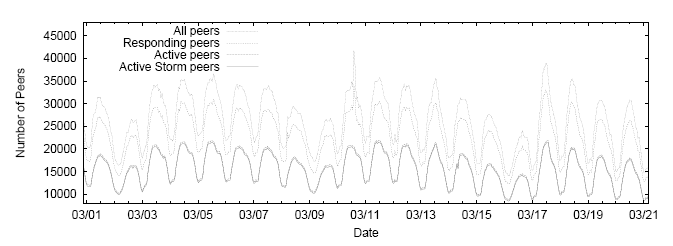
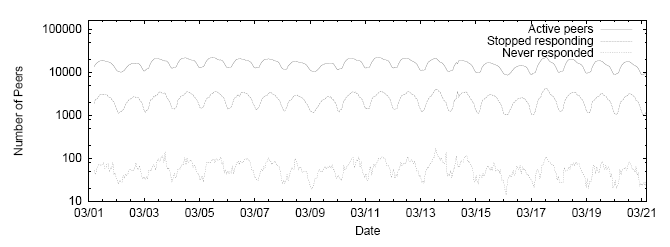
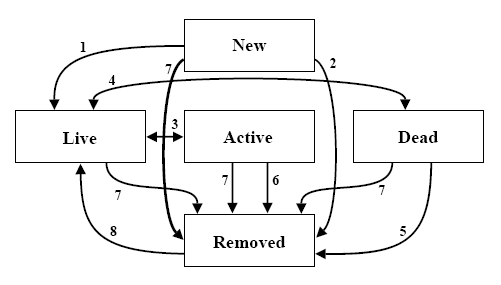
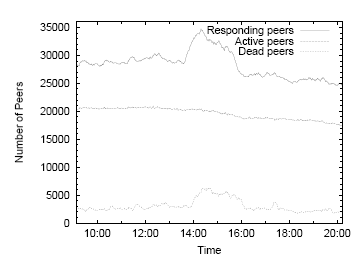
| Location | Hallmarks |
| Germany | Random OIDs with lower 10 bytes constant. Floods the Storm network aggressively with thousands of fake node IPs. |
| Iran | Random OIDs biased to upper half of space (first bit always set). |
| Sweden | Random OIDs biased to upper half of space (first bit always set). Does not appear in routing tables of any other peers. |
| France | One fixed OID, relatively passive crawler, appears to just be sampling Storm. |
| East Coast, US | 257 OIDs evenly distributed in ID space behind one IP, port number used as upper two bytes of the OID. |
| East Coast, US | Uniform random OIDs, both a Storm implementation and crawler behind the same IP, does not report other peers. |
| West Coast, US | Random OIDs biased to upper half of space 100:1. Does not report IPs in response to queries. |
|
|
Table 2:Other parties participating in the "encrypted" Storm
network on April 4, 2008.
|
|