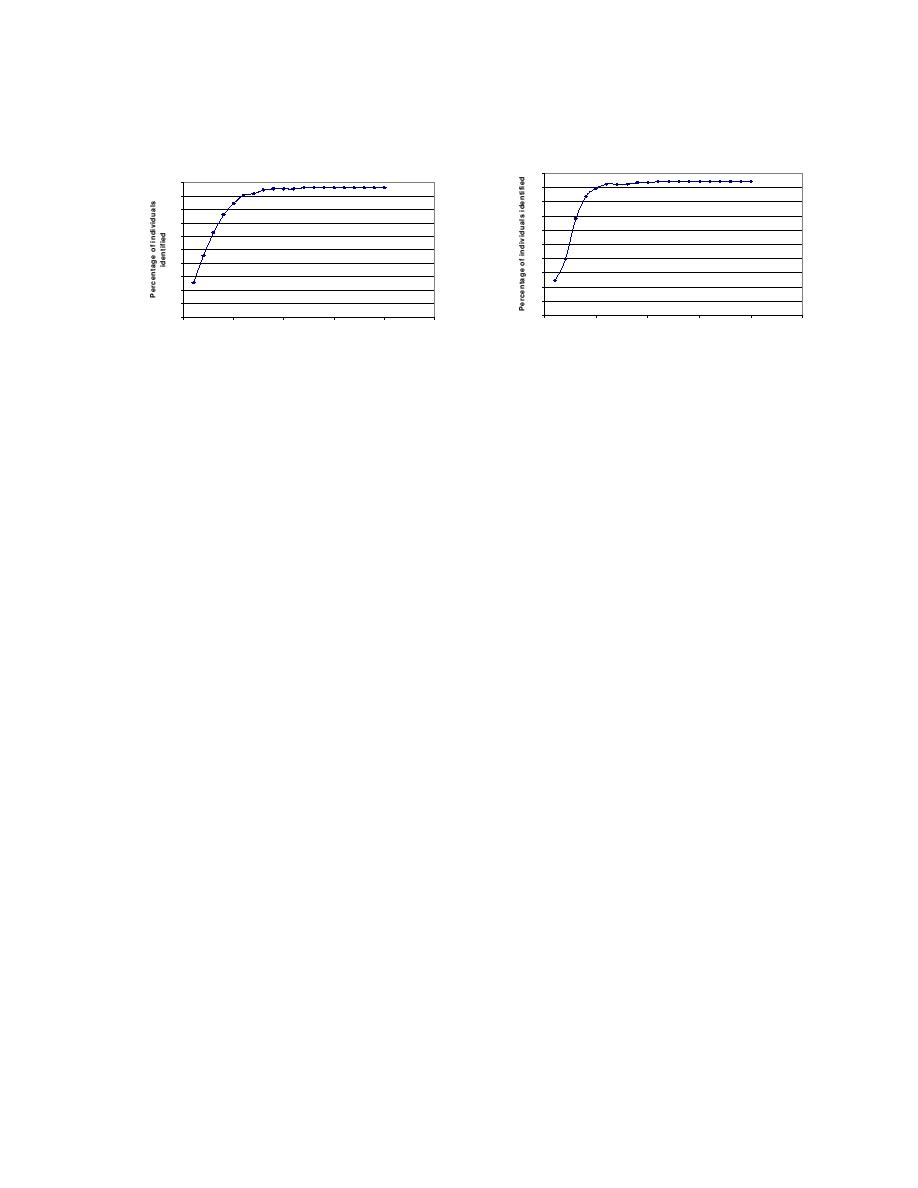
Identifiability of California individuals with Wikipedia
Identifiability of Illinois individuals with Wikipedia Biographies
biographies
100
100
90
90
80
80
70
70
60
60
50
50
40
40
30
30
20
20
10
10
0
0
0
5
10
15
20
25
0
5
10
15
20
25
Maximum number of keywords used to identify an individual
Maximum number of keywords used to identify an individual
Figure 1: Using 20 keywords per person, extracted from each resident's Wikipedia biography, the percentage of individuals who were identifiable
based on x keywords or less for x = 1, . . . , 20. The graph on the left shows results for the 234 biographies of California residents in Wikipedia
and the graph on the right shows the results for the 106 biographies of Illinois residents in Wikipedia.
returned by issuing query Qx to Google with the re-
the first page of hits returned by the query "nfl francisco
strictions that the hits consist solely of html or text6
pro". Hence, the association of O. J. Simpson with his
wife (Nicole) and his wife's boyfriend (Goldman) is very
and that no hits from the en.wikipedia.org Web site
useful to identifying him in the pool of professional foot-
be returned.
4. Let Hx,1, Hx,2, Hx,3 ∈ Hx be the first, second and
ball players who once were members of the San Fran-
third hits (respectively) resulting from query Qx.7
cisco 49ers.
For x = 20, 19, . . . , 1, determine if Hx,1, Hx,2 and
Hx,3 contain references to subject, N , by search-
ing for contiguous occurrences of N1, N1 and N2
PERFORMANCE. In our initial studies, there was wide
(meaning, no words appear in between the words in
variation, from a few minutes to over an hour, in the total
a name) within the first 5000 lines of html in each of
time it took to process a single biography, B, depending
Hx,1, Hx,2 and Hx,3. Record any such occurrences.
on the length of the Web pages returned and the num-
ber of hits. Hence, in order to efficiently process a suf-
Output: SB , each query Qx that contains N1, N1 and
ficiently large number of biographies we restricted the
N2 contiguously in at least one of the three examined
code to only examining the first 5000 lines of html in the
hits, and the url of the particular hit(s).
returned hits from a given query, and to only search the
first 3 hits returned from any given query. With these
We ran this test on the 234 biographies of California
restrictions, each biography took around 20 minutes to
residents, and the 106 biographies of Illinois residents
process, with some variation due to differences in biog-
contained in Wikipedia. The results for both states are
raphy length. In total, our California experiments took
shown in Figure 1 and are very similar. In each case, 10
around 78 hours and our Illinois experiments took about
or fewer keywords (extracted from the Wikipedia biog-
35 hours. Our experimental code does not keep track
raphy) suffice to identify almost all the individuals. Note
of the number of queries issued per registration and do-
that statistics in Figure 1 are based solely on the output
ing so may yield better performance because switch-
of the code, with no human review.
ing between registrations occurred only upon receiving
We also include example results (keywords, url, biog-
a Google SOAP error and so caused some delay.
raphy subject) in Figure 2. These results illustrate that
the associations a person has may be as useful for identi-
fying them as their personal attributes. To highlight one
Our code was not optimized for performance and im-
example from the figure, 50% of the first page of hits re-
provements are certainly possible. In particular, our main
slow down came from the text extraction step. One im-
turned from the Google query "nfl nicole goldman fran-
cisco pro" are about O. J. Simpson (including the top 3
provement would be to cache Web sites to avoid repeat
extractions.
hits), but there is no reference to O. J. Simpson in any of