| ||||||||||||||||||||||||||||||||||||||||||||||||||||
|
EESR '05 Paper
[EESR '05 Technical Program]
The Abstract Task Graph: A Methodology for Architecture-Independent Programming of Networked Sensor Systems1Amol Bakshi, Viktor K. Prasanna Department of Electrical Engineering
Jim Reich, Daniel Larner Palo Alto Research Center
AbstractThe Abstract Task Graph (ATaG) is a data driven programming model for end-to-end application development on networked sensor systems. An ATaG program is a system-level, architecture-independent specification of the application functionality. The application is modeled as a set of abstract tasks that represent types of information processing functions in the system, and a set of abstract data items that represent types of information exchanged between abstract tasks. Input and output relationships between abstract tasks and data items are explicitly indicated as channels. Each abstract task is associated with user-provided code that implements the actual information processing functions in the system. Appropriate numbers and types of tasks can then be instantiated at compile-time or run-time to match the actual hardware and network configuration, with each node incorporating the user-provided code, automatically generated glue code, and a runtime engine that manages all coordination and communication in the network. This paper primarily deals with the key concepts of ATaG and the program syntax and semantics. The end-to-end application development methodology is discussed briefly.
1 IntroductionWireless sensor networks allow embedded, dense monitoring of the physical environment. The challenge in programming a sensor network is to coordinate the sensing, collaborative processing, and data flow in the network correctly, so that the desired functionality is achieved, and efficiently, such that performance requirements are met and the network lifetime is maximized. The need to manage a large collection of autonomous sensor nodes poses challenges from a programming perspective. State of the art programming languages and methods for sensor networks require the end user to manually translate the global application behavior in terms of local actions at each node, which is likely to be time-consuming and error prone for complex applications. Also, the application-level logic is tightly interfaced with the part of the program that coordinates lower level services such as resource management, routing, localization, etc. This lack of separation between system-level code and application-level code results in high complexity of coding non-trivial system behaviors. There is a growing interest in macroprogramming of sensor networks [5,10] which means moving beyond node-centric programming and instead specifying aggregate behaviors which are then automatically translated by a compilation framework into node-level specifications. This is motivated by the realization that the end user will be a domain expert and not a computer scientist, and will be primarily interested in the monitoring and control of physical phenomena. The details of in-network computing and communication which provides the desired functionality will be of incidental interest in most scenarios. We introduce a macroprogramming model called the Abstract Task Graph (ATaG) that builds upon the core concepts of data driven computing and incorporates novel extensions for distributed sense-and-respond applications. The types of information processing functionalities in the system are modeled as a set of abstract tasks with well-defined input/output interfaces. User-provided code associated with each abstract task implements the actual processing in the system. An ATaG program is `abstract' because the number and placement of tasks and the control and coordination mechanisms are determined at compile-time and/or run-time depending on the characteristics of the target deployment.
ATaG enables a methodology for architecture-independent development of networked sensing applications. Architecture independence is the ability to specify application behavior for a generic, parameterized network architecture. The same application may be automatically synthesized for different network deployments, or adapted as nodes fail or are added to the system. Furthermore, it allows development of the application to proceed prior to decisions being made about the final configuration of the nodes and network. The focus of the ATaG approach is on simple specification of more complex patterns of information flow. A second objective is to define a process for automatically analyzing a user-supplied ATaG program and generating a deployment-specific distributed software system that consists of (a) the user-supplied application level code, and (b) a suitably customized runtime system responsible for control and coordination among the application level tasks. The present focus of our research is on defining the syntax and semantics of ATaG, and designing a runtime system and compiler for functionally correct translation of architecture-independent ATaG programs into architecture-specific node-level behaviors. Low level optimizations for a specific target platform have not yet been addressed.
Section 2 presents a sample ATaG program for an
environment monitoring scenario with a view to highlight the key ideas
before discussing them in more detail. Section 3
discusses the key concepts of ATaG and the structure and semantics of
ATaG programs. Details of the system level support for the ATaG model
can be found in [1]. A brief overview of the end-to-end
application development methodology is provided in
Section 4. We discuss related work in
Section 5 and conclude in Section 6.
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||
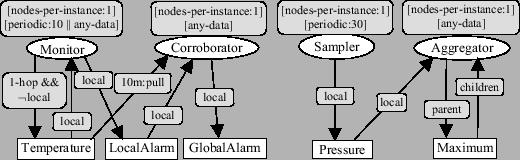
The two basic primitives available to the programmer are getData() and putData() for consuming and producing data items. The runtime system manages the data pool and moves data between producers and consumers. We now briefly summarize the semantics of ATaG.
If the task is periodic, it is scheduled for execution when the
periodic timer expires, regardless of the state of its input data
items. The per-task timer is set to zero each time the task begins
execution and is said to expire when the timer value becomes equal to
the task's period. If the task is any-data, it is
scheduled for execution as soon as a new instance of any of its input
data items is available. If the task is all-data, it is
scheduled for execution as soon as a new instance of each of its input
data items is available. Other valid firing rules are
periodic ![]() any-data and periodic
any-data and periodic ![]() all-data.
all-data.
Each well-behaved task must invoke exactly one getData() call for each of its input data items, and may invoke at most one putData() for each of its output data items. getData() is a destructive read from the task's perspective. Once a particular instance of a data item is read by a task, it is considered to be eliminated from the data pool as far as that task is concerned.
Task execution is atomic. Each application-level task will run to completion before another application-level task can begin execution. All members of the set of dependent tasks of a particular data item are executed before other tasks that might be dependent on the output data items of the tasks in this set are executed. Whenever the production of an instance of a data item results in one or more of its dependent tasks to become ready, those tasks will consume the same instance when they invoke a getData() on the input data item. This means that that particular instance that triggered the task will not be overwritten or removed from the data pool before every scheduled dependent task finishes execution. The implication of this is that putData() is not guaranteed to succeed if an instance of the abstract data item being produced cannot be overwritten. Such situations might arise if, for example, the rate of production of an abstract data item is greater than the rate of consumption. The application developer is responsible for checking for success or failure of putData().
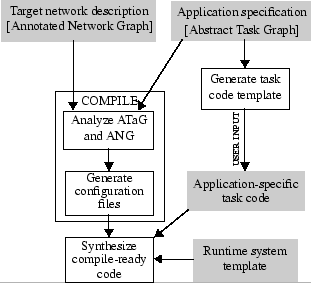
Figure 2 depicts the application development methodology using ATaG. The application developer graphically inputs the declarative part of the ATaG program and a description of the target deployment in the form of an annotated network graph (ANG), which is not discussed in this paper. The ANG contains information such as the number of nodes, the co-ordinates of each node, network connectivity, etc.
A code generator analyzes the ATaG program, determines the I/O dependencies between tasks and data objects, and generates code templates for the abstract tasks and data. The programmer populates the code templates with application functionality. The compiler then interprets the program annotations in the context of the ANG, and generates configuration files for each node that customize the behavior of that node based on its role in the system. Finally, compile-ready code is generated for each node in the network.
The graphical interface to the programming and synthesis environment is
through a configurable graphical tool suite called the Generic Modeling
Environment (GME) [4]. The declarative part of the ATaG
program which consists of the various declarations and their
annotations is specified visually. In fact, we exploit the
composability of ATaG and allow users to create libraries of ATaG
programs that can be simply concatenated to build larger applications.
GME stores the model defined by the user in a canonical format. Tools
called model interpreters can read from and write to this model
database. In our case, model interpreters were written for the
components represented by unshaded boxes in Fig. 2.
The core ideas of ATaG have been applied in different contexts in the distributed computing community. Modular, extensible, and convenient parallel programming was the motivation for the data driven paradigm in the Data Driven Graph [11] model. Separating the core application functionality from other concerns such as task placement and coordination was one of the primary motivations of efforts such as Distributed Oz [6] and IBM's PIMA project [2]. Tuple spaces [3,9] provides a content addressable persistent shared memory for coordination across distributed processes. Although the notion of a shared data store also exists in ATaG, our `active' data pool abstraction that schedules tasks based on the availability of data instances is fundamentally different from the `passive' tuple space whose modifications are really a side effect of task execution on different nodes.
TinyDB [7], Regiment [10], Kairos [5], and
Semantic Streams [12] are examples of macroprogramming
methodologies for sensor networks. While ATaG explores a mixed
imperative-declarative programming style and data-driven program flow,
TinyDB provides a declarative SQL-like query interface for sensor
data. Regiment is a demand-driven functional language based on
Haskell, with support for region-based aggregation, filtering, and
function mapping. Kairos is an imperative, control-driven programming
paradigm that provides a distributed shared memory abstraction to the
node level program. The Semantic Streams markup and declarative query
language, based on Prolog, is used to specify queries over semantic
information directly, while the actual selection, wiring, and
optimization of low level modules to implement the querying is
performed by a service composition framework.
We have presented a novel method for specifying sensor network programs based on the Abstract Task Graph. ATaG programs consist of two parts: a declarative section, which specifies the connectivity between tasks and constraints on their placement and communication; and an imperative section, with the implementation of the tasks written in a traditional computer language. In the current system, these tasks are instantiated on the nodes at compile-time, but in future work, we plan to investigate fully dynamic versions, instantiating tasks based on the current network hardware and connectivity and the underlying measurements. This will probably be restricted to the more capable hardware platforms. In any case, the declarative specification is fully portable to both other network architectures and other hardware architectures, requiring at most a porting of the individual task code, which represents only a small fraction of the system functionality.
This paper focused on the key concepts of ATaG and the
syntax and semantics of ATaG programs. We did not cover issues such
as the operational semantics of the compiler and synthesis system,
valid and invalid constructs in ATaG and opportunities for performance
optimization in the runtime. Finally, the set of annotations and the
synthesis and analysis tools available thus far are limited; for the
platform to achieve wider applicability, we expect to extend these
significantly in the future.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.71)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -show_section_numbers -local_icons eesr.tex
The translation was initiated by on 2005-05-05
|
This paper was originally published in the
Proceedings of the Workshop on End-to-End, Sense-and-Respond Systems, Applications, and Services,
June 5, 2005 Seattle, WA Last changed: 31 May 2005 aw |
|