 |
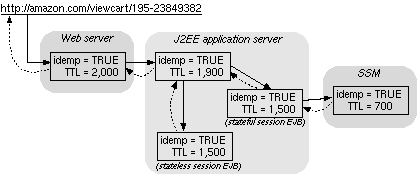
| Figure 1. A simple restart/retry architecture. |
In Figure 1 we show a simple
restart/retry example, in which a request to view a shopping cart
splits inside the application server into one subrequest to a stateful
session EJB (Enterprise JavaBean) that communicates with a session
state store and another subrequest to a stateless session EJB. Should
the state store become unavailable, the application server either
receives a
RetryAfter exception or times out, at which time it can decide
whether to resubmit the request to SSM or not. Within each of the
subsystems shown in Figure 1, we can
imagine each subrequest further splitting into finer grain subrequests
submitted to the respective subsystems' components. We have
implemented crash-restarting of EJBs in a J2EE application server; an
EJB-level micro-reboot takes less than a second [5].
Timeout-based failure detection is supplemented with traditional
heartbeats and progress counters. The counters---compact
representations of a component's processing progress---are usually
placed at state stores and in messaging facilities, where they can map
state access and messaging activity into per-component progress. Many
existing performance monitors can be transformed into progress
monitors by augmenting them with request origin information.
Components themselves can also implement progress counters that more
accurately reflect application semantics, but they are less
trustworthy, because they are inside the components.
The dynamics of loosely coupled systems can sometimes be
surprising. For example, resubmitting requests to a component that is
recovering can overload it and make it fail again; for this reason,
the RetryAfter exceptions provide an estimated time-to-recover.
This estimated value can be used to spread out request resubmissions,
by varying the reported time-to-recover estimate across different
requestors. A maximum limit on the number of retries is specified in
the application-global policy, along with the lease durations and
communication timeouts. These numbers can be dynamically estimated
based on historical information collected by a recovery
manager [5], or simply captured in a
static description of each component, similar to deployment
descriptors for EJBs. In the absence of such hints, a simple load
balancing algorithm or exponential backoff can be used.
To prevent reboot cycles and other unstable conditions during
recovery, it is possible to quiesce the system when a set of
components is being crash-rebooted. This can be done at the
communication/RPC layer, or for the system as a whole. In our
prototype, we use a stall proxy [5] in
front of the web tier to keep new requests from entering the system
during the recovery process. Since Internet workloads are typically
made of short running requests, the stall proxy transforms brief
system unavailability into temporarily higher latency for clients. We
are exploring modifications to the Java RMI layer that would allow
finer grain request stalling.
5. Discussion
Building crash-only systems is not easy; the key to widespread
adoption of our approach will require employing the right
architectural models and having the right tools. With the recent
success of component-based architectures (e.g., J2EE and .Net), and
the emergence of the application server as an operating system for
Internet applications, it is possible to provide many of the
crash-only properties in the platform itself. This would allow all
applications running on that platform to take advantage of the effort
and become crash-only.
We are applying the principles described here to an open-source Java 2
Enterprise Edition (J2EE) application server. We are separating the
individual J2EE services (naming, directory lookup, messaging, etc.)
into well-isolated components, implementing requests as
self-describing continuations, modifying the RMI layer to allow for
timeout-based operation, modifying the EJB containers to implement
lease-based resource allocation, and integrating non-transactional
state stores like DeStor and SSM. A first step in this direction is
described in [5].
We are focusing initially on applications whose workloads can be
characterized as relatively short-running tasks that frame state
updates. Substantially all Internet services fit this description, in
part because the nature of HTTP has forced designers into this mold.
As enterprise services and applications (e.g., workflow, customer
management) become web-enabled, they adopt similar architectures. We
expect there are many applications outside this domain that could not
easily be cast this way, and for which deriving a crash-only design
would be impractical or infeasible.
In order for the restart/retry architecture to be highly available
and correct, most requests it serves must be idempotent. This
requirement might be inappropriate for some applications. Our
proposal does not handle Byzantine failures or data errors, but such
behavior can be turned into fail-stop behavior using well-known
orthogonal mechanisms, such as triple modular redundancy [13] or clever state replication [6].
In today's Internet systems, fast recovery is obtained by
overprovisioning and counting on rapid failure detection to trigger
failover. Such failover can sometimes successfully mask hours-long
recovery times, but often detecting failures end-to-end takes longer
than expected. Crash-only software is complementary to this approach
and can help alleviate some of the complex and expensive management
requirements for highly redundant hardware, because faster recovering
software means less redundancy is required. In addition, a crash-only
system can reintegrate recovered components faster, as well as better
accommodate removed, added, or upgraded components.
We expect throughput to suffer in crash-only systems, but this concern
is secondary to the high availability and predictability we expect in
exchange. The first program written in a high-level language was
certainly slower than its hand-coded assembly counterpart, yet it set
the stage for software of a scale, functionality and robustness that
had previously been unthinkable. These benefits drove compiler
writers to significantly optimize the performance of programs written
in high-level languages, making it hard to imagine today how we could
program otherwise. We expect the benefits of crash-only software to
similarly drive efforts that will erase, over time, the potential
performance loss of such designs.
6. Conclusion
By using a crash-only approach to building software, we expect to
obtain better reliability and higher availability in Internet systems.
Application fault models can be simplified through the application of
externally-enforced ``crash-only laws,'' thus encouraging simpler
recovery routines which have higher chances of being correct. Writing
crash-only components may be harder, but their simple failure behavior
can make the assembly of such components into large systems easier.
The promise of a simple fault model makes stating invariants on
failure behavior possible. A system whose component-level and
system-level invariants can be enforced through crash-rebooting is
more predictable, making recovery management more robust. It is our
belief that applications and services with high availability
requirements can significantly benefit from these properties.
Once we surround a crash-only system with a suitable recovery
infrastructure, we obtain a recursively restartable system [4]. Transparent recovery based on
component-level micro-reboots enables restart/retry architectures to
hide intra-system failure from the end users, thus improving the
perceived reliability of the service. We find it encouraging that our
initial prototype [5] was able to
complete 78% more client requests under faultload than a
non-crash-only version of the system that did not employ micro-reboots
for recovery.
References
