that are described above. The parameters are the run time of the program and the number of files produced by the program. The four sets of the program represent the edges of the combined parameters: long run time, many files; long run time, few files; short run time, many files; and short run time, few files. We ran an additional set of jobs that contained an equal number of each of these four configurations. For each set, we ran as many Condor jobs as would take approximately 12 hours to complete.
We found that the actual size of the FileTrace table was half of the estimated size. The estimated and actual FileTrace table sizes are listed in Table 4. The FileTrace schema contains a number of variable size attributes. In our estimate, we were conservative and assigned values on the large side of the expected range for the variable size attributes. As stated above, our estimate does not account for the system and library files recorded by FileTrace, but these ``invisible'' files do not have enough weight to overcome our conservative estimate of the size per record. Although different applications will have different number of ``invisible'' files, this experiment confirms that the FileTrace table grows at the rate predicted by the size we estimated.
In order to confirm that PAC has little impact on the performance of Condor, we ran four sets of synthetic applications in a non-PAC Condor cluster and in a PAC cluster. These are the same applications as used for the FileTrace table size experiments in Section 4.1. For each set, we used the Condor history data to obtain the execution time of each job as well as the total time from submitting all of the jobs to their completion. These results are presented in Table 5. As expected, the job run time in PAC is almost identical to the run time in Condor without Quill or FileTrace. The variation in job run time, both between PAC and Condor and within each system, is well within the variation expected due to the Condor matching process. Condor typically begins a matchmaking cycle every 5 minutes. Depending on when jobs are submitted and when machines become available, machines could remain idle for a few minutes until the next matchmaking cycle begins. From this experiment, we conclude that adding provenance awareness to Condor does not impact the operation of Condor.
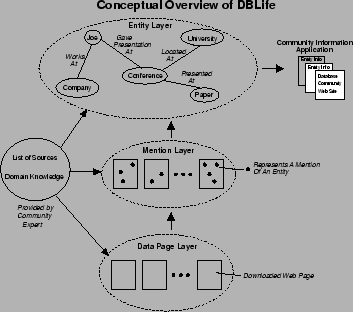
As illustrated in Figure 3, DBLife creates and maintains an entity-relationship graph that describes the database community. It starts with domain knowledge and a list of sources. Domain knowledge includes a dictionary of entity names (conferences, universities, etc.), and dictionaries of equivalent names for entities (Robert/Rob/Bob; University of California, San Diego/UC San Diego/UCSD). Sources are the database community web pages where DBLife starts its crawl. The process of building the entity-relationship graph is performed by a series of modules that are organized into three layers: data page layer, mention layer, and entity layer.
The data page layer crawls the sources and saves local copies of the pages. It obtains metadata for each page, such as when it first appeared and when it last changed. Additionally, the data page layer detects structural elements in the pages, such as lists of names of people and conferences. The mention layer uses the dictionaries supplied by the domain expert to find mentions of those entities in the downloaded pages. Finally, the entity layer builds the entity-relationship graph. This series of modules is run daily. Both the mention layer and entity layer detect and track changes that occur between runs of DBLife. The entity-relationship graph is used by a web portal that displays news and information about the database community and provides information about the entities within the community. Screenshots of the web portal are shown in Figure 4.
We chose DBLife as an example program because DBLife uses a large, complex workflow that accesses many files. DBLife illustrates the types of questions that PAC can answer well, and types of provenance questions that PAC is not able to answer.
Examples of questions that PAC provides useful answers for are:
Examples of questions that PAC cannot answer are:
From these example questions we see that PAC is able to provide answers for the types of questions that developers and system administrators might ask about a run of DBLife. The types of questions that PAC cannot answer require knowledge about the semantics of the application. This result is not surprising because we know that PAC collects information about activities in the execution system, but does not collect information about the internal processes of the jobs that run in the system.
We measured the size of the FileTrace table for DBLife by executing a run of DBLife using 10 data sources (web crawl start points). This run produced a 100 megabyte FileTrace table. A full scale run of DBLife uses 1000 data sources. By scaling our test run up to full scale we obtain an estimated table size of 10 gigabytes. DBLife is scheduled to run on a daily basis so over the course of a year the FileTrace table would grow to 3.7 terabytes. This size borders on being too large for some users. We have not yet explored compressing the FileTrace table. It is likely that compression will result in a more manageable table size.
One result of a provenance system that is able to accommodate a wide range of applications is that it does not gather some of the details that are gathered by provenance systems that require certain behaviors from applications. But we observed that workflow management systems can use PAC to run the individual workflow nodes. The combination of PAC and a more targeted provenance system provides more provenance details than either system does on its own.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons -no_navigation -dir final_paper/html ReillyNaughton.tex
The translation was initiated by Christine Reilly on 2009-02-11